面试准备02-Java集合框架
Java Collections Framework (JCF) Java面试准备笔记
Java集合框架概述
在集合框架的类继承体系中,最顶层有两个接口:
- Collection表示一组纯数据
- Map表示一组key-value对
关系图如下:
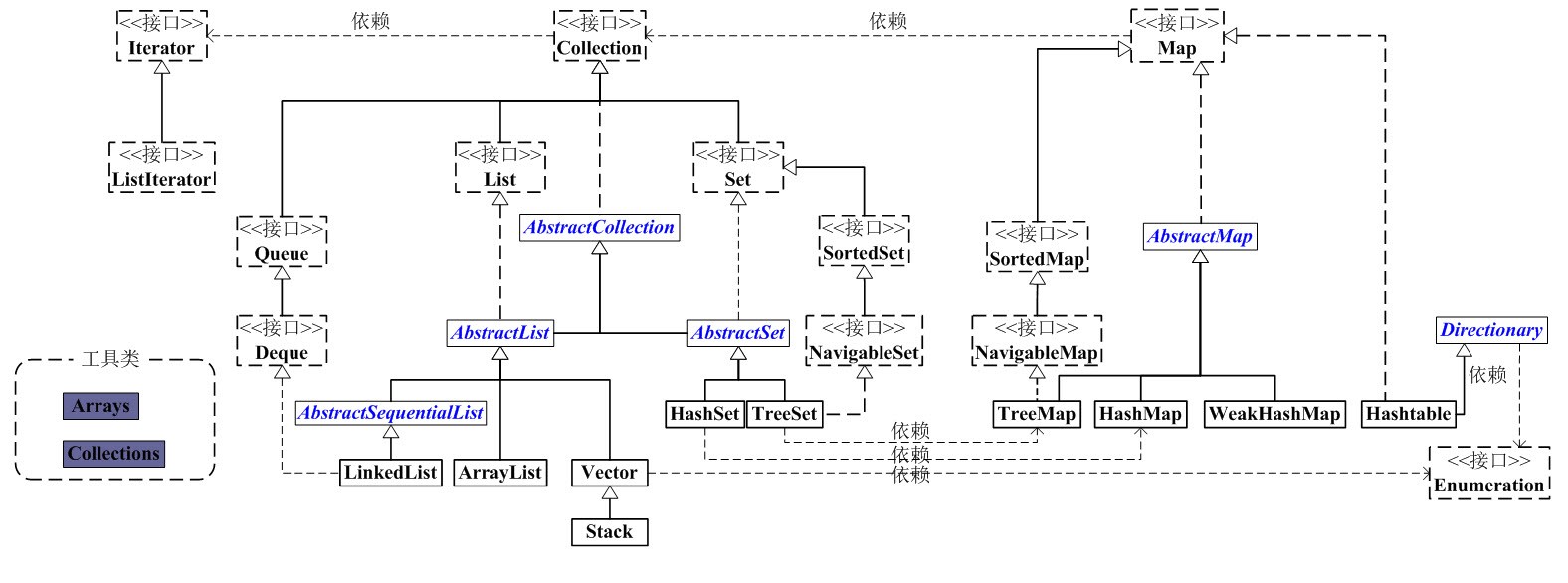
Java集合框架关系图
Collection
|-----List 有序(存储顺序和取出顺序一致),可重复
|----ArrayList 线程不安全,底层使用数组实现,查询快,增删慢。效率高。
|----LinkedList 线程不安全,底层用双向链表实现,查询慢,增删快。效率高。
|----Vector 线程安全,底层使用数组实现,查询快,增删慢。效率低。
|----Stack 先进后出栈。基本的push和pop方法,还有peek方法得到栈顶的元素
|-----Set 元素不可重复,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
|--HashSet 底层是由HashMap实现的,通过对象的hashCode方法与equals方法来保证插入元素的唯一性,无序(存储顺序和取出顺序不一致)。
|--LinkedHashSet 底层数据结构由哈希表和链表组成。哈希表保证元素的唯一性,链表保证元素有序。(存储和取出是一致)
|--TreeSet 基于TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序。
|-----Queue FIFO 队列接口
|--Deque 双端队列接口,可当做 FIFO 队列用,也可当做 LIFO 栈用,LinkedList 实现了 Deque
|--PriorityQueue 优先队列(堆/大顶堆/小顶堆)
Map
|-----HashMap 数组+链表实现,非线程同步,初始桶数量为16,loadfactor为0.75,
|-----LinkedHashMap 非同步。保留插入的顺序。维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
|-----TreeMap 非同步。基于红黑树实现。 根据key值对k-v对排序,支持自然排序、定制排序,取决于使用的构造方法。
|-----Hashtable 线程同步的。key,value都不能为null
Collection 接口
Collection接口主要有三个子接口:
- Set,表示不允许有重复元素的集合(A collection that contains no duplicate elements)
- List,表示允许有重复元素的集合(An ordered collection (also known as a sequence))
- Queue,JDK1.5新增,与上面两个集合类主要是的区分在于Queue主要用于存储数据,而不是处理数据。(A collection designed for holding elements prior to processing.)
简图如下:
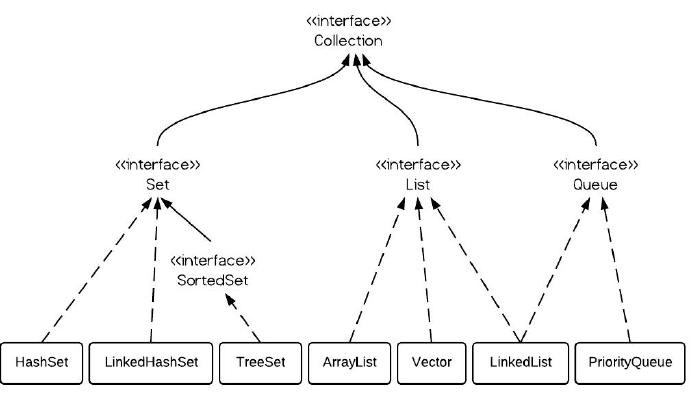
Collection接口
随笔分类 - Java集合 http://www.cnblogs.com/xiaoxi/category/929860.html
Java集合框架综述 http://www.importnew.com/16658.html
List 接口
有序,元素可重复的集合。
ArrayList
动态数组,允许任何符合规则的元素插入甚至包括null 初始容量为10,自动扩容,可指定初始容量 每次容量不足时,自增长度的一半,如下源码可知 int newCapacity = oldCapacity + (oldCapacity >> 1);
ArrayList擅长于随机访问。同时ArrayList是非同步的。
ArrayList的自动扩容机制(1.5倍)
java自动增加ArrayList大小的思路是:向ArrayList添加对象时,原对象数目加1如果大于原底层数组长度,则以适当长度新 建一个原数组的拷贝,并修改原数组,指向这个新建数组。原数组自动抛弃(java垃圾回收机制会自动回收)。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
ArrayList如何序列化
通过对 ArrayList 源码的分析,可以知道 ArrayList 的数据存储都是依赖于 elementData 数组,它的声明为:
transient Object[] elementData;
注意 transient 修饰着 elementData 这个数组,表示 ArrayList 在序列化的时候,默认不会序列化这些数组元素。
那么 ArrayList 是怎么序列化的呢?
首先要知道:
如果一个类不仅实现了 Serializable 接口,而且定义了 readObject(ObjectInputStream in) 和 writeObject(ObjectOutputStream out) 方法,那么将按照如下的方式进行序列化和反序列化:
ObjectOutputStream 会调用这个类的 writeObject 方法进行序列化,ObjectInputStream 会调用相应的 readObject 方法进行反序列化。
那么 ObjectOutputStream 又是如何知道一个类是否实现了 writeObject 方法呢?又是如何自动调用该类的 writeObject 方法呢? 答案是:是通过反射机制实现的。
ArrayList 中源码如下:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
可以看到,首先通过 s.defaultWriteObject(); 对非 transient 变量进行了序列化。然后又通过
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
这个循环对数组中的有值的元素逐个进行了序列化操作。
为什么使用transient修饰elementData?
既然要将 ArrayList 的字段序列化(即将 elementData 序列化),那为什么又要用 transient 修饰 elementData 呢? 回想 ArrayList 的自动扩容机制,elementData 数组相当于容器,当容器不足时就会再扩充容量,但是容器的容量往往都是大于或者等于 ArrayList 所存元素的个数。 比如,现在实际有了8个元素,那么 elementData 数组的容量可能是 8x1.5 =12,如果直接序列化elementData数组,那么就会浪费4个元素的空间,特别是当元素个数非常多时,这种浪费是非常不合算的。 所以ArrayList的设计者将elementData设计为transient,然后在writeObject方法中手动将其序列化,并且只序列化了实际存储的那些元素,而不是整个数组。 见源码:
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
从源码中,可以观察到 循环时是使用 i<size 而不是 i<elementData.length,说明序列化时,只需实际存储的那些元素,而不是整个数组。
java ArrayList的序列化分析 https://www.cnblogs.com/vinozly/p/5171227.html
ArrayList的序列化与反序列化 http://blog.csdn.net/qfycc92/article/details/45370011
LinkedList
双向链表,不能随机访问,非线程安全的
LinkedList实现原理
LinkedList 的实现原理总结如下:
1、 数据存储是基于双向链表实现的。
transient int size = 0;
transient Node<E> first; //双向链表首结点
transient Node<E> last; //双向链表尾结点
2、 插入数据很快。先是在双向链表中找到要插入节点的位置index,找到之后,再插入一个新节点。 双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3、 删除数据很快。先是在双向链表中找到要插入节点的位置index,找到之后,进行如下操作:
node.previous.next = node.next;
node.next.previous = node.previous;
node = null;
查找节点过程和插入一样。 4、 获取数据很慢,需要从Head节点进行查找。 5、 遍历数据很慢,每次获取数据都需要从头开始。
Java LinkedList的实现原理详解 http://blog.csdn.net/guoweimelon/article/details/50800730
为什么LinkedList可插入null?
LinkedList 使用内部的 Node<E> 结构来存储连表结点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
向 LinkedList 中插入 null 元素相当于插入一个 item 为 null 的 Node,并不影响 Node 具有前后指针。
Why can we add null elements to a java LinkedList? https://stackoverflow.com/questions/21206038/why-can-we-add-null-elements-to-a-java-linkedlist
ArrayList和LinkedList对比
ArrayList是动态数组,预申请连续内存,自动扩容,随机访问效率高,插入删除效率低。 LinkedList是双向链表,插入删除效率高,随机访问效率低。
get(i)访问效率对比
for循环中使用get(i)访问,采用的即是随机访问的方法,对于ArrayList效率高,可直接定位到元素i,对于LinkedList效率低,因为每次get(i)都需要从头开始数到i
get(i)和迭代器访问效率对比
通过哪种方式遍历LinkedList效率更高? 通过foreach方式(也就是for(a:linkedList))或者使用迭代器遍历效率高,因为Iterator中的next()方法采用的是顺序访问,其实foreach内部也是通过迭代器访问。
在最后添加元素的效率对比
ArrayList 和 LinkedList 在最后添加一个元素,哪个效率更高?
ArrayList 是连续存储空间,由于是在最后添加元素,不需要移动后续元素,可直接 O(1) 时间复杂度完成。
LinkedList 是非连续存储,内部是双向链表,有 tail 尾指针,也可以直接定位到最后一个元素,也可以在 O(1) 时间复杂度完成
时间复杂度一样。
但是,由于 ArrayList 是预分配连续空间,可能添加一个元素后导致需要扩容,如果遇到扩容就需要新申请一个 1.5 倍的连续存储空间,再把原数组拷贝过去,就会比较耗时。
所以,总的来看, LinkedList 在末尾添加元素更加高效。
Vector类(同步的)
动态数组,线程同步的。操作与ArrayList几乎一样。
每次容量不足时,默认自增长度的一倍(如果不指定增量的话),如下源码可知
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
若不指定,capacityIncrement默认为0
Vector实现原理 Vector的数据结构和ArrayList差不多,它包含了3个成员变量:elementData , elementCount, capacityIncrement。 (01) elementData 是"Object[]类型的数组",它保存了添加到Vector中的元素。elementData是个动态数组,如果初始化Vector时,没指定动态数组的大小,则使用默认大小10。随着Vector中元素的增加,Vector的容量也会动态增长,capacityIncrement是与容量增长相关的增长系数,具体的增长方式,请参考源码分析中的ensureCapacity()函数。 (02) elementCount 是动态数组的实际大小。 (03) capacityIncrement 是动态数组的增长系数。如果在创建Vector时,指定了capacityIncrement的大小;则,每次当Vector中动态数组容量增加时,增加的大小都是capacityIncrement。否则,将容量大小增加一倍。
Stack类(同步的)
Stack继承自Vector,实现一个后进先出的堆栈。 Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop方法,还有peek方法得到栈顶的元素
Stack的方法调用的Vector的方法,被 synchronized 修饰,为线程安全(Vector也是)
push 把项压入堆栈顶部 ,并作为此函数的值返回该对象
pop 移除堆栈顶部的对象,并作为此函数的值返回该对象
peek 查看堆栈顶部的对象,,并作为此函数的值返回该对象,但不从堆栈中移除它
empty 测试堆栈是否为空
search 返回对象在堆栈中的位置,以 1 为基数
LinkedList 实现了 Deque 接口,既可以当队列使用,也可以当栈使用
Queue queue = new LinkedList<TreeNode>();
Deque stack = new LinkedList<TreeNode>();
Set 接口
Set是一种不包括重复元素的Collection。set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2。并且最多包含一个 null 元素。
举一个例子:对象A和对象B,本来是不同的两个对象,正常情况下它们是能够放入到Set里面的,但是如果对象A和B的都重写了hashcode和equals方法,并且重写后的hashcode和equals方法是相同的话。那么A和B是不能同时放入到Set集合中去的,也就是Set集合中的去重和hashcode与equals方法直接相关。
HashSet
基于HashMap实现。非同步的。 HashSet中是允许存入null值的,但是在HashSet中仅仅能够存入一个null值。 HashSet的实现方式大致如下,通过一个HashMap存储元素,元素是存放在HashMap的Key中,而Value统一使用一个Object对象。
HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用null元素。HashSet中不允许有重复元素,这是因为HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个private static final Object PRESENT = new Object();。HashSet跟HashMap一样,都是一个存放链表的数组。
HashSet中add方法调用的是底层HashMap中的put()方法,而如果是在HashMap中调用put,首先会判断key是否存在,如果key存在则修改value值,如果key不存在这插入这个key-value。而在set中,因为value值没有用,也就不存在修改value值的说法,因此往HashSet中添加元素,首先判断元素(也就是key)是否存在,如果不存在这插入,如果存在着不插入,这样HashSet中就不存在重复值。
深入Java集合学习系列:HashSet的实现原理 https://www.cnblogs.com/xwdreamer/archive/2012/06/03/2532999.html
HashSet中怎样判断元素重复?
在hashset中不允许出现重复对象,元素的位置也是不确定的。在hashset中又是怎样判定元素是否重复的呢?在java的集合中,判断两个对象是否相等的规则是: 1.判断两个对象的hashCode是否相等 如果不相等,认为两个对象也不相等,完毕 如果相等,转入2 (这一点只是为了提高存储效率而要求的,其实理论上没有也可以,但如果没有,实际使用时效率会大大降低,所以我们这里将其做为必需的。)
2.判断两个对象用equals运算是否相等 如果不相等,认为两个对象也不相等 如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键) 为什么是两条准则,难道用第一条不行吗?不行,因为前面已经说了,hashcode()相等时,equals()方法也可能不等,所以必须用第2条准则进行限制,才能保证加入的为非重复元素。
Java提高篇——equals()与hashCode()方法详解 http://www.cnblogs.com/Qian123/p/5703507.html
LinkedHashSet(有序集合,按插入顺序)
基于LinkedHashMap来实现。非同步。 有序的,使用链表维护元素的次序,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
什么时候用有序集合呢? 当我们需要按插入顺序排序,同时需要 O(1) 判断集合中是否有某个元素,可以使用 LinkedHashSet 有序集合
LeetCode.210.Course Schedule II 课程表 II
TreeSet(按key排序/自定义key排序)
基于TreeMap实现,非同步。 有序集合,支持两种排序方式,自然排序和定制排序。
Queue 接口
Queue 接口与 List, Set 同一级别,都是继承了 Collection 接口。LinkedList 实现了 Queue 接口。
抛异常的:
add() 增加一个元索 如果队列已满,则抛出一个 IllegalStateException 异常
remove() 移除并返回队列头部的元素,如果队列为空,则抛出一个 NoSuchElementException 异常
element() 返回队列头部的元素。如果队列为空,则抛出一个 NoSuchElementException 异常
不抛异常的:
offer() 添加一个元素并返回true 如果队列已满,则返回 false
poll() 移除并返问队列头部的元素 如果队列为空,则返回 null
peek() 返回队列头部的元素 如果队列为空,则返回 null
| 方法/处理方式 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入方法 | add(E) | offer(E) |
| 移除方法 | remove() | poll() |
| 检查方法 | element() | peek() |
Deque 双端队列接口
double ended queue 双端队列,发音为 Deck
java.util.Deque
public interface Deque<E> extends Queue<E> {}
已知子接口
BlockingDeque<E>
已知实现类
ArrayDeque<E>, ConcurrentLinkedDeque<E>, LinkedBlockingDeque<E>, LinkedList<E>
Deque 提供从左右两端访问元素的方法,包括插入、删除、检查。 每种方法都有两种形式: 1、失败时抛异常 2、返回特殊值,null 或 false
| 第一个元素(头部) | 最后一个元素(尾部) | |||
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
抛异常的
add(E e) 尾部插入, 返回 boolean
addLast(E e) 尾部插入
push(E e) 头部插入
addFirst(E e) 头部插入
remove() 头部弹出
pop() 头部弹出
removeFirst() 头部弹出
removeLast() 尾部弹出
element() 查看头部元素
getFirst() 查看头部元素
getLast() 查看尾部元素
不抛异常的
offer(E e) 尾部插入, 返回 boolean
offerLast(E e) 尾部插入 ,返回 boolean
offerFirst(E e) 头部插入 ,返回 boolean
poll() 头部弹出
pollFirst() 头部弹出
pollLast() 尾部弹出
peek() 查看头部元素
peekFirst() 查看头部元素
peekLast() 查看尾部元素
用作 FIFO 队列
将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。
下面表格左侧是从 Queue 接口继承的方法, 右侧是与之完全等效的 Deque 方法
| Queue 方法 | 等效 Deque 方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
用作 LIFO 栈
双端队列也可用作 LIFO(后进先出)堆栈。
注意,在将双端队列用作队列或堆栈时,peek() 方法同样正常工作;无论哪种情况下,都从双端队列的开头抽取元素,用作栈时 peek() 是栈顶也就是最后插入的元素,用作队列时 peek() 是队首也就是最先插入的元素,都是正确的
经常会分不清 Deque 到底是栈还是队列,其实很简单,只需要明确 Deque 始终是 从 first 到 last 的一个线性集合,Queue 操作是 last 进 first 出,Stack 操作是 first 进 first 出
| 栈方法 | 等效 Deque 方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
为什么优先使用Deque代替Stack?
JDK 中建议优先使用 Deque 接口及其实现类,而不是 Stack 类
Stack 的文档中:
A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class. For example:
Deque stack = new ArrayDeque();
Deque 的文档中直接把 Stack 类称作 legacy 了:
Deques can also be used as LIFO (Last-In-First-Out) stacks. This interface should be used in preference to the legacy Stack class.
原因:
1、 Stack 的 Stream() 流化数据是按先进先出顺序的,违背了栈的设计原则,而 Deque 的所有实现类的 Stream() 流化数据都是后进先出顺序的,符合栈的设计原则。
如下
@Test
public void testStack() {
Deque<String> arrayDeque = new ArrayDeque<>();
Deque<String> linkedList = new LinkedList<>();
Deque<String> linkedBlockingDeque = new LinkedBlockingDeque<>();
Deque<String> concurrentLinkedDeque = new ConcurrentLinkedDeque<>();
Stack<String> stack = new Stack<>();
for (int i = 0; i < 10; i++) {
arrayDeque.push(String.valueOf(i));
linkedList.push(String.valueOf(i));
linkedBlockingDeque.push(String.valueOf(i));
concurrentLinkedDeque.push(String.valueOf(i));
stack.push(String.valueOf(i));
}
System.out.println(arrayDeque.stream().collect(Collectors.toList()));
System.out.println(linkedList.stream().collect(Collectors.toList()));
System.out.println(linkedBlockingDeque.stream().collect(Collectors.toList()));
System.out.println(concurrentLinkedDeque.stream().collect(Collectors.toList()));
// Stack 流是先进先出的,违背了栈的设计原则
System.out.println(stack.stream().collect(Collectors.toList()));
}
输出为
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
原因是 Collection 的流化 stream() 需要 Spliterator<E> spliterator() 方法的支持,而 Stack 没有实现自己的 spliterator() 方法,而是继承了 Vector 的,所以流化数据的顺序是先进先出的正序。
2、 Stack 和 Vector 都是线程安全的,强制加了 synchronized 锁,效率低。
Stack using the Java 8 collection streaming API https://stackoverflow.com/questions/30387579/stack-using-the-java-8-collection-streaming-api
Java 程序员,别用 Stack?! https://mp.weixin.qq.com/s/Ba8jrULf8NJbENK6WGrVWg
LinkedList既是Stack又是Queue
LinkedList 实现了 Deque 接口,既可以当队列使用,也可以当栈使用
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
}
例如
Queue queue = new LinkedList<TreeNode>();
Deque stack = new LinkedList<TreeNode>();
PriorityQueue 优先队列(堆/大顶堆/小顶堆)
java.util.PriorityQueue
public class PriorityQueue<E>
extends AbstractQueue<E>
implements Serializable{}
PriorityQueue 是非线程安全的,所以 Java 提供了 PriorityBlockingQueue(实现 BlockingQueue 接口)用于 Java 多线程环境。
peek() element() 获取堆顶元素,操作是常数时间 O(1)
add() offer() 向堆中添加元素,并调整堆,时间复杂度 O(logn)
remove() poll() 从堆顶删除元素,并调整堆,时间复杂度 O(logn)
boolean remove(Object o)
删除指定值的一个元素,假如值为 o 的元素有多个,只删除第一个
过程:O(n) 遍历找到第一个值等于o的元素下标i,把最后一个元素插入到i位置,然后O(logn)siftDown向下调整堆
注意:如果依次输出最大堆、最小堆中的元素,并不一定保证输出的序列是有序的,只能保证满足 大顶堆 arr[i] >= arr[2i+1] 且 arr[i] >= arr[2i+2],小顶堆:arr[i] <= arr[2i+1] 且 arr[i] <= arr[2i+2]
优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java 的优先队列每次取最小元素,C++的优先队列每次取最大元素)。 这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator,类似于C++的仿函数)。
Java 中 PriorityQueue 实现了 Queue 接口,不允许放入 null 元素;
其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为 PriorityQueue 的底层实现。
transient Object[] queue;
用数组作为堆的存储结构时,父子元素之间的关系
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。
放入 PriorityQueue 的自定义类必须指定排序方式
如果放入 PriorityQueue 的自定义类没有指定排序方式,会报错
Exception in thread "main" java.lang.ClassCastException: structs.ListNode cannot be cast to java.lang.Comparable
at java.util.PriorityQueue.siftUpComparable(PriorityQueue.java:653)
at java.util.PriorityQueue.siftUp(PriorityQueue.java:648)
可以通过两种方法指定排序方式:
1、放入 PriorityQueue 的自定义的类实现 Comparable 接口的 int compareTo(T o) 方法。String、Integer 这些类已经实现了 Comparable 接口,因此可以直接放入 PriorityQueue。
2、创建 PriorityQueue 时指定排序方式,使用带 comparator 参数的构造方法 PriorityQueue(Comparator<? super E> comparator)
默认创建的是最小堆(因为默认排序是升序,第一个元素是最小值,所以默认是最小堆,可以这样记)
示例
// 含有 len 个元素的最小堆,默认是最小堆,可以不写 lambda 表达式:(a, b) -> a - b
PriorityQueue<Integer> minHeap = new PriorityQueue<>(len);
PriorityQueue<Integer> minHeap = new PriorityQueue<>(len, (a, b) -> a - b);
// 含有 len 个元素的最大堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(len, (a, b) -> b - a);
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(len, Comparator.reverseOrder());
// 元素类型是 Pair 的最大堆, 根据 Pair 左值比较
PriorityQueue<Pair<Integer, String>> maxHeapPair = new PriorityQueue<>(10, (p1, p2) -> p2.getLeft() - p1.getLeft());
// ListNode 没有实现 Comparable 接口,必须提供一个 Comparator,否则报错
PriorityQueue<ListNode> priorityQueue = new PriorityQueue<>((node1, node2) -> node1.val - node2.val);
PriorityQueue<ListNode> priorityQueue = new PriorityQueue<>(Comparator.comparing(ListNode::getVal));
PriorityQueue<ListNode> priorityQueue = new PriorityQueue<>(Comparator.comparing(ListNode::getVal).reversed());
Map 接口
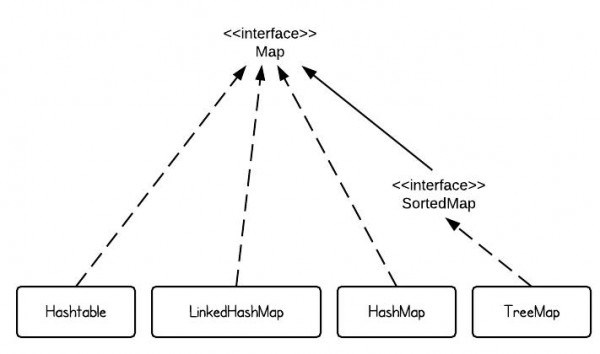
Map接口
Map并不是一个真正意义上的集合(are not true collections),但是这个接口提供了三种“集合视角”(collection views ),使得可以像操作集合一样操作它们,具体如下:
- 把map的内容看作key的集合(map’s contents to be viewed as a set of keys)
- 把map的内容看作value的集合(map’s contents to be viewed as a collection of values)
- 把map的内容看作key-value映射的集合(map’s contents to be viewed as a set of key-value mappings)
HashMap
基于Map接口实现、允许null键/值、非同步、不保证有序(比如插入的顺序)、也不保证序不随时间变化。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
HashMap内部实现(Node[] table)
HashMap的是初始容量(默认16)指的是桶的数量,或者说数组的长度。初始容量以及resize后的新容量总是2幂值,即使构造时传入的值不是2的幂值也会强制装换为2的幂值。 负载因子是hashmap中当前 元素数量/初始容量 的一个上限(此上限代码中用threshold(容量×负载因子)来衡量)。当超过整个限度时,会把链表数组的长度增加,重新计算各个元素的位置(最耗性能) 就是说,如果把负载因子调的很高,16个桶的HashMap也能装下100个元素,当然这时性能下降。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table; //存储键值对的Node数组(桶),默认长度16
transient int size; //当前键值对数量
transient int modCount; //结构发生变化的次数,用于迭代器的快速失败机制
int threshold; //最大数据量,等于table.length * loadFactor,超出时需要resize
final float loadFactor; //负载因子,默认0.75
}
Node节点结构:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
...
}
HashMap初始化(懒加载,桶个数2^n)
HashMap的是初始容量(默认16)指的是桶的数量(table数组的长度),或者说数组的长度。初始容量以及resize后的新容量总是2幂值,即使构造时传入的值不是2的幂值也会强制装换为2的幂值。
值得注意的是,当我们自定义HashMap初始容量大小时,构造函数并非直接把我们定义的数值当做HashMap容量大小,而是把该数值当做参数调用方法tableSizeFor,然后把返回值作为HashMap的初始容量大小:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
该方法会返回一个大于等于当前参数的2的倍数,因此HashMap中的table数组的容量大小总是2的倍数。
HashMap使用的是懒加载,构造完HashMap对象后,只要不进行put 方法插入元素之前,HashMap并不会去初始化或者扩容table:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
...
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在putVal方法第8、9行我们可以看到,当首次调用put方法时,HashMap会发现table为空然后调用resize方法进行初始化 在putVal方法第16、17行我们可以看到,当添加完元素后,如果HashMap发现size(元素总数)大于threshold(阈值),则会调用resize方法进行扩容
Java HashMap的扩容 https://www.cnblogs.com/KingIceMou/p/6976574.html
合理选择初始容量
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过 数组大小×loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16×0.75=12的时候,就把数组的大小扩展为2×16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75×1000 < 1000, 也就是说为了让0.75 × size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了问题,也避免了resize的问题。
在设置初始容量时应该考虑到映射中所需的条目数及其负载因子,以便最大限度的减少rehash操作次数。如果初始容量(桶的个数)大于最大条目数除以加载因子(初始容量乘以负载因子应该大于预估的最大元素数),则不会发生rehash操作。
为什么我们建议在定义HashMap的时候,就指定它的初始化大小呢? 正确的回答是: 在当我们对HashMap初始化时没有设置初始化容量,系统会默认创建一个容量为16的大小的集合。当HashMap的容量值超过了临界值(默认16*0.75=12)时,HashMap将会重新扩容到下一个2的指数幂(16->32)。HashMap扩容将要进行resize的操作,频繁resize,会导致降低性能。
你要是能补充一句: HashMap是线程不安全的,它的不安全就体现在resize的时候,多线程的情况下,可能会形成环形链表,导致下一次读取的时候可能会出现死循环。
要能再说说画画,具体是怎么死循环的,那就很不不错了。
Java HashMap提高性能和原理 http://blog.csdn.net/changlei_shennan/article/details/78680331
问题:给一组key{1,2,…,10},创建一个HashMap,指定初始容量为5,hash函数是key左移两位(<<1),在纸上画出来是怎么存储的?
需要考虑:
1、初始容量是5吗?
2、put过程中需要resize吗?
3、resize后是什么样的?
put方法流程与源码分析
put方法大致的思路为: 对key的hashCode()做hash,然后再计算index; 如果没碰撞直接放到bucket里; 如果碰撞了,以链表的形式存在buckets后; 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD,默认为8),就把链表转换成红黑树;(仅在java8以上版本) 如果节点已经存在就替换old value(保证key的唯一性) 如果bucket满了(超过load factor*current capacity),就要resize。
具体试下: 1)根据key计算当前Node的hash值,用于定位对象在HashMap数组的哪个节点。 2)判断table有没有初始化,如果没有初始化,则调用resize()方法为table初始化容量,以及threshold的值。 3)根据hash值定位该key 对应的数组索引,如果对应的数组索引位置无值,则调用newNode()方法,为该索引创建Node节点 4)如果根据hash值定位的数组索引有Node,并且Node中的key和需要新增的key相等,则将对应的value值更新。 5)如果在已有的table中根据hash找到Node,其中Node中的hash值和新增的hash相等,但是key值不相等的,那么创建新的Node,放到当前已存在的Node的链表尾部。 如果当前Node的长度大于8,则调用treeifyBin()方法扩大table数组的容量,或者将当前索引的所有Node节点变成TreeNode节点,变成TreeNode节点的原因是由于TreeNode节点组成的链表索引元素会快很多。 5)将当前的key-value 数量标识size自增,然后和threshold对比,如果大于threshold的值,则调用resize()方法,扩大当前HashMap对象的存储容量。 6)返回oldValue或者null。
HashMap put()方法源码jdk1.8:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果是第一次调用,则会调用resize 初始化table 以及threshold
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果对应的索引没有Node,则新建Node放到table里面。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果hash值与已存在的hash相等,并且key相等,则准备更新对应Node的value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果hash值一致,但是key不一致,那么将新的key-value添加到已有的Node的最后面
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 当某个节点的链表长度大于8,则扩大table 数组的长度或者将当前节点链表变成树节点链表
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
//hash值和key值相等的情况下,更新value值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//留给LinkedHashMap实现
afterNodeAccess(e);
//返回旧的value
return oldValue;
}
}
//修改次数加1
++modCount;
//判断table的容量是否需要扩展
if (++size > threshold)
resize();
//留给LinkedHashMap扩展
afterNodeInsertion(evict);
return null;
}
HashMap源码分析(基于JDK8) https://blog.csdn.net/fighterandknight/article/details/61624150
resize源码分析(jdk1.7)
jdk1.7 resize源码如下,传进来的newCapacity参数是2 * table.length,即两倍原数组大小
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int) (newCapacity * loadFactor);//修改阈值
}
transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里:
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K, V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K, V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //头插法,把i位置上的链表挂到e后面
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
static int indexFor(int h, int length) {
return h & (length - 1);
}
jdk1.8中:
newCap = oldCap << 1;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
resize后table大小变为原来的两倍
Java HashMap中在resize()时候的rehash,即再哈希法的理解 https://blog.csdn.net/qq_27093465/article/details/52270519
hash()和下标(桶)的计算
在 Java 1.8 的 hash() 方法实现中,是通过 hashCode() 的高 16 位异或低 16 位实现的:
(h = k.hashCode()) ^ (h >>> 16)
主要是从速度、功效、质量来考虑的,这么做可以在 bucket 的 n 比较小的时候,也能保证考虑到高低 bit 都参与到 hash 的计算中,同时不会有太大的开销。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
而计算下标的时候,是通过 hash() 返回值与 桶个数减1 按位与(使用 & 位操作,而非 % 求余)实现的,即 (n - 1) & hash
这也就是为什么 HashMap 的容量必须是 2 幂,是为了方便散列时的按位与运算。
由于 n 肯定是 2 的幂,则 n-1 肯定是低位全1,也就是相当于截取 hash() 返回值的低 n 位
以 hashmap 初始容量 16 为例 16-1 二进制表示为 0000 .... 0000 1111 ,如下图:
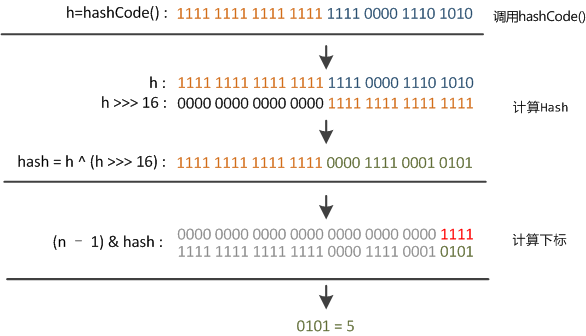
Map的hash()计算与桶散列
通过这个散列过程我们发现,只取了 hash() 的低 n 位,高位全部忽略了。这时候问题就来了,这样就算我的散列值分布再均匀,要是只取最后几位的话,碰撞也会很严重。如果再出现连续的低位相同的 hash 值,碰撞更会非常严重。
怎么办呢?
解决方法就是 hash() 方法的实现,高 16 位和低 16 位异或。
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
从而使散列更加均匀,减少碰撞。
Java HashMap工作原理及实现 http://www.importnew.com/18633.html
HashMap中如何存储null key?(table[0])
HashMap可以允许插入null key和null value HashTable和ConcurrentHashMap都不可以插入null key和null value
jdk1.8中HashMap的hash()方法中会判断key是否为null,如果key为null则直接返回0,所以null key是存储在table[0]中的,也就是数组的第一个元素。当key不为0时才会调用key.hashcode()进行rehash计算,所以也不会抛出异常。
如果value为null,和普通非空value一样,只是创建的Node节点中的value字段为null而已,没有任何影响。
HashMap中插入null key的过程分析 https://blog.csdn.net/glory1234work2115/article/details/50825503
HashTable和ConcurrentHashMap如何保证不插入null key和value?
HashTable和ConcurrentHashMap的put()方法会检查value是否null,如果为null则抛出空指针异常,之后会调用key.hashcode(),所以如果key为null,也会抛出空指针异常。所以HashTable和ConcurrentHashMap都不可以插入null key和null value
HashMap HashTable ConcurrentHashMap key和value是否可以null的问题 源码分析 https://blog.csdn.net/glory1234work2115/article/details/50830743
为什么这么设计?(是否支持并发)
ConcurrentHashmap和Hashtable都是支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用m.contains(key)和m.get(key),m可能已经不同了。
为什么Hashtable ConcurrentHashmap不支持key或者value为null https://blog.csdn.net/gagewang1/article/details/54971965
自定义类作HashMap的key必须重写equals()和hashcode()方法
如果要使用自己的类作为 HashMap 的键,必须同时重载 hashCode() 和 equals()
在 HashMap 中,查找 key 的比较顺序为: 1、调用 hashCode() 方法计算 object 的哈希码,定位在哈希表中的哪个桶 2、若桶中有对象,调用 equals() 方法比较这些对象与 object 是否相等,若有相等的,重置 value 值,若没相等的,添加到链表末尾
显然,第一步就是要用到 hashCode() 方法,而第二步就是要用到 equals() 方法。在没有进行重载时,在这两步会默认调用 Object 类的这两个方法,而在 Object 中,Hash Code 的计算方法是根据对象的地址进行计算的,那两个 Person("003") 的对象地址是不同的,所以它们的 Hash Code 也不同,自然 HashMap 也不会把它们当成是同一个 key 了。同时,在 Object 默认的 equals() 中,也是根据对象的地址进行比较,自然一个 Person("003") 和另一个 Person("003") 是不相等的。
理解了这一点,就很容易搞清楚为什么需要同时重载 hashCode() 和 equals() 两个方法了。 重载 hashCode() 是为了对同一个 key,能得到相同的 Hash Code,这样 HashMap 就可以定位到我们指定的 key 上。 重载 equals() 是为了向 HashMap 表明当前对象和 key 上所保存的对象是相等的,这样我们才真正地获得了这个 key 所对应的这个键值对。
Java用自定义的类作为HashMap的key值实例 http://www.jb51.net/article/99636.htm
Java HashMap实现原理 源码剖析 https://www.cnblogs.com/haifeng1990/p/6262417.html
什么情况下性能退化为O(n)(HashMap性能分析)
HashMap使用key的hashCode()和equals()方法来将值划分到不同的桶里。桶的数量通常要比map中的记录的数量要稍大,这样每个桶包括的值会比较少(最好是一个)。当通过key进行查找时,我们可以在常数时间内迅速定位到某个桶(使用hashCode()对桶的数量进行取模)以及要找的对象。
如果多个hashCode()的值落到同一个桶内的时候,这些值是存储到一个链表中的。最坏的情况下,所有的key都映射到同一个桶中,这样hashmap就退化成了一个链表——查找时间从O(1)到O(n)。
比如,HashMap的key类型是我们自定义的,重写了hashCode()和equals()方法,并且所有key类的实例都有相同的hashCode,如下:
class Key implements Comparable<Key> {
//...
@Override
public int hashCode() {
return 0;
}
}
此时所有元素都存储在一个桶内,get性能退化为O(n)
Java 8:HashMap的性能提升 http://www.importnew.com/14417.html
java8对HashMap的改进
JDK8中HashMap的新特性,如果某个桶中的链表记录过大的话(默认是TREEIFY_THRESHOLD = 8),就会把这个链动态变成红黑二叉树,使查询最差复杂度由O(N)变成了O(logN)。
如果某个桶中的记录过大的话(当前是TREEIFY_THRESHOLD = 8),HashMap会动态的使用一个专门的treemap实现来替换掉它。
它是如何工作的? 前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。但是超过这个阈值后HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。
哪一步触发将链表改为红黑树?(putVal)
java 8 中 putVal 源码如下,
// 超过 TREEIFY_THRESHOLD 时将冲突链表改为红黑树
static final int TREEIFY_THRESHOLD = 8;
// resize 分隔冲突的红黑树后,如果树的元素数小于 UNTREEIFY_THRESHOLD 时还原为链表
static final int UNTREEIFY_THRESHOLD = 6;
// 当桶个数大于等于 MIN_TREEIFY_CAPACITY 时才考虑转为红黑树,如果桶个数太小会先 resize 再树化
static final int MIN_TREEIFY_CAPACITY = 64;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 第一次插入数据时 resize 申请空间
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 无冲突
else { // 有冲突, p 是冲突链表的首节点
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 大于 8 时改为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 需要 resize 扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
什么情况下红黑树又会变为链表?(resize)
每次 resize 双倍扩容时,放新的 Node[] tab 放元素时,如果发现这个桶有冲突树,会试着做 split ,把树分隔到不同的桶,
或者当树的结点个数小于阈值 UNTREEIFY_THRESHOLD 时,会再次恢复成链表。
也就是 resize 后单个桶的冲突树变小了,就没必要再用红黑树了。
为什么HashMap是线程不安全的?
并发put同一个key可能导致写丢失
如果多个线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞(key相同或者hash值一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
示例如下,多线程并发的 put 同一个 key,value各不相同,put后马上get出来比较和put的值是否相同
@Test
public void testConcurrent() throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
Map<String, String> map = new HashMap<>();
String key = "mykey";
for (int i = 0; i < 40; i++) {
executorService.execute(() -> {
String putValue = Thread.currentThread().getName();
map.put(key, putValue);
String getValue;
if (!(getValue = map.get(key)).equals(putValue)) {
System.err.println("put: " + putValue + " get:" + getValue + " 不一致");
}
});
}
executorService.shutdown();
executorService.awaitTermination(10, TimeUnit.SECONDS);
System.out.println(map);
}
上面的测试代码执行时就可能出现不一致的结果,当然不是每次运行都有问题,是偶现的
put: pool-1-thread-1 get:pool-1-thread-2 不一致
{mykey=pool-1-thread-3}
并发resize可能导致Node链表形成环而产生死循环(jdk8之前)
当多个线程 putVal 时同时检测到元素个数 size 超过阈值 threshold 的时候,就会同时调用 resize() 方法对 Node 数组 table[] 进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给 table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。
发生写丢失还是比较好的一种情况,如果扩容线程已经完成赋值而另一个线程刚开始,就会用已经扩容后的 table 作为原始数组再次进行扩容操作和复制数据,这样可能会导致更严重的 Node 数组环形链表问题。
关于HashMap线程不安全这一点,《Java并发编程的艺术》一书中是这样说的: HashMap在并发执行put操作时会引起死循环,导致CPU利用率接近100%。因为多线程会导致HashMap的Node链表形成环形数据结构,一旦形成环形数据结构,Node的next节点永远不为空,就会在获取Node时产生死循环。
链表出现环的问题发生在 线程1 执行到 jdk7 中的 transfer() 方法中获取了一个冲突链表的头指针 head 刚要开始遍历此链表往 newTable 中放,这时发生cpu切换到 线程2 执行,线程2 进行了 resize 扩容,扩容后原来 head 的下一个结点变成了 head 前面的结点, 然后又切换到 线程1 执行,线程1中继续进行链表移动时,就可能在 head 结点和其后的结点之间形成环。具体看下面博客中的分析。
HashMap 在高并发下引起的死循环 https://www.jianshu.com/p/619a8efcf589
Java8中的HashMap如何解决环链问题?
注意:HashMap 并发 resize 导致死循环问题只会在 jdk7 及之前出现, jdk8 之后 HashMap 不会因为多线程 put 导致死循环,因为 JDK8 resize 时用 head 和 tail 来保证链表的顺序和之前一样;而 JDK7 rehash 会倒置链表元素,但是还会有数据丢失的问题(这是并发本身的问题)。
如果存在碰撞,且节点是链表,则处理链表的情况,rehash过程会保留节点原始顺序(JDK7中不会保留,这也是导致jdk7中多线程出现死循环的原因)
如何线程安全的使用HashMap?
1、使用Hashtable(不推荐,synchronized)
1、使用 java.util.Hashtable 类,此类是线程安全的。但效率很低。因此是不推荐的。
2、使用Collections包装(不推荐,synchronized)
2、使用 java.util.Collections.synchronizedMap(Map<K,V>) 方法进行封装。
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<K,V>(m);
}
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
}
从实现源代码可以发现,其封装的本质和 Hashtable 的实现是完全一致的,即对原Map本身的方法进行加锁,加锁的对象或者为外部指定共享对象mutex,或者为包装后的线程安全的Map本身。Hashtable 可以理解为 SynchronizedMap mutex=null 时候的特殊情况。因此这种同步方式的执行效率也是很低的。
既然已经有了Hashtable, 为什么还需要Collections 提供的这种静态方法包装哪?很简单,这种包装是Java Collection Framework提供的统一接口,除了用于 HashMap 外,还可以用于其他的Map。当然 除了对Map进行封装,Collections工具类还提供了对 Collection(比如Set,List)的线程安全实现封装方法,具体请参考 java.util.Colletions 实现,其原理和 SynchronizedMap 是一致的。
3、使用ConcurrentHashMap(推荐,分段加锁)
3、使用 java.util.concurrent.ConcurrentHashMap 类。 这是 HashMap 的线程安全版,同 Hashtable 相比,ConcurrentHashMap 不仅保证了访问的线程安全性,而且在效率上有较大的提高。
4、自己在代码中访问HashMap时加锁(不推荐,效率低)
4、自己在程序的关键方法或者代码段加锁,保证安全性,当然这是严重的不推荐。
Java - 线程安全的 HashMap 实现方法及原理 http://liqianglv2005.iteye.com/blog/2025016
WeakHashMap(弱引用版HashMap)
WeakHashMap与HashMap的用法基本类似。
区别: 1、HashMap的key保留了对实际对象的强引用,这意味着只要HashMap对象不被销毁,还HashMap的所有key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key所对应的key-value对; 2、WeakHashMap的key只保留对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key所对应的key-value对。 3、WeakHashMap中的每个key对象只持有对实际对象的弱引用,因此,当垃圾回收了该key所对应的实际对象之后,WeakHashMap会自动删除该key对应的key-value对。
注意:如果需要使用WeakHashMap的key来保留对象的弱引用,则不要让该key所引用的对象具有任何强引用,否则将失去WeakHashMap的意义。
package com.map;
import java.util.WeakHashMap;
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap wak = new WeakHashMap();
//两个key都是匿名字符串对象(没有其他引用)
wak.put(new String("数学"), new String("优良"));
wak.put(new String("语文"), new String("良好"));
//该key是一个系统缓存的字符串对象
wak.put("java", new String("好")); //①
System.out.println(wak);
//{java=良好, 数学=优良, 语文=良好}
//通知系统进行垃圾回收
System.gc();
System.runFinalization();
System.out.println(wak);//{java=好}
}
}
结果上来看:当系统进行垃圾时,删除了WeakHashMap 对象的前两个key-value对,因为添加前两个key-value对时,这两个key都是匿名的字符串对象,WeakHashMap 只保留了对它们的弱引用,这样垃圾回收时会自动删除这两个key-value对。
WeakHashMap对象中①标示处的key是一个字符串直接量(系统会自动保留对该字符串对象的强引用),所以垃圾回收时不会回收它。
Java集合之WeakHashMap、IdentityHashMap、EnumMap介绍 https://blog.csdn.net/wxc880924/article/details/52683097
IdentityHashMap(允许key重复)
在Java中,有一种key值可以重复的map,就是IdentityHashMap。在IdentityHashMap中,判断两个键值k1和 k2相等的条件是 k1 == k2 。在正常的Map 实现(如 HashMap)中,当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2))。
package com.map;
import java.util.IdentityHashMap;
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap idenmap = new IdentityHashMap();
idenmap.put(new String("语文"), 80);
idenmap.put(new String("语文"), 89);
idenmap.put("java", 80);
idenmap.put("java", 80);
System.out.println(idenmap);
//{语文=80, java=80, 语文=89}
}
}
IdentityHashMap对象中添加了4个key-value对,前2个key-value对中的key是最新创建的字符串对象,它们通过==比较不相等,所以IdentityHashMap 会把他们当成2个key来处理;后2个key-value都是字符串直接量,而且它们的字符序列完全相同,Java使用常量池来管理字符串直接量,所以它们通过==比较返回true,IdentityHashMap 会认为它们是同一个key,因此只有一次可以添加成功。
Java集合之WeakHashMap、IdentityHashMap、EnumMap介绍 https://blog.csdn.net/wxc880924/article/details/52683097
java中key值可以重复的map:IdentityHashMap https://www.cnblogs.com/it-deepinmind/p/7309522.html
HashMap中如何插入重复key?(重写equals)
put()方法实现:首先hash(key)得到key的hashcode(),hashmap根据获得的hashcode找到要插入的位置所在的链,在这个链里面放的都是hashcode相同的Entry键值对,在找到这个链之后,会通过equals()方法判断是否已经存在要插入的键值对,而这个equals比较的其实就是key。
java HashMap插入重复Key值问题 https://blog.csdn.net/intersting/article/details/72627353
EnumMap
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显示或隐式的指定它对应的枚举类。
EnumMap特征: 1、EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。 2、EunmMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护key-value对的顺序。 3、EnumMap不允许使用null作为key,但允许使用null作为value。如果试图使用null作为key时将抛出NullpointerException。
如果只是查询是否包含值为null的key,或只是删除值为null的key,都不会抛出异常。
与普通的Map有所区别的是,创建EnumMap是必须指定一个枚举类,从而将该EnumMap和指定枚举类关联起来。
示例:
package com.map;
import java.util.EnumMap;
public class EnumMapTest {
public static void main(String[] args) {
EnumMap map = new EnumMap(Season.class);
map.put(Season.SPRING, "春天");
map.put(Season.SUMMER, "夏天");
System.out.println(map);
//{SPRING=春天, SUMMER=夏天}
}
}
enum Season{
SPRING,SUMMER,FAIL,WINTER
}
Java集合之WeakHashMap、IdentityHashMap、EnumMap介绍 https://blog.csdn.net/wxc880924/article/details/52683097
Hashtable(同步的)
Hashtable与HashMap类似,不同的是 1、HashMap允许key或value为null,Hashtable中key,value都不能为null; 2、是线程的同步的,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
Hashtable如何保证线程同步(安全)?
Hashtable的put,get,remove等方法都加了关键字synchronized,所以是线程同步的,任意时刻只有一个线程可以put,其他线程被阻塞。
public synchronized V get(Object key)
public synchronized V put(K key, V value)
public synchronized V remove(Object key)
public synchronized void clear()
但是也大大的降低了执行效率。因此是不推荐的。
Java - 线程安全的 HashMap 实现方法及原理 http://liqianglv2005.iteye.com/blog/2025016
HashTable与HashMap的异同点
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口。主要的区别有:线程安全性,同步(synchronization),以及速度。 相同点: (1)都实现了Map、Cloneable、java.io.Serializable接口。 (2)都是存储"键值对(key-value)"的散列表,而且都是采用拉链法实现的。 不同点: (1)历史原因:HashTable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现 。 (2)同步性:HashTable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的 。 (3)对null值的处理:HashMap的key、value都可为null,HashTable的key、value都不可为null 。 (4)基类不同:HashMap继承于AbstractMap,而Hashtable继承于Dictionary。
JAVA中HashMap和Hashtable区别 https://www.cnblogs.com/lchzls/p/6714335.html
LinkedHashMap(默认插入排序/可选访问排序)
LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap
在用 Iterator 遍历 LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
LinkedHashMap 其实就是在 HashMap 的基础上增加了一个 双向链表, 用这个双向链表实现了有序,此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
可以看下这个题的官方题解中的手动实现,其实就是利用 HashMap + 双向链表 实现了一个基础版的 LinkedHashMap LeetCode.146.LRU Cache 实现LRU缓存
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。 默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
类定义:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
transient LinkedHashMap.Entry<K,V> head; //双向链表的头节点
transient LinkedHashMap.Entry<K,V> tail; //双向链表的尾结点
final boolean accessOrder; //迭代顺序,true表示访问顺序,默认为false表示插入顺序
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
}
LinkedHashMap 继承自 HashMap ,所有构造方法都是通过调用父类的构造方法来创建对象的,默认创建时按插入顺序(accessOrder为false)。
下面HashMap类定义的基本成员在LinkedHashMap中也都有:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table; //存储键值对的Node数组(桶),默认长度16
transient int size; //当前键值对数量
transient int modCount; //结构发生变化的次数,用于迭代器的快速失败机制
int threshold; //最大数据量,等于table.length * loadFactor,超出时需要resize
final float loadFactor; //负载因子,默认0.75
}
结点Entry(加before和after指针构成双向链表)
LinkedHashMap 中存储数据的 Entry 静态类继承自 HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
HashMap.Node 节点结构:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
...
}
除了Node中的hash,key,value,next外,LinkedHashMap的Entry中还增加了两个成员:before和after指针,分别指向双向链表的上一个、下一个结点。
LinkedHashMap重新定义了数组中保存的元素Entry(继承于HashMap.Entry),该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。仍然保留next属性,所以既可像HashMap一样快速查找,用next获取该链表下一个Entry,也可以通过双向链接,通过after完成所有数据的有序迭代。
不要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
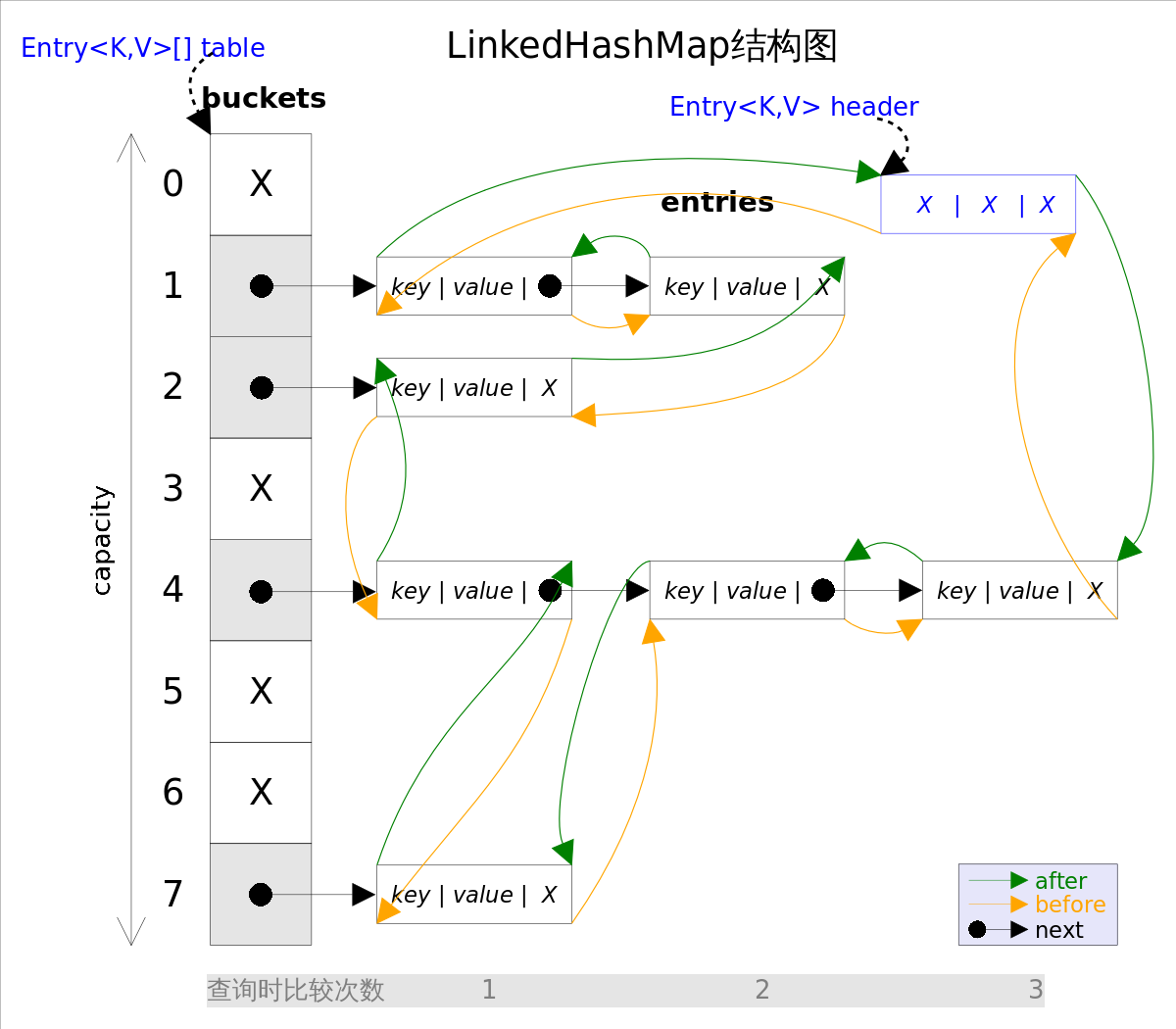
LinkedHashMap结构图
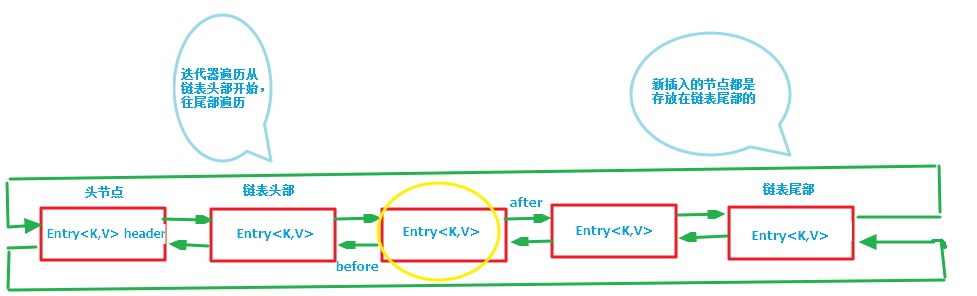
LinkedHashMap中的双向链表
第一张图为LinkedHashMap整体结构图,第二张图专门把循环双向链表抽取出来,直观一点,循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
put方法(HashMap的put+重写addEntry)
LinkedHashMap 并未重写父类 HashMap 的 put 方法,而是重写了父类HashMap的put方法调用的子方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
所以,放到 Node<K,V>[] table 中的,其实是 LinkedHashMap 中的 LinkedHashMap.Entry
重写了 afterNodeAccess() 方法,如果指定按访问顺序排序,则把刚访问的结点 e 放到双向链表末尾,也就是 tail 指针会指向 e
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
也就是说,LinkedHashMap中是直接调用的HashMap的put方法,只不过重写了addEntry方法,put的时候如果需要新增加元素会调用addEntry方法。
HashMap中的put方法(jdk1.6)
//这个方法应该挺熟悉的,如果看了HashMap的解析的话
public V put(K key, V value) {
//key为null的情况
if (key == null)
return putForNullKey(value);
//通过key算hash,进而算出在数组中的位置,也就是在第几个桶中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//查看桶中是否有相同的key值,如果有就直接用新值替换旧值,而不用再创建新的entry了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//上面度是熟悉的东西,最重要的地方来了,就是这个方法,LinkedHashMap执行到这里,addEntry()方法不会执行HashMap中的方法,
//而是执行自己类中的addEntry方法,
addEntry(hash, key, value, i);
return null;
}
这里是一个多态,因为LinkedHashMap重写了addEntry方法,因此addEntry调用的是LinkedHashMap重写了的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex); // 重写了HashMap中的createEntry方法
//双向链表的第一个有效节点(header后的那个节点)为最近最少使用的节点,这是用来支持LRU算法的
Entry<K,V> eldest = header.after;
//如果有必要,则删除掉该近期最少使用的节点,
//这要看对removeEldestEntry的覆写,由于默认为false,因此默认是不做任何处理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//扩容到原来的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
可以看到,addEntry中先通过removeEldestEntry()方法判断是否需要删除元素(默认直接返回false即不删除),如果需要的话通过removeEntryForKey()删除最久未使用元素(也就是头结点后的第一个元素,刚被访问的元素会被摘下来插入到末尾),所以只要重写removeEldestEntry()方法即可快速利用LinkedHashMap实现一个LRU缓存。
看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
// 向哈希表中插入Entry,这点与HashMap中相同
//创建新的Entry并将其链入到数组对应桶的链表的头结点处,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//在每次向哈希表插入Entry的同时,都会将其插入到双向链表的尾部,
//这样就按照Entry插入LinkedHashMap的先后顺序来迭代元素(LinkedHashMap根据双向链表重写了迭代器)
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,也符合LRU算法的实现
e.addBefore(header); //addBefore方法本质上是一个双向链表的插入操作
size++;
}
总的来说,相比HashMap而言,LinkedHashMap在向哈希表添加一个键值对的同时,也会将其链入到它所维护的双向链表中,以便设定迭代顺序。
get方法(重写get方法,增加按访问排序调整)
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时(即按访问顺序排序),先将当前节点从链表中移除,然后再将当前节点插入到链表尾部。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
/**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
recordAccess源码如下,在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
/**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
LinkedHashMap如何实现有序?
LinkedHashMap的构造方法 public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder) 第三个参数accessOrder,false 基于插入顺序(默认),true 基于访问顺序(get一个元素后,这个元素被加到最后)
LinkedHashMap重写了HashMap中保存的元素Entry,增加了上一个元素的引用before和下一个元素的引用after,从而在哈希表的基础上又构成了双向循环链表。
若指定按访问顺序排序的话,每次访问(get和put都算访问)时都会把刚访问的元素移到双向链表的尾部,所以 循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点。
如何实现的呢? LinkedHashMap的put和get中都会调用recordAccess方法(jdk1.8中是afterNodeAccess方法)来将刚访问的元素移到双向链表末尾。
recordAccess中做了两件事情: 1、把待移动的Entry的前后Entry相连 2、把待移动的Entry移动到尾部
recordAccess源码如下,在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
排序实例分析
1、问如下代码输出是多少?
@Test
public void testAccessOrder() {
Map<Integer, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
map.put(1,1);
map.put(2,2);
map.get(1);
map.put(3,3);
System.out.println(map);
map.put(1,1);
System.out.println(map);
}
结果为
{2=2, 1=1, 3=3}
{2=2, 3=3, 1=1}
构造方法第三个参数指明按 access order 有序,每次访问一个元素,该元素就会被放到双向链表末尾 put 和 get 都是访问
2、问如下代码的输出是多少?
@Test
public void testInsertOrder() {
Map<Integer, Integer> map = new LinkedHashMap<>();
map.put(1,1);
map.put(2,2);
map.get(1);
map.put(1,11);
map.put(3,3);
System.out.println(map);
map.remove(1);
map.put(1,11);
System.out.println(map);
}
结果为
{1=11, 2=2, 3=3}
{2=2, 3=3, 1=11}
需要注意的是,对于按插入顺序排序的 LinkedHashMap ,put 的 key 已存在时对应的顺序不会改变。
Java集合之LinkedHashMap - 平凡希 https://www.cnblogs.com/xiaoxi/p/6170590.html
Map 综述(二):彻头彻尾理解 LinkedHashMap https://blog.csdn.net/justloveyou_/article/details/71713781
利用LinkedHashMap实现LRU缓存(重写removeEldestEntry)
LinkedHashMap 的3参数构造方法
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
第三个参数accessOrder,false 基于插入顺序(默认),true 基于访问顺序(get一个元素后,这个元素被加到最后)
将构造方法的第三个参数设为true,可自动按访问顺序排序。
因为 LinkedHashMap 的 putVal() 最后一步 afterNodeInsertion() 中当 removeEldestEntry() 返回 true 时会删除 first 结点,如果构造方法中设置了 accessOrder=true,first结点就是最早访问的结点。
所以只要重写removeEldestEntry()方法即可快速利用LinkedHashMap实现一个LRU缓存
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
LeetCode.146.LRU Cache 实现LRU缓存
具体实现如下:
public class LRUCache<k, V> extends LinkedHashMap {
// LRU的最大元素个数,即缓存的容量
protected int maxSize;
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true);
this.maxSize = maxSize;
}
// 覆盖 HashMap 的 put 方法,不需要返回值
public void put(K key, V value) {
super.put(key, value);
}
public V get(Object key) {
return (V) super.get(key);
}
// 重写 removeEldestEntry 当元素个数大于初始容量 maxSize 时删除最长时间没访问的Entry
@Override
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
return size() > maxSize;
}
public static void main(String[] args) {
LRUCache<Integer, Integer> lruCache = new LRUCache<>(2);
lruCache.put(1, 1);
lruCache.put(2, 2);
System.out.println(lruCache.get(1)); // returns 1
lruCache.put(3, 3); // evicts key 2
System.out.println(lruCache.get(2)); // returns -1 (not found)
lruCache.put(4, 4); // evicts key 1
System.out.println(lruCache.get(1)); // returns -1 (not found)
System.out.println(lruCache.get(3)); // returns 3
System.out.println(lruCache.get(4)); // returns 4
}
}
构造方法中调用父类也就是LinkedHashMap的构造器,第三个参数设为true表示按访问顺序排序。 重写removeEldestEntry()方法,当size大于缓存容量是返回true,则put时会自动删除最久未使用的元素。也就是实现了LRU缓存。
Java集合之LinkedHashMap - 平凡希 https://www.cnblogs.com/xiaoxi/p/6170590.html
TreeMap(按key排序/自定义key排序)
基于红黑树实现,每一个key-value节点作为红黑树的一个节点。
TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。 默认是按 key 的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
Java TreeMap实现了SortedMap接口,也就是说会按照key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。
TreeMap底层通过红黑树(Red-Black tree)实现,也就意味着 containsKey(), get(), put(), remove() 都有着 log(n) 的时间复杂度。
出于性能原因,TreeMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过Collections工具类将TreeMap包装成(wrapped)同步的
自定义类作TreeMap/TreeSet的key必须指定排序方式
比如有个 Person 类
private static class Person {
Integer age;
String name;
Person(Integer age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "{age:" + age + ", name:" + name + "}";
}
}
如果不指定排序方式,直接作为 key 往 TreeMap 中放
TreeMap<Person, Integer> treeMap = new TreeMap<>();
treeMap.put(new Person(1, "lilei"), 1);
或者作为 TreeSet 的元素
TreeSet<Person> treeSet = new TreeSet<>();
treeSet.add(new Person(1, "lilei"));
会报错,提示不是 Comparable 的实现类
java.lang.ClassCastException: com.masikkk.common.jcf.TreeSetTest$Person cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(TreeMap.java:1294)
at java.util.TreeMap.put(TreeMap.java:538)
可以通过两种方法指定排序方式:
1、作为 key 的类实现 Comparable 接口的 int compareTo(T o) 方法。String、Integer 这些类已经实现了 Comparable 接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
2、创建 TreeMap 或 TreeSet 时指定排序方式,使用带 comparator 参数的构造方法, TreeMap 是 TreeMap(Comparator<? super K> comparator) 构造方法, TreeSet 则是 TreeSet(Comparator<? super E> comparator) 构造方法
自定义类做TreeSet元素实例
例如 TreeSet
// 测试 TreeSet 中放自定义类
@Test
public void testClassInTreeSet() {
TreeSet<Person> treeSet = new TreeSet<>((k1, k2) -> k1.age - k2.age);
treeSet.add(new Person(1, "lilei"));
treeSet.add(new Person(8, "hameimei"));
treeSet.add(new Person(3, "tom"));
System.out.println(treeSet);
}
结果
[{age:1, name:lilei}, {age:3, name:tom}, {age:8, name:hameimei}]
自定义类做TreeMap的key实例
例如 TreeMap
// 测试自定义类作为 TreeMap 的 key
@Test
public void testClassAsTreeMapKey() {
TreeMap<Person, Integer> treeMap = new TreeMap<>((k1, k2) -> k1.age - k2.age);
treeMap.put(new Person(1, "lilei"), 1);
treeMap.put(new Person(8, "hameimei"), 2);
treeMap.put(new Person(3, "tom"), 3);
System.out.println(treeMap);
}
结果
{{age:1, name:lilei}=1, {age:3, name:tom}=3, {age:8, name:hameimei}=2}
TreeMap/TreeSet不使用equals()和hashcode()方法
对于 class 类型的 key 或元素,TreeMap/TreeSet 和 HashMap/HashSet 的处理方式完全不同:
- HashMap/HashSet 使用 Key 的
equals()和hashCode()方法来决定 key 是否已存在。 - 但 TreeMap/TreeSet 不使用
equals()和hashCode()方法判断 key 是否存在,而是使用比较器,比较器的来源有两种,一种是作为 key 的 class 本身实现的Comparable接口的compareTo方法,另一种是构造 TreeMap/TreeSet 时指定的Comparator的compare(T o1, T o2)方法。
所以,class 做 TreeMap 的 key 或 TreeSet 的元素时,不需要指定 equals() 和 hashCode() 方法,但必须指定排序方法。
自定义类做TreeMap/TreeSet的key必须处理相等情况
自定义类做 TreeMap 的 key 或 TreeSet 的元素时,必须处理相等情况,否则排序是正常的,但无法判断相同的 key 是否存在,也就是会出现放入的元素无法 get 的情况。 例如,下面的测试代码中,指定的比较器只处理了大于和小于的情况,在 key 相等时没有返回 0,出现了放入的key拿不出的情况
// 自定义类作为 TreeMap 的 key 时必须处理相等的情况
@Test
public void testEqualTreeMap() {
TreeMap<Person, Integer> treeMap = new TreeMap<>((k1, k2) -> k1.age < k2.age ? -1 : 1);
treeMap.put(new Person(1, "lilei"), 1);
treeMap.put(new Person(8, "hameimei"), 2);
treeMap.put(new Person(3, "tom"), 3);
System.out.println(treeMap);
System.out.println(treeMap.get(new Person(3, "xxx")));
}
结果
{{age:1, name:lilei}=1, {age:3, name:tom}=3, {age:8, name:hameimei}=2}
null
史上最清晰的红黑树讲解(上) https://www.cnblogs.com/CarpenterLee/p/5503882.html
Collections和Arrays工具类
Collections.sort() 方法内部是调用 List.sort() 方法,List.sort() 方法内部是调用 Arrays.sort(Object[]) 方法进行排序,也就是最终是通过 Arrays 的对象数组方法进行排序的。
Arrays.sort(int[] a) 基本类型数组排序(双枢轴快速排序)
以下分析都是基于jdk1.8 Arrays中int数组的排序方法Arrays.sort(int[] a)源码如下:
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
其他long,short,char,byte,float,double类型数组的sort()方法也都是调用 DualPivotQuicksort.sort()
但对于不同的基本类型,sort方法的实现又略有差异。
对于int数组来说:
- 如果长度小于286,使用快速排序:
- 如果长度小于47,使用插入排序
- 否则(长度大于47小于286)使用双枢轴快速排序
- 否则(长度大于286),检测数组的顺序性
- 如果顺序连续性好,使用归并排序的变种TimSort算法。TimSort算法的核心在于利用数列中的部分有序。
- 如果顺序连续性不好,使用双轴快排 + 成对插入排序。
JSE1.6及之前,该排序算法是一个经过调优的快速排序法 JSE1.7及之后,使用双枢轴快排
Java DualPivotQuickSort 双轴快速排序 源码 笔记 https://www.cnblogs.com/yuxiaofei93/p/5722714.html
Arrays.sort(Object[] a) 对象数组排序(TimSort)
以下分析都是基于jdk1.8
对于对象数组,
- 如果长度小于32,使用折半插入排序
- 如果长度大于32,使用归并排序的变种TimSort
Collections类中的sort源码:
public static <T> void sort(List<T> list, Comparator<? super T> c) {
list.sort(c);
}
List接口中,sort 方法有一个默认实现,default 方法源码:
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
即先将list转化为数组a,对a利用Arrays.sort()排序,然后遍历数组a把每个元素set到list中
Arrays.sort(Object[] a)源码:
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a); //没有自己的比较器
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0); //有自己的比较器
}
}
//没有自己的比较器时调用的方法
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
即除非指定使用遗留的归并排序,否则都使用TimSort.sort()排序
ComparableTimSort.sort()方法源码:
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen) {
assert a != null && lo >= 0 && lo <= hi && hi <= a.length; //检查lo,hi的的准确性
int nRemaining = hi - lo;
if (nRemaining < 2) //当长度为0或1时永远都是已经排序状态
return; // Arrays of size 0 and 1 are always sorted
// 当数组长度小于MIN_MERGE(32)的时候,就用一个"mini-TimSort"的方法排序,jdk1.7新加
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
// 找出最大的递增或者递减的个数,如果递减,则此段数组严格反一下方向
int initRunLen = countRunAndMakeAscending(a, lo, hi);
binarySort(a, lo, hi, lo + initRunLen); //二分插入排序
return;
}
//数组长度大于32的情况
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*/
ComparableTimSort ts = new ComparableTimSort(a, work, workBase, workLen);
int minRun = minRunLength(nRemaining);
do {
// Identify next run
int runLen = countRunAndMakeAscending(a, lo, hi);
// If run is short, extend to min(minRun, nRemaining)
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
ts.pushRun(lo, runLen);
ts.mergeCollapse();
// Advance to find next run
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
Java源码之Arrays内部排序实现(timsort的实现) https://blog.csdn.net/qq_25673113/article/details/60468364
Arrays.sort和Collections.sort实现原理解析 https://blog.csdn.net/u011410529/article/details/56668545
为什么不同类型采用不同的排序算法?
Arrays.sort() 对基本类型数组和对象数组使用了不同的排序算法,在jdk8中: 1、如果是基本类型数组,例如int数组,长度小于47时使用插入排序,长度大于47小于286时使用双枢轴快速排序,长度大于286时对数组的顺序性进行判断,如果顺序性好使用归并排序的变种TimSort,如果顺序性不好使用双枢轴快速排序。 2、如果是对象数组,长度小于32时使用折半插入排序,长度大于32,使用归并排序的变种TimSort
为什么采用不同算法呢? 1、对Object类型进行排序。快速排序不稳定,对基本类型无影响,对Object类型有影响。归并排序稳定。 因为归并有一个快排没有的优点,就是归并排序是稳定的。对于整型数浮点数,稳定不稳定大概看不出来,但是对于对象,是否稳定很重要。
2、对大数组排序。快速排序的sort()采用递归实现,数组规模太大时会发生堆栈溢出,而归并排序sort()采用非递归实现,不存在此问题。
此外,快排在最坏情况下复杂度为O(n^2),归并排序在任何情况下时间复杂度都是O(nlogn)
为什么复杂对象不使用快速排序呢? 因为对于一个hashcode计算复杂的对象来说,移动的成本远低于比较的成本
jdk7/8对Arrays.sort()的优化?
Colletions.sort()实际会将list转为数组,然后调用Arrays.sort(),排完了再转回List。
JDK6中 Arrays.sort(),对原始类型(int[],double[],char[],byte[]),JDK6里用的是快速排序,对于对象类型(Object[]),JDK6则使用归并排序。为什么要用不同的算法呢?
JDK7的进步 到了JDK7,快速排序升级为双枢轴快排(双枢轴快排 vs 三路快排);归并排序升级为归并排序的改进版TimSort,一个JDK的自我进化。
JDK8的进步 再到了JDK8, 对大集合增加了Arrays.parallelSort()函数,使用fork-Join框架,充分利用多核,对大的集合进行切分然后再归并排序,而在小的连续片段里,依然使用TimSort与DualPivotQuickSort。
集合的线程安全
线程安全:就是当多线程访问时,采用了加锁的机制;即当一个线程访问该类的某个数据时,会对这个数据进行保护,其他线程不能对其访问,直到该线程读取完之后,其他线程才可以使用。防止出现数据不一致或者数据被污染的情况。
线程不安全:就是不提供数据访问时的数据保护,多个线程能够同时操作某个数据,从而出现数据不一致或者数据污染的情况。
线程安全 工作原理: jvm中有一个main memory对象,每一个线程也有自己的working memory,一个线程对于一个变量variable进行操作的时候, 都需要在自己的working memory里创建一个copy,操作完之后再写入main memory。 当多个线程操作同一个变量variable,就可能出现不可预知的结果。
而用synchronized的关键是建立一个监控monitor,这个monitor可以是要修改的变量,也可以是其他自己认为合适的对象(方法),然后通过给这个monitor加锁来实现线程安全,每个线程在获得这个锁之后,要执行完加载load到working memory 到 use && 指派assign 到 存储store 再到 main memory的过程。才会释放它得到的锁。这样就实现了所谓的线程安全。
vector,statck,Hashtable,Collections包装都是加synchronized
并且get方法也都加了synchronized
由于Vector中的add方法和get方法都进行了同步,因此,在有多个线程进行访问时,如果多个线程都只是进行读取操作,那么每个时刻就只能有一个线程进行读取,其他线程便只能等待,这些线程必须竞争同一把锁。
Java并发编程:同步容器 - 海子 http://www.cnblogs.com/dolphin0520/p/3933404.html
通过Collections的同步包装器变成线程安全的
Collections工具类提供了对所有集合进行线程安全包装的静态方法,例如:
static <T> List<T> synchronizedList(List<T> list) //返回指定List对象对应的线程安全的List 对象。
static <K, V> Map<K, V> synchronizedMap(Map<K, V> m) //返回指定Map对象对应的线程安全的Map对象。
static <T> Set<T> synchronizedSet(Set<T> s) //返回指定Set对象对应的线程安全的Set对象。
例如需要在多线程里使用线程安全的HashMap对象(如果需要把某个集合包装成线程安全的集合,则应该在创建之后立即包装),则可以采用如下代码: HashMap m = Collections.synchronizedMap(new HashMap());
同步包装的原理是对原集合类本身的方法加锁,因此这种同步方式的执行效率是很低的。
实现原理: Collections 一堆内部类,比如 SynchronizedCollection ,实现了原 Collection 接口,在其中对所有原方法 都加了 synchronized 锁,锁对象是 this 指针,也就是 当前调用的 集合类实例。
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
final Collection<E> c; // Backing Collection
final Object mutex; // Object on which to synchronize
SynchronizedCollection(Collection<E> c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
...
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
...
}
使用concurrent包的线程安全集合类
java.util.concurrent 包提供了 ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentLinkedQueue、CopyOnWriteArrayList 等线程安全的集合类,这些集合通过复杂的算法,通过允许并发的访问数据结构的不同部分来使竞争极小化。
比如HashMap对应的线程安全类ConcurrentHashMap ArrayList对应的线程安全类CopyOnWriteArrayList
迭代器
每个集合类内部都含有 Iterator<E> iterator() 方法,该方法是返回集合中迭代器对象。
获取迭代器对象后,就可以使用hasNext、next方法操作集合中的元素了(遍历)。
每个集合类内部都含有一个内部类,用来实现Iterator接口。集合类的iterator方法就是在获取内部类对象(迭代器对象),然后通过该对象调用hashNext和next方法实现遍历。
此外,还有一个迭代器 interface ListIterator<E> extends Iterator<E>, 在使用 List, ArrayList, LinkedList 和 Vector 的时候可以使用。
Iterator 接口
package java.util;
import java.util.function.Consumer;
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
ArrayList 的 Iterator
在 ArrayList 内部定义了一个内部类 Itr,该类实现了 Iterator 接口。 调用 list.iterator() 方法时,就是 new 了一个 Itr 类的对象,其中的 cursor 取的是基本类型的默认值0所以也不需要赋初值。
public Iterator<E> iterator() {
return new Itr();
}
Itr 类源码如下:
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
在Itr中,有三个变量分别是 cursor:表示下一个元素的索引位置 lastRet:表示上一个元素的索引位置 expectModCount:预期被修改的次数 实现next()是通过get(cursor),然后cursor++,通过这样实现遍历。
ListIterator 接口
package java.util;
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
ArrayList 的 ListIterator
Iterator 只提供了删除元素的方法remove,如果我们想要在遍历的时候添加元素怎么办? ListIterator 接口继承了 Iterator 接口,它允许程序员按照任一方向遍历列表,迭代期间修改列表,并获得迭代器在列表中的当前位置。
ArrayList 有个内部类 ListItr ,调用 list.listIterator() 方法就是 new 了一个 ListItr 类的对象
public ListIterator<E> listIterator() {
return new ListItr(0);
}
ListItr 源码如下:
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
Java集合Iterator迭代器的实现 http://www.cnblogs.com/xujian2014/p/5846128.html
Iterator 和 ListIterator 对比
一.相同点 都是迭代器,当需要对集合中元素进行遍历不需要干涉其遍历过程时,这两种迭代器都可以使用。
二.不同点
1、使用范围不同,Iterator 可以应用于所有 Collection 的子类,比如 Set, List, Queue 及其子类型。而 ListIterator 只能用于 List 及其子类型。
注意 Map 及其子类并没有实现 Iterable 接口,也就是不可以迭代。
2、ListIterator 有 add 方法,可以向 List 中添加对象,而 Iterator 不能。
3、ListIterator 和 Iterator 都有 hasNext() 和 next() 方法,可以实现顺序向后遍历,但是 ListIterator 有 hasPrevious() 和 previous() 方法,可以实现逆向(顺序向前)遍历。Iterator不可以。
4、ListIterator 可以定位当前索引的位置,nextIndex() 和 previousIndex() 可以实现。Iterator没有此功能。
5、都可实现删除操作,但是 ListIterator 可以实现对象的修改,set() 方法可以实现。Iterator仅能遍历和删除,不能修改。
实现Iterable接口的集合可通过foreach语句遍历
foreach 是 JDK1.5 新增加的一个循环结构,foreach 的出现是为了简化我们遍历集合的行为。
实现 Iterable 接口允许对象成为 Foreach 语句的目标。就可以通过 foreach 语句来遍历你的底层序列。
使用 Foreach 时对集合的结构进行修改会出现异常: 上面我们说了实现了 Iterable 接口的类就可以通过 Foreach 遍历,那是因为 foreach 要依赖于 Iterable 接口返回的 Iterator 对象,所以从本质上来讲,Foreach 其实就是在使用迭代器,在使用 foreach 遍历时对集合的结构进行修改,和在使用 Iterator 遍历时对集合结构进行修改本质上是一样的。所以同样的也会抛出异常,执行快速失败机制。
深入理解Java中的迭代器 https://www.cnblogs.com/zyuze/p/7726582.html
为什么LinkedList用迭代器遍历更快?
for循环get(i),对于ArrayList可随机访问,对于LinkedList,每次get(i)都需要从头开始数到i 迭代器是顺序访问,使用迭代器遍历LinkedList是顺序遍历的,不用每次从头开始数
for循环与迭代器的对比,效率上各有各的优势: ArrayList对随机访问比较快,而for循环中使用的get()方法,采用的即是随机访问的方法,因此在ArrayList里for循环快。 LinkedList则是顺序访问比较快,Iterator中的next()方法采用的是顺序访问方法,因此在LinkedList里使用Iterator较快。 主要还是要依据集合的数据结构不同的判断。
深入理解Java中的迭代器 https://www.cnblogs.com/zyuze/p/7726582.html
Enumeration和Iterator对比
(01) 函数接口不同 Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。 Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。
(02) Iterator支持fail-fast机制,而Enumeration不支持。 Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。 而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
使用Iterator来遍历集合时,应使用Iterator的remove()方法来删除集合中的元素,使用集合的remove()方法将抛出ConncurrentModificationException异常。
Java 集合系列18之 Iterator和Enumeration比较 http://www.cnblogs.com/skywang12345/p/3311275.html
fail-fast 快速失败机制
广义上的fail-fast涉及理念
在系统设计中,快速失效系统一种可以立即报告任何可能表明故障的情况的系统。快速失效系统通常设计用于停止正常操作,而不是试图继续可能存在缺陷的过程。这种设计通常会在操作中的多个点检查系统的状态,因此可以及早检测到任何故障。快速失败模块的职责是检测错误,然后让系统的下一个最高级别处理错误。
其实,这是一种理念,fail-fast就是在做系统设计的时候先考虑异常情况,一旦发生异常,直接停止并上报。
Java集合中的fail-fast
我们通常说的Java中的fail-fast机制,默认指的是Java集合的一种错误检测机制。
“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制,抛出 ConcurrentModificationException 。记住是有可能,而不是一定。
ArrayList, HashMap等类的“collection 视图方法”所返回的迭代器都是快速失败的: 在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出ConcurrentModificationException。 因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险(这就是为什么叫快速失败)。
迭代器的快速失败行为无法得到保证,它不能保证一定会出现该错误,但是快速失败操作会尽最大努力抛出ConcurrentModificationException异常,所以因此,为提高此类操作的正确性而编写一个依赖于此异常的程序是错误的做法,正确做法是:ConcurrentModificationException 应该仅用于检测 bug。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
fail-fast产生的原因就在于程序在对 collection 进行迭代时,某个线程对该 collection 在结构上对其做了修改,这时迭代器就会抛出 ConcurrentModificationException 异常信息,从而产生 fail-fast。
实现原理
这一策略在源码中是通过 modCount 和 expectedModCount 实现的:
modCount 顾名思义就是修改次数,是集合类本身的一个属性(比如 ArrayList 的 modCount 是在其父类 AbstractList 中定义的,HashMap 的 modCount 是其本类的一个属性),对集合内容的修改都将增加这个值(例如 ArrayList 中无论 add, remove, clear 方法只要是涉及了改变 ArrayList 元素的个数的方法都会导致 modCount 加1)。
而expectedModCount 是在迭代器中定义的,在迭代器初始化过程中会将 modCount 赋值给 expectedModCount,所以新获得一个迭代器时其 expectedModCount 值等于 modCount
expectedModCount表示这个迭代器预期该集合被修改的次数。其值随着Itr被创建而初始化。只有通过迭代器对集合进行操作,该值才会改变。
例如HashMap的HashIterator构造函数:
HashIterator() {
expectedModCount = modCount;
...
}
又比如ArrayList的迭代器iterator()
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
}
迭代器在调用 next(), remove() 等方法时,都要判断迭代器自己的 expectedModCount 是否和集合类的 modCount 相等,如果不相等就表示已经有其他线程修改了集合结构(其实也不一定是其他线程,在使用迭代器遍历过程中如果直接通过集合(比如List)的 remove()(注意非迭代器的remove)等操作修改了集合结构也会导致两者不等),就抛出 ConcurrentModificationException 异常,从而产生 fail-fast 机制。
@Test
public void testFastFail() {
ArrayList<String> list = Lists.newArrayList("xxx", "bbb", "ccc");
for (String str : list) {
if (str.equals("ccc")) {
list.remove(str); // throw ConcurrentModificationException
}
}
System.out.println(list);
}
上面代码中, for 循环其实就是通过迭代器遍历元素的,在增强for循环中,集合遍历是通过 iterator 进行的,但是元素的add/remove却是直接使用的集合类自己的方法。这就导致 iterator 在遍历的时候,会发现有一个元素在自己不知不觉的情况下就被删除/添加了,就会抛出一个异常,用来提示用户,可能发生了并发修改!
想在遍历的过程中删除指定元素, 正确的写法应该是完全通过 Iterator 来操作
@Test
public void rightWayToModifyCollection() {
ArrayList<String> list = Lists.newArrayList("xxx", "bbb", "ccc");
for (Iterator<String> iterator = list.iterator(); iterator.hasNext();) {
if (iterator.next().equals("ccc")) {
iterator.remove();
}
}
System.out.println(list);
}
顺便提一句,ArrayList 提供了一个 removeIf() 方法,传入一个 lambda 表达式条件即可删除符合条件的元素
如下:
ArrayList<String> list = Lists.newArrayList("xxx", "bbb", "ccc");
list.removeIf(str -> str.equals("ccc"));
System.out.println(list);
fail-fast解决办法
方案一:使用 Iterator 操作 方案二:使用CopyOnWriteArrayList来替换ArrayList。推荐使用该方案。
Java提高篇(三四)-----fail-fast机制 http://blog.csdn.net/chenssy/article/details/38151189
HashMap 多线程处理之 Fail-Fast机制 http://www.cnblogs.com/alexlo/archive/2013/03/14/2959233.html
关于快速报错fail-fast想说的之fail-fast的实现原理(一) http://blog.csdn.net/fan2012huan/article/details/51076970
Hashtable支持fastfail机制吗?
Hashtable的iterator遍历方式支持fast-fail,用Enumeration不支持fast-fail
一不小心就让Java开发者踩坑的fail-fast是个什么鬼? - Hollis https://mp.weixin.qq.com/s/p1u2f3sw6y2MtsxTaBRkQA
选择合适的集合类
容器类和Array(数组)的区别、择取 容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。 一旦将对象置入容器内,便损失了该对象的型别信息。
在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList(); Vector总是比ArrayList慢,所以要尽量避免使用。
在各种Sets中,HashSet通常优于TreeSet(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。 TreeSet存在的唯一理由:能够维护其内元素的排序状态。
在各种Maps中 HashMap用于快速查找。
当元素个数固定,用Array,因为Array效率是最高的。
结论:最常用的是ArrayList,HashSet,HashMap,Array。而且,我们也会发现一个规律,用TreeXXX都是排序的。
注意: 1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。 2、Set和Collection拥有一模一样的接口。 3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get) 4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。 5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。 HashMap会利用对象的hashCode来快速找到key。 6、Map中元素,可以将key序列、value序列单独抽取出来。 使用keySet()抽取key序列,将map中的所有keys生成一个Set。 使用values()抽取value序列,将map中的所有values生成一个Collection。 为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。
java的集合框架最全详解 https://www.cnblogs.com/565261641-fzh/p/5659783.html