Hibernate
Hibernate 使用笔记
Hibernate 3.2 中文文档 http://static.kancloud.cn/wizardforcel/java-opensource-doc/112234
Hibernate 对象状态
Chapter 11. Working with objects https://docs.jboss.org/hibernate/core/3.6/reference/en-US/html/objectstate.html
第 11 章 与对象共事 http://itmyhome.com/hibernate/objectstate.html
Hibernate 对象三种状态
Hibernate 对象有三种状态:
- Transient 临时态/瞬时态
- Persistent 持久态
- Detached 游离态/脱管态
| 对象状态 | 是否处于Session缓存中 | 数据库中是否有对应记录 | 是否有主键ID |
|---|---|---|---|
| Transient 临时态 | × | × | × |
| Persistent 持久态 | √ | √ | √ |
| Detached 游离态 | × | √ | √ |
Transient 临时态/瞬时态
Transient 临时态/瞬时态,指从对象通过 new 语句创建到被持久化之前的状态,此时对象不在 Session 的缓存中,不与任何 Session 实例相关联,在数据库中没有与之对应的记录,主键 id 为 null。
如何获得临时态对象? 1、通过new语句创建新对象。 2、执行对象的 delete() 方法,对于游离状态的对象,delete() 方法会将其与数据库中对应的记录删除;而对于持久化状态的对象,delete() 方法会将其与数据库中对应的记录删除并将其在 Session 缓存中删除。
Persistent 持久态
Persistent 持久态,是指从 对象被持久化 到 Session 对象被销毁 之前的状态,此时对象在 Session 的缓存中,与 Session 实例相关联,在数据库中有与之对应的记录,主键 id 不为 null。
注意:Session 在清理缓存的时候,会根据持久化对象的属性变化更新数据库
如何获得持久态对象? 1、临时对象调用 save() 或 update() 等持久化方法后会变为持久态对象。 2、执行 load(), findOne() 或 findAll() 等查询方法返回的都是持久态对象。
Detached 游离态/脱管态
Detached 游离态/脱管态,是指从 持久化对象的Session对象被销毁 到 该对象消失 之前的状态,此时对象不在 Session 的缓存中,不与任何 Session 实例相关联,但在数据库中有与之对应的记录,id 不为 null。
如何获得游离态对象? 1、调用 close/clear 方法清理 session 中的缓存对象,则所有的缓存对象都会变为游离态。 2、调用 session.evict() 方法,从缓存中删除一个持久态对象,则此对象变为游离态。
脱管(Detached)对象如果重新关联到某个新的 Session 上, 会再次转变为持久(Persistent)的(在Detached其间的改动将被持久化到数据库)。
如何判断一个Hibernate对象的状态?
可通过 session 中是否包含 entity session.contains(entity) 方法判断对象是否持久态,在 session 中就是持久态。
对于非持久态对象,可通过是否有主键id判断是否游离态,无id的是临时态,有id的是游离态。
另外,SessionImpl.contains() 内有 persistenceContext.getEntry(object).getStatus() 获取对象状态(MANAGED,READ_ONLY,DELETED,GONE,LOADING,SAVING),但外部无法访问。
Hibernate 对象状态转换图
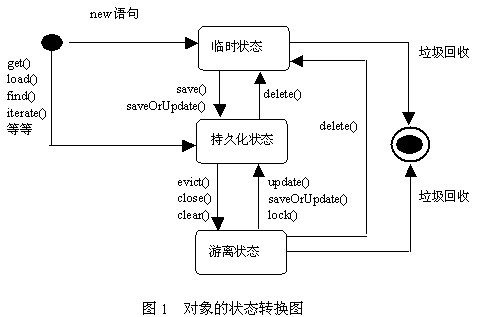
Hibernate 对象状态转换图
Hibernate 对象状态与操作示例
save() 之后对象就有主键ID
例1、持久化对象上的更新操作在事务提交/flush()后会被更新到数据库
@Test
public void testExample1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = new UserDO(); // new 对象时临时态
userDO.setName("小明");
session.save(userDO); // save 后变为持久态,id被填充
userDO.setName("李华");
session.getTransaction().commit(); // 事务结束时,持久化对象的属性变化会被自动更新到数据库
}
注意: (1)执行完save后还未到事务提交,就会触发insert sql,实体也就有了id(由于事务还未提交,在其他Session中看不到这个数据)
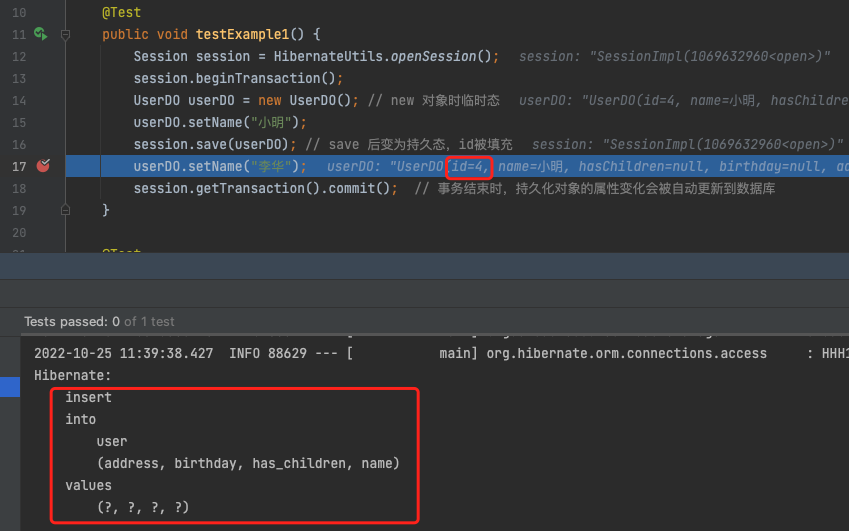
save之后实体就有了ID
(2)最后一次在持久化对象上 setName 更新后,虽然没有执行 save 操作,但事务结束 commit 时也会将更新保存到数据库,事务提交时会发出一条更新sql,总共发出两条sql:
Hibernate:
insert
into
user
(address, birthday, has_children, name)
values
(?, ?, ?, ?)
Hibernate:
update
user
set
address=?,
birthday=?,
has_children=?,
name=?
where
id=?
多次更新只最后提交时发出sql
例2、持久态对象在事务提交前,无论显示执行多少次 save/update 操作,hibernate 都不会发送 sql 语句,只有当事物提交/flush()的时候 hibernate 才会拿当前这个对象与之前保存在session 中的持久化对象进行比较,如果不相同就发送一条 update 的 sql 语句,否则就不会发送 update 语句
@Test
public void testExample2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = new UserDO(); // new 对象是临时态
userDO.setName("小明");
session.save(userDO); // save 后变为持久态
userDO.setName("李华");
session.save(userDO); // 不会立即执行 insert 语句
userDO.setAddress("北京市");
session.update(userDO);
session.getTransaction().commit(); // 事务结束时发出 insert 和 update 两条语句
}
第一个 save() 执行完会发出 insert sql,然后后面的 save 和 update 都不会再发出sql,直到最后事务提交时会发出一条 update sql,总共两条sql:
Hibernate:
insert
into
user
(address, birthday, has_children, name, id)
values
(?, ?, ?, ?, ?)
Hibernate:
update
user
set
address=?,
birthday=?,
has_children=?,
name=?
where
id=?
事务提交后持久态对象的修改自动更新到数据库
例3、
@Test
public void testExample3() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = session.get(UserDO.class, 1L); // 查询出来的是持久态对象
System.out.println(userDO);
userDO.setName("姓名改");
session.getTransaction().commit(); // 最后提交事务时对持久态对象的修改会被更新到数据库
}
之前一段类似下面的代码,忘了写 save() 语句,但发现还是成功更新了user的name,不知道为什么
public void updateUser(req) {
UserDO user = jpaRepository.findOne(1L);
user.setName(req.getName());
}
事务结束时,Hibernate 会自动保存更新了的 DO,在了解 Hibernate 对象状态前不知道为什么,查问题才查到 Hibernate 对象状态相关信息。
https://stackoverflow.com/questions/12859305/hibernate-how-to-disable-automatic-saving-of-dirty-objects https://stackoverflow.com/questions/8190926/transactional-saves-without-calling-update-method
游离态对象
例4、游离态对象
@Test
public void testExample4() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = session.get(UserDO.class, 1L); // 查询出来的是持久态对象
System.out.println(userDO);
session.clear(); // 清空 session,user变为游离态
userDO.setName("姓名改");
System.out.println("Entity在当前Session中:" + session.contains(userDO));
session.getTransaction().commit(); // 提交事务时无需更新
}
调用 session.clear() 方法会将 session 的缓存对象清空,那么 session 中就没有了 user 这个对象,这个时候在提交事务的时候,发现 session 中已经没有该对象了,所以就不会进行任何操作,对象的修改也不会更新到数据库。 session.contains(userDO) 返回 false,游离态对象不在 session 中。
持久态对象无法修改ID
例5、如果试图修改一个持久化对象的ID值的话,就会抛出异常 javax.persistence.PersistenceException: org.hibernate.HibernateException: identifier of an instance of com.masikkk.common.jpa.UserDO was altered from 1 to 22
@Test
public void testExample5() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = session.get(UserDO.class, 1L); // 查询出来的是持久态对象
System.out.println(userDO);
userDO.setId(22L); // 运行时会抛异常
session.getTransaction().commit();
}
https://www.cnblogs.com/xiaoluo501395377/p/3380270.html https://www.baeldung.com/hibernate-session-object-states
Hibernate 缓存
一级缓存(Session级缓存)
一级缓存的生命周期和 Session 一致,也称为 Session 级缓存,或者事务级缓存。 一级缓存时默认开启的,不可关闭。
查询:当在同一个 Session 中查询同一个对象时,Hibernate 不会再次与数据库交互,直接从 Session 缓存中取。 更新:save/update 更新对象时,Hibernate 不会立即发出 SQL 将这个数据存到数据库,而是将它放在了 Session 的一级缓存中,直到调用 flush() 或提交事务时才会一并存到数据库。
例1、下面两次根据ID查询user,只会执行一次select语句,第二次会从 Session 缓存中获取
@Test
public void testSessionCache1() {
Session session = HibernateUtils.openSession();
System.out.println(session.get(UserDO.class, 1L));
System.out.println(session.get(UserDO.class, 1L)); // 有缓存,只执行一次查询
}
例2、HQL 查询不使用 Session 缓存
@Test
public void testSessionCache2() {
Session session = HibernateUtils.openSession();
System.out.println(session.get(UserDO.class, 1L));
// HQL 查询不走缓存,还是会执行sql
Query idQuery = session.createQuery("from UserDO where id = :id");
idQuery.setParameter("id", 1L);
List<UserDO> userDOList = idQuery.list();
userDOList.forEach(System.out::println);
// 再执行一次 HQL 查询还是不走缓存,会再执行一次sql
userDOList = idQuery.list();
}
例3、虽然 HQL 查询不走缓存,但是会将数据放入Session缓存,第二次根据id get查询直接从缓存取
@Test
public void testSessionCache3() {
Session session = HibernateUtils.openSession();
Query nameQuery = session.createQuery("from UserDO where name = :n");
nameQuery.setParameter("n", "李华6");
List<UserDO> userDOList = nameQuery.list();
userDOList.forEach(System.out::println);
// 虽然 HQL 查询不走缓存,但是会将数据放入Session缓存,第二次根据id get查询直接从缓存取
System.out.println(session.get(UserDO.class, 6L));
}
二级缓存(应用级缓存)
二级缓存是全局性的,可以在多个 Session 中共享数据,二级缓存称为是 SessionFactory 级缓存,或应用级缓存。
二级缓存默认没有开启,需要手动配置缓存实现(EhCache等)才可以使用。开启二级缓存后,根据id查询数据时,会先在一级缓存查询,没有再去二级缓存,还没有再去数据库查。
在 Spring Data 中可通过 javax.persistence.Cacheable 等注解使用。
注意:一级缓存和二级缓存都是只在根据 ID 查询对象时起作用,并不对全部查询生效。
例1、默认二级缓存是不开启的,两个Session分别查id=1的数据,会执行两次sql
@Test
public void testSecondLevelCache() {
Session session1 = HibernateUtils.openSession();
System.out.println(session1.get(UserDO.class, 1L));
Session session2 = HibernateUtils.openSession();
System.out.println(session2.get(UserDO.class, 1L));
}
开启二级缓存
1、打开二级缓存开关,测试过程中发现 use_second_level_cache 开关默认是开启的
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.region.factory_class"> org.hibernate.cache.ehcache.internal.EhCacheRegionFactory</property>
或在 properties 文件中配置:
hibernate.cache.use_second_level_cache=true
hibernate.cache.region.factory_class=org.hibernate.cache.ehcache.EhCacheRegionFactory
或者在 Spring-Boot yml 配置:
spring:
jpa:
properties:
hibernate:
cache:
use_second_level_cache: true
region:
factory_class: org.hibernate.cache.jcache.JCacheRegionFactory
provider_configuration_file_resource_path: ehcache.xml
2、二级缓存需要在各个实体上单独开启,注解需要二级缓存的实体
import javax.persistence.Cacheable;
import org.hibernate.annotations.CacheConcurrencyStrategy;
@Entity
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Foo {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "ID")
private long id;
}
缓存并发策略
READ_ONLY 只适用于只读的实体/表
NONSTRICT_READ_WRITE 事务提交后会更新缓存,非强一致性,可能读到脏数据,适用于可容忍一定非一致性的数据。
READ_WRITE 保证强一致性,缓存实体被更新时会加一个软锁,更新提交后软锁释放。访问加了软锁的缓存实体的并发请求会直接从数据库取数据。
TRANSACTIONAL 缓存与数据库数据之间加 XA 分布式事务,保证两者数据一致性。
Hibernate Second-Level Cache https://www.baeldung.com/hibernate-second-level-cache
查询(Query)缓存
Hibernate 的一、二级缓存都是根据对象 id 来查找时才起作用,如果需要缓存任意查询条件,就需要用到查询缓存。
Hibernate 配置开启 query 缓存
<property name="hibernate.cache.use_query_cache">true</property>
使用 Spring-Data-Jpa 时可在 application.yml 中配置开启
spring:
jpa:
properties:
hibernate:
cache:
use_query_cache: true
Session
save()/persist() 区别
persist() 把一个瞬态的实例持久化,但是并"不保证"标识符(identifier主键对应的属性)被立刻填入到持久化实例中,标识符的填入可能被推迟到 flush() 的时候。 save() 把一个瞬态的实例持久化,保证立即返回一个标识符。如果需要运行 INSERT 来获取标识符(如 "identity" 而非 "sequence" 生成器),这个 INSERT 将立即执行,即使事务还未提交。 经测试,主键生成策略是 IDENTITY 的实体,在 MySQL 上测试,发现 persist/save 都会立即执行 insert 语句(事务还未提交),然后实体都具有了主键 id。
对象id不为 null 时,persist() 方法会抛出 PersistenceException 异常 javax.persistence.PersistenceException: org.hibernate.PersistentObjectException: detached entity passed to persist: com.masikkk.common.jpa.UserDO
@Test
public void testPersistWithId() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = new UserDO();
userDO.setId(20L);
userDO.setName("persist持久化带id");
Exception e = Assertions.assertThrows(PersistenceException.class, () -> session.persist(userDO));
System.out.println(e);
session.getTransaction().commit();
}
对象id不为 null 时,save() 方法会忽略id,当做一个新对象正常保存
@Test
public void testSaveWithId() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
UserDO userDO = new UserDO();
userDO.setId(20L);
userDO.setName("save持久化带id");
session.save(userDO);
session.getTransaction().commit();
}
上面的 user id 被设为 20,但 save 之后可以看到 id 是 14。
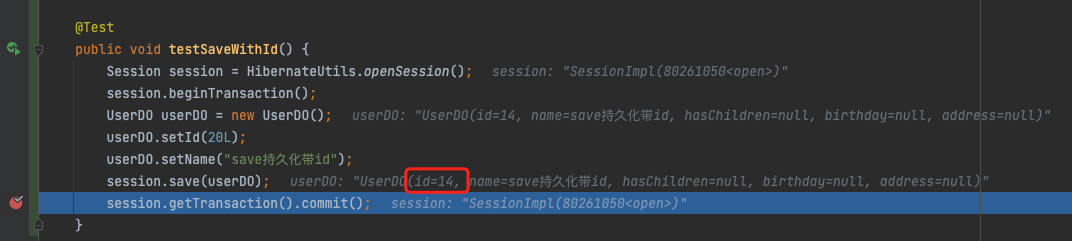
save带id的实体
get()/load() 区别
get/load 都可以根据主键 id 从数据库中加载一个持久化对象。 get/load 都会先从一级缓存中取,如果没有,get 会立即向数据库发请求,而 load 会返回一个代理对象,直到用户真的去使用数据,才会向数据库发请求,即 load 方法支持延迟加载策略,而 get 不支持
当数据库中不存在与 id 对应的记录时, load() 方法抛出 ObjectNotFoundException 异常, 而 get() 方法返回 null
@Test
public void testGetNotExistId() {
Session session = HibernateUtils.openSession();
UserDO userDO = session.get(UserDO.class, 1000L);
System.out.println(userDO);
Assertions.assertNull(userDO);
}
@Test
public void testLoadNotExistId() {
Session session = HibernateUtils.openSession();
UserDO userDO = session.load(UserDO.class, 2020L); // 此时不会抛异常
System.out.println(userDO); // 使用userDO时才真正去获取,才抛异常
}
load() 是延迟加载的,session.load() 虽然查不到但不会立即抛异常,之后在真正使用 userDO 实体时才去查询并抛异常,如果之后一直不使用 userDO 就一直不抛异常 org.hibernate.ObjectNotFoundException: No row with the given identifier exists: [com.masikkk.common.jpa.UserDO#1000]
Hibernate 配置
hibernate.hbm2ddl.auto 自动建表
hibernate.hbm2ddl.auto 参数的作用主要用于:自动创建,更新,验证数据库表结构。
在 SpringBoot 中的配置项是 spring.jpa.properties.hibernate.hbm2ddl.auto
有几种配置:
update 最常用的属性值,第一次加载 Hibernate 时创建数据表(前提是需要先有数据库),以后加载 Hibernate 时不会删除上一次生成的表,会根据实体更新,只新增字段,不会删除字段(即使实体中已经删除)。
validate 每次加载 Hibernate 时都会验证数据表结构,只会和已经存在的数据表进行比较,根据 model 修改表结构,但不会创建新表。
create 每次加载 Hibernate 时都会删除上一次生成的表(包括数据),然后重新生成新表,即使两次没有任何修改也会这样执行。适用于每次执行单测前清空数据库的场景。
create-drop 每次加载 Hibernate 时都会生成表,但当 SessionFactory 关闭时,所生成的表将自动删除。
none 不执行任何操作。将不会生成架构。适用于只读库。
不配置此项,表示禁用自动建表功能
hibernate.dialect SQL方言
hibernate.dialect SQL 方言
在 SpringBoot 中的配置项是 spring.jpa.database-platform
Hibernate 5.2.8 之后 MySQLDialect DDL 默认使用 MyISAM 引擎
The MySQL Dialect refactoring https://in.relation.to/2017/02/20/mysql-dialect-refactoring/
Hibernate 5.2.8 开始重构了 MySQL 的 方言(Dialect) 枚举,
MySQL55Dialect 之前的方言,包括 MySQLDialect,默认使用 MyISAM 引擎。从 MySQL55Dialect 开始,默认使用 InnoDB 引擎。
之前使用 MySQLInnoDBDialect 方言,可以改为 MySQLDialect 加 hibernate.dialect.storage_engine=innodb
之前使用 MySQL5InnoDBDialect 方言,可以改为 MySQL5Dialect 加 hibernate.dialect.storage_engine=innodb
Hibernate: Create Mysql InnoDB tables instead of MyISAM https://stackoverflow.com/questions/1459265/hibernate-create-mysql-innodb-tables-instead-of-myisam
globally_quoted_identifiers 标识符加反引号
将 SQL 中的标识符(表名,列名等)全部用 反引号(MySQL) 括起来,可解决表名、列名和 MySQL 标识符冲突的问题。
spring.jpa.properties.hibernate.globally_quoted_identifiers=true
其实是根据 spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect 配置的具体 SQL 方言来决定用什么符号将标识符括起来,比如 MySQL 中是反引号,达梦dameng、人大金仓kingbase数据库中是双引号
Hibernate命名策略
Hibernate隐式命名策略和物理命名策略
hibernate 5.1 之前,命名策略通过 NamingStrategy 接口实现,但是 5.1 之后该接口已废弃。
hibernate 5.1 之后,命名策略通过 隐式命名策略 接口 ImplicitNameSource 和 物理命名策略 接口 PhysicalNamingStrategy 共同作用实现。
在 Spring 中使用时通过下面两个步骤来确定:
第一步:如果我们没有使用 @Table 或 @Column 指定了表或字段的名称,则由 SpringImplicitNamingStrategy 为我们隐式处理,表名隐式处理为类名,列名隐式处理为字段名。如果指定了表名列名,SpringImplicitNamingStrategy 不起作用。
第二步:将上面处理过的逻辑名称解析成物理名称。无论在实体中是否显示指定表名列名 SpringPhysicalNamingStrategy 都会被调用。
JPA大写表名自动转换为小写提示表不存在
有个全大写的表名 MYTABLE, 实体类如下,通过 @Table 注解的 name 属性指定了大写的表名
@Data
@Entity
@Table(name = "MYTABLE")
public class MYTABLEDO {
...
}
运行报错,提示找不到小写的表名 com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'mydb.mytable' doesn't exist 貌似 jpa 的默认表命名策略是都转为小写表名。
原因: spring data jpa 是基于 hibernate 5.0 , 而 Hibernate 5 关于数据库命名策略的配置与之前版本略有不同: 不再支持早期的 hibernate.ejb.naming_strategy,而是改为两个配置项分别控制命名策略: hibernate.physical_naming_strategy hibernate.implicit_naming_strategy 在 spring 中的配置项是
spring.jpa.hibernate.naming.implicit-strategy=org.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
implicit-strategy 负责模型对象层次的处理,将对象模型处理为逻辑名称 physical-strategy 负责映射成真实的数据名称的处理,将上述的逻辑名称处理为物理名称。 当没有使用 @Table 和 @Column 注解时,implicit-strategy 配置项才会被使用,当对象模型中已经指定 @Table 和 @Column 时,implicit-strategy 并不会起作用。 physical-strategy 一定会被应用,与对象模型中是否显式地指定列名或者已经被隐式决定无关。
physical-strategy 策略常用的两个实现有
org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy 这个是 Spring data jpa 的默认数据库命名策略。
org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
解决方法一:
可以在 springboot 项目中配置文件内加上配置行,设置命名为 无修改命名策略:
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
解决方法二: 1 重写命名策略中改表名为小写的方法:
import org.hibernate.boot.model.naming.Identifier;
import org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl;
import org.hibernate.engine.jdbc.env.spi.JdbcEnvironment;
/**
* 重写 hibernate 对于命名策略中改表名大写为小写的方法
*/
public class MySQLUpperCaseStrategy extends PhysicalNamingStrategyStandardImpl {
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment context) {
String tableName = name.getText().toUpperCase();
return name.toIdentifier(tableName);
}
}
2 在对应配置文件中 使用自己实现的策略
spring.jpa.hibernate.naming.physical-strategy=com.xxx.xxx.util.MySQLUpperCaseStrategy
解决 springboot + JPA + MySQL 表名全大写 出现 “表不存在” 问题(Table 'XXX.xxx' doesn't exist) https://blog.csdn.net/jiangyu1013/article/details/80409082
当JPA遇上MySQL表名全大写+全小写+驼峰+匈牙利四风格 https://blog.51cto.com/yerikyu/2440787
JPA实现根据SpringBoot命令行参数动态设置表名
背景:
使用 JPA 操作的一个表名经常变化(表结构不变)的表,每过一段时间就做一次数据升级,升级时表名会变,但表结构不变,使用 @Table(name = "xxx") 注解实体 bean 来做映射。
表名变化后可以改配置参数重启,但尽量不要改代码,因为改代码还得重新发包。
有如下几种方案:
1 JPA 中通过 @Query 手动拼 sql,这样不仅不需要重启,利用配置项字典表还能运行中动态改表名。但不想这样做,都使用 JPA 了还手动拼sql,太麻烦。
2 Hibernate 拦截器改表名,只是偶然搜到了能这么做,没实现过。
Hibernate 拦截器的使用--动态表名
https://my.oschina.net/cloudcross/blog/831277
3 自定义物理命名策略 SpringPhysicalNamingStrategy,在其中读取配置项,修改指定的表名,参考下面这篇文章。
我完全照着这篇文章实现的话,总是无法成功,每次运行到 toPhysicalTableName() 方法时,之前注入的 parser 就变为 null 了,后来仔细看了看,发现被 ApplicationContextAware 回调的,和运行 toPhysicalTableName() 方法的,是两个不同的 MySpringPhysicalNamingStrategy 实例,导致无法读取配置。
Spring Data JPA自定义实现动态表名映射
https://blog.csdn.net/u014229347/article/details/88892559
最后改了改实现,简化为在命令行参数中 -Dtable.name=xxx 配置表名,在自定义命名策略中直接 System.getProperty("table.name") 读取命令行参数。
完整步骤: 1 自定义物理命名策略
@Slf4j
@Component
public class ConfigurableNamingStrategy extends SpringPhysicalNamingStrategy {
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment jdbcEnvironment) {
if (StringUtils.equals(name.getText(), "table_name_placeholder")) {
String tableName = System.getProperty("table.name");
log.info("新表名: {}", tableName);
return Identifier.toIdentifier(tableName);
} else {
// 其他表不变
return super.toPhysicalTableName(name, jdbcEnvironment);
}
}
}
2 实体上直接注解为假的表名占位符
@Data
@Entity
@Table(name = "table_name_placeholder")
public class MyDO {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY, generator = "JDBC")
private Long id;
}
3 Spring 配置文件中设置自定义命名策略
spring.jpa.hibernate.naming.physical-strategy=com.masikkk.persistence.config.ConfigurableNamingStrategy
4 SpringBoot 启动参数中添加表名配置项
nohup java -jar -Dtable.name=xxx myapp.jar &
注意,这种 -D System 参数必须放在 myapp.jar 之前才能被 System.getProperty() 读取到
Hibernate 自定义表名映射 https://segmentfault.com/a/1190000015305191