面试准备12-计算机基础
面试准备之计算机基础与组成原理
相关书籍
唐朔飞-计算机组成原理(第二版).pdf 带目录 计算机网络第五版.pdf 数据结构 C语言 严蔚敏 pdf https://github.com/CroMarmot/kaoyanziliao/tree/master/912computer
CPU多级缓存
CPU多级缓存 https://blinkfox.github.io/2018/11/18/ruan-jian-gong-ju/cpu-duo-ji-huan-cun/
并发研究之CPU缓存一致性协议(MESI) https://www.cnblogs.com/yanlong300/p/8986041.html
局部性原理
在 CPU 访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
时间局部性(Temporal Locality): 如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如循环、递归、方法的反复调用等。
空间局部性(Spatial Locality): 如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。
高速缓存/缓存行(Cache Line)
CPU 运算速度远高于内存读写速度,这会导致 CPU 花费很长的时间等待数据的到来或把数据写入到内存中。 因此,CPU 厂商在 CPU 中增加了高速缓存以解决 I/O 速度和 CPU 运算速度之间的不匹配问题。
高速缓存容量比内存小的多但是交换速度却比内存要快得多,一般直接跟 CPU 芯片集成或位于主板总线互连的独立芯片上。
高速缓存以数据块为单位,称为 缓存行(Cache Line),通常大小为 64 字节(bytes) 所以 CPU 使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU 存取缓存都是按照一个缓存行为最小单位操作的。
带有高速缓存的CPU执行计算的流程:
- 程序以及数据被加载到主内存
- 指令和数据被加载到CPU的高速缓存
- CPU执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
Linux 中执行命令 getconf LEVEL1_DCACHE_LINESIZE 可查看缓存行大小,为 64 字节。
伪共享问题
伪共享(False Sharing)问题是多线程并发编程中的一个重要概念,它是由于 CPU 缓存系统(主要是多级缓存,如L1、L2、L3等)的工作原理引起的。
在现代多核CPU中,每个核都有自己的缓存系统,为了提高内存访问的速度,CPU不是直接读取单个内存地址,而是读取一个内存块,也就是一 缓存行(Cache Line),这个内存块的大小通常是 64 字节。当多个线程修改互相独立的变量时,如果这些变量恰好位于同一个缓存行中,就会导致伪共享问题。
为什么会导致问题呢?因为当一个线程修改了某个缓存行中的数据,会导致其它 CPU 的对应缓存行失效(缓存一致性协议),然后其它 CPU 在访问这些变量时,需要从主内存重新加载这个缓存行。这样,即使这些变量是独立的,没有数据竞争,由于频繁的缓存同步,也会大大降低程序的执行效率。
如何解决伪共享问题呢?一种常见的方式是通过缓存行填充,也就是在变量之间填充一些无用的数据,使得 单个变量可以独占一个缓存行
Java 中的高性能队列 Disruptor 和 JCTools 中都使用了缓存行填充来避免伪共享问题。
Java 8 引入了 @Contended 注解来解决伪共享问题,通过这个注解标记的字段会尽可能地分布在不同的缓存行中。
@sun.misc.Contended
public final static class Test {
public volatile long test = 0L;
}
需要 JVM 参数开启 -XX:-RestrictContended
三级缓存架构
Intel CPU 三级缓存架构如图:
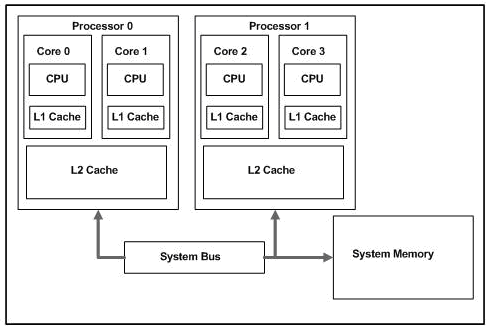
Intel CPU 三级缓存架构
级别越小的缓存,越接近 CPU, 意味着速度越快且容量越少。
L1 是最接近 CPU 的,它容量最小(例如 32K),速度最快,每个逻辑核(Core)上都有一个 L1 Cache (准确地说每个核上有两个 L1 Cache, 一个存数据的 L1 Data Cache, 一个存指令的 L1 Instruction Cache)。L1 缓存是逻辑核(Core)独占的
L2 Cache 更大一些(例如 256K),速度要慢一些,一般情况下每个物理 CPU(Processor) 上都有一个独立的 L2 Cache. 二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些 CPU 处理时需要用到、一级缓存又无法存储的数据。L2 缓存是物理核(Processor)独占,逻辑核(Core)共享的
L3 Cache 是三级缓存中最大的一级(例如 12MB),同时也是最慢的一级,在同一个 CPU 插槽之间的核共享一个 L3 Cache. 三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。L3 缓存在同一CPU插槽间共享
L3 Cache 和 L1, L2 Cache有着本质的区别。L1 和 L2 Cache 都是每个 CPU core 独立拥有一个,而 L3 Cache 是几个 Cores 共享的,可以认为是一个更小但是更快的内存。
当 CPU 运作时,它首先去 L1 寻找它所需要的数据,然后去 L2, 然后去 L3. 如果三级缓存都没找到它需要的数据,则从内存里获取数据。寻找的路径越长,耗时越长。所以如果要非常频繁的获取某些数据,保证这些数据在 L1 缓存里。这样速度将非常快。
CPU 到各缓存和内存之间的大概速度:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间(单位ns) |
|---|---|---|
| 寄存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 跨槽传输 | ~20 ns | |
| 内存 | ~120-240 cycles | ~60-120ns |
缓存一致性问题
高速缓存给系统带来性能上飞跃的同时,也引入了新的问题“缓存一致性问题”。
多核 CPU 的情况下存在多个一级缓存,比如 coreA 和 coreB 均从主存上读取了变量 A=0, 此时 coreA 执行 A++, A 缓存中的值为 1, 但此时 coreB 缓存中变量的值任为 0, 导致缓存不一致的问题。
解决缓存一致性最常见的方案是 总线嗅探(Bus Snooping) 比如当 CPU0 修改自己私有的 Cache 时,硬件就会广播通知到总线上其他所有的 CPU. 对于每个 CPU 来说会有特殊的硬件监听广播事件,并检查是否有相同的数据被缓存在自己的 CPU, 这里是指 CPU1. 如果 CPU1 私有 Cache 已经缓存即将修改的数据,那么 CPU1 的私有 Cache 也需要更新对应的 cache line。这个过程就称作bus snooping.
总线嗅探方法简单,但要需要每时每刻监听总线上的一切活动,无论广播中的数据是否被本 CPU 私有 Cache, 这在一定程度上加重了总线负载,也增加了读写延迟。
另一种基于总线嗅探机制的 MESI 协议。一种基于写失效(发生更新的时候对应内存地址缓存失效,不需要传递真实的数据)的缓存一致性协议。写失效的协议的好处是,我们不需要在总线上传输数据内容,而只需要传输操作信号和地址信号就好了,不会那么占总线带宽。
缓存一致性协议MESI
MESI(Modified Exclusive Shared Or Invalid), 也称为伊利诺伊协议(Illinois Protocol, 是因为该协议由伊利诺伊州立大学提出的)是一种广泛使用的支持写回策略的缓存一致性协议。
为了保证多个 CPU 缓存中共享数据的一致性,定义了 缓存行(Cache Line) 的四种状态,而 CPU 对缓存行的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的缓存行的状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
缓存行(Cache Line) 的 4 种状态:
M 修改 (Modified): 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S(共享)状态之前被延迟执行。
E 独享、互斥 (Exclusive): 该 Cache line 有效,数据和内存中的数据一致,数据只存在于本 Cache 中。缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成 S(共享)状态。
S 共享 (Shared): 该 Cache line 有效,数据和内存中的数据一致,数据存在于很多 Cache 中。缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。
I 无效 (Invalid): 该 Cache line 无效。
MESI带来的问题
缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
比如你需要修改本地缓存中的一条信息,那么你必须将 I(无效)状态通知到其他拥有该缓存数据的 CPU 缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。因为这个等待远远比一个指令的执行时间长的多。所以,为了为了避免这种阻塞导致时间的浪费,引入了 存储缓存(Store Buffer) 和 无效队列(Invalidate Queue)
存储缓存(Store Buffer)
存储缓存(Store Buffer)用于解决 CPU 写入阻塞问题。
处理器把它想要写入到主存的值写到 Buffer 中,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有两个风险: 第一、就是处理器会尝试从存储缓存(Store buffer)中读取值,如果存储缓存中存在,则进行返回,这种优化叫 Store Forwarding 第二、保存什么时候会完成,这个并没有任何保证。
无效队列(Invalidate Queue)
同理,解决了主动发送信号端的效率问题,那么,接受端 CPU 接受到 Invalidate 信号后如果立即采取相应行动(去其它 CPU 同步值),再返回响应信号,则时钟周期也太长了,此处也可优化。接受端 CPU 接受到信号后不是立即采取行动,而是将 Invalidate 信号插入到一个队列 Queue 中,立即作出响应。等到合适的时机,再去处理这个 Queue 中的 Invalidate 信号,并作相应处理。这个 Queue 就是Invalidate Queue。
乱序执行
乱序执行(out-of-order execution): 是指 CPU 允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。这样将根据各电路单元的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令立即发送给相应电路。
乱序执行的目的是为了提高效率,将长费时的操作“异步”执行,排在后面的指令不等前面的指令执行完毕就开始执行后面的指令。而且允许排在前面的长费时指令后于排在后面的指令执行完。
CPU 执行乱序主要有以下几种:
- 写写乱序(store store): a=1;b=2; -> b=2;a=1;
- 写读乱序(store load): a=1;load(b); -> load(b);a=1;
- 读读乱序(load load): load(a);load(b); -> load(b);load(a);
- 读写乱序(load store): load(a);b=2; -> b=2;load(a);
内存屏障(Memory Barriers)
内存屏障(Memory Barriers) 与 内存栅栏(Memory Fence) 是同一概念不同的叫法。
写屏障(Store Memory Barrier, ST, SMB, smp_wmb) 是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer) 中的保存的指令。在指令后插入 Store Barrier, 能让写入缓存中的最新数据更新写入主内存,让其他线程可见。强制写入主内存,这种显示调用,CPU就不会因为性能考虑而去对指令重排。
读屏障(Load Memory Barrier, LD, RMB, smp_rmb) 是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令。在指令前插入 Load Barrier, 可以让高速缓存中的数据失效,强制从主内存加载数据。强制读取主内存内容,让CPU缓存与主内存保持一致,避免了缓存导致的一致性问题。
Intel x86 提供的 CPU 内存屏障指令:
- sfence, 实现 Store Barrior, 会将 store buffer 中缓存的修改刷入 L1 cache 中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
lfence, 实现 Load Barrior 会将 invalidate queue 失效,强制读取入 L1 cache 中,而且 lfence 之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
mfence, 实现 Full Barrior, 同时刷新 store buffer 和 invalidate queue, 保证了mfence前后的读写操作的顺序,同时要求mfence之后写操作结果全局可见之前,mfence之前写操作结果全局可见;
lock 用来修饰当前指令操作的内存只能由当前CPU使用,若指令不操作内存仍然由用,因为这个修饰会让指令操作本身原子化,而且自带Full Barrior效果;还有指令比如IO操作的指令、exch等原子交换的指令,任何带有lock前缀的指令以及CPUID等指令都有内存屏障的作用。
进制
BIN, binary, 二进制bai的; OCT, octal, 八进制的; HEX, hexadecimal, 十六进制的; DEC, decimal, 十进制的。
原码反码补码
机器数和真值
一个数在计算机中的二进制表示形式, 叫做这个数的机器数。 机器数是带符号的,在计算机用一个数的最高位存放符号, 正数为0, 负数为1
因为第一位是符号位,所以机器数的形式值就不等于真正的数值。 所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
对于一个数, 计算机要使用一定的编码方式进行存储. 原码, 反码, 补码是机器存储一个具体数字的编码方式。
原码
原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
原码就是符号位加上数字的二进制表示,int为例,第一位表示符号 (0正数 1负数)
n+1位原码的表示范围为 -(2^n - 1) ~ 2^n - 1
简单起见一个字节表示 +7的原码为: 00000111 -7的原码为: 10000111 对于原码来说,绝对值相等的正数和负数只有符号位不同。
反码
正数的反码是其本身。
负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。
换言之 该数的绝对值取反(绝对值取反各位都取反)。
n+1位反码的表示范围为 -(2^n - 1) ~ 2^n - 1
为了简单起见,我们用1个字节来表示一个整数: +7的反码为: 00000111 -7的反码为: 11111000
补码
正数的补码就是其本身。
负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后加1,即在反码的基础上加1
n+1位补码的表示范围为 -2^n ~ 2^n - 1
为了简单起见,我们用1个字节来表示一个整数: +7的补码为: 00000111 -7的补码为: 11111001
补码可以在负数上多表示一位。 比如8位二进制的话,补码1000 0000 表示 -128=-2^7,即n+1位二进制补码可表示的最小负数为 -2^n。 注意补码表示的最小负值(符号位为1,其余全是0)不能使用正常的规则转换为反码和原码,因为反码和补码无法表示此数。
总结 正数的原码、反码、补码相同 负数反码是原码符号位不变化其余各位数取反,负数的补码是原码符号位不变其余各位取反加1,即反码加1
原码, 反码, 补码 详解 https://blog.csdn.net/zq602316498/article/details/39404043