Java-线程与线程池
创建并使用线程 Thread
Java 线程的5种状态及转换
线程从创建到最终的消亡,要经历若干个状态。一般来说,线程包括以下这几个状态:
Thread 类内部有个 State 枚举定义线程的状态:
public class Thread implements Runnable {
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
}
新建(NEW)
新创建了一个线程对象。
当需要新起一个线程来执行某个子任务时,就创建了一个线程。但是线程创建之后,不会立即进入就绪状态,因为线程的运行需要一些条件(比如内存资源,JVM内存区域划分中程序计数器、Java栈、本地方法栈都是线程私有的,所以需要为线程分配一定的内存空间),只有线程运行需要的所有条件满足了,才进入就绪状态。
可运行(RUNNABLE)或就绪
线程对象创建后,其他线程(比如 main 线程)调用了该对象的 start() 方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取 cpu 的使用权 。
当线程进入就绪状态后,不代表立刻就能获取 CPU 执行时间,也许此时 CPU 正在执行其他的事情,因此它要等待。当得到CPU执行时间之后,线程便真正进入运行状态。
运行(RUNNING)
可运行状态(runnable)的线程获得了 cpu 时间片(timeslice),执行程序代码。
阻塞(BLOCKED)
线程在等待 monitor 锁时会进入 blocked 状态。
阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。
阻塞的情况分三种:
- 等待阻塞(wait):运行(running)的线程执行 o.wait() 方法,JVM会把该线程放入等待队列(waitting queue)中。
- 同步阻塞(等待synchronized,Lock):运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
- 其他阻塞(sleep等):运行(running)的线程执行 Thread.sleep(long ms) 或 t.join() 方法,或者发出了 I/O 请求时,JVM会把该线程置为阻塞状态。当 sleep() 状态超时、join() 等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
等待(WAITING)
执行下面方法会让线程进入 waiting 状态:
- Object.wait
- Thread.join
- LockSupport.park
waiting 状态的线程
死亡(DEAD)
线程run()、main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
java线程状态装换图
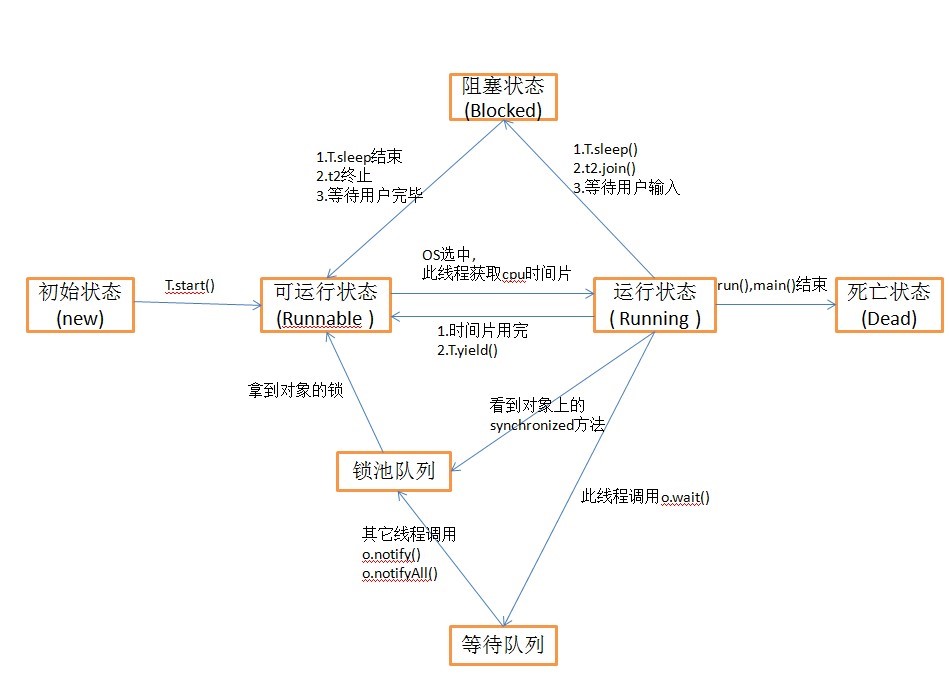
java线程状态装换图
Java线程的5种状态及切换(透彻讲解)
http://blog.csdn.net/pange1991/article/details/53860651
Thread 类常用方法
Java并发编程:Thread类的使用 - 海子
http://www.cnblogs.com/dolphin0520/p/3920357.html
Java线程的5种状态及切换(透彻讲解)
http://blog.csdn.net/pange1991/article/details/53860651
java.lang.Thread
public class Thread extends Object implements Runnable
Java 虚拟机允许应用程序并发地运行多个执行线程。
每个线程都有一个优先级,高优先级线程的执行优先于低优先级线程。每个线程都可以或不可以标记为一个守护程序。当某个线程中运行的代码创建一个新 Thread 对象时,该新线程的初始优先级被设定为创建线程的优先级,并且当且仅当创建线程是守护线程时,新线程才是守护程序。
每个线程都有一个标识名,多个线程可以同名。如果线程创建时没有指定标识名,就会为其生成一个新名称。
构造方法
public Thread(Runnable target) 自动生成的线程名是 "Thread-"
public Thread(Runnable target, String name) 指定线程名
public Thread(ThreadGroup group, Runnable target, String name)
分配新的 Thread 对象,以便将 target 作为其运行对象,将指定的 name 作为其名称,并作为 group 所引用的线程组的一员。
如果 group 为 null,并且有安全管理器,则该组由安全管理器的 getThreadGroup 方法确定。如果 group 为 null,并且没有安全管理器,或安全管理器的 getThreadGroup 方法返回 null,则该组与创建新线程的线程被设定为相同的 ThreadGroup。
如果有安全管理器,则其 checkAccess 方法通过 ThreadGroup 作为其参数被调用。
此外,当被重写 getContextClassLoader 或 setContextClassLoader 方法的子类构造方法直接或间接调用时,其 checkPermission 方法通过 RuntimePermission("enableContextClassLoaderOverride") 权限调用。其结果可能是 SecurityException。
如果 target 参数不是 null,则 target 的 run 方法在启动该线程时调用。如果 target 参数为 null,则该线程的 run 方法在该线程启动时调用。
新创建线程的优先级被设定为创建该线程的线程的优先级,即当前正在运行的线程的优先级。方法 setPriority 可用于将优先级更改为一个新值。
当且仅当创建新线程的线程当前被标记为守护线程时,新创建的线程才被标记为守护线程。方法 setDaemon 可用于改变线程是否为守护线程。
public Thread(ThreadGroup group, Runnable target, String name, long stackSize)
run()
public void run()
如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。Thread 的子类应该重写该方法。
start()
public void start()
使该线程开始执行;Java 虚拟机调用该线程的 run 方法。
结果是两个线程并发地运行;当前线程(从调用返回给 start 方法)和另一个线程(执行其 run 方法)
多次启动一个线程是非法的。特别是当线程已经结束执行后,不能再重新启动。
sleep()睡眠阻塞不释放锁
sleep(long millis)
Thread.sleep(long millis),一定是当前线程调用此方法,当前线程进入阻塞,但不释放对象锁,millis后线程自动苏醒进入可运行状态。
作用:给其它线程执行机会的最佳方式。
TimeUnit.SECONDS.sleep()延时
TimeUnit 是 java.util.concurrent 包下面的一个类,表示给定单元粒度的时间段
主要作用
1、时间颗粒度转换
2、sleep() 一段时间 ,例如 TimeUnit.SECONDS.sleep5);,起内部也是调用 Thread.sleep() 实现的
TimeUnit.SECONDS.sleep5); 和 Thread.sleep(5 * 1000); 没有任何区别,只不过使用 TimeUnit 可读性更高些。
yield交出时间片不阻塞不释放锁
Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的cpu时间片,由运行状态变会可运行状态,让OS再次选择线程。
作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证 yield() 达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
Thread.yield()不会导致阻塞。
调用yield方法会让当前线程交出CPU权限,让CPU去执行其他的线程。它跟sleep方法类似,同样不会释放锁。但是yield不能控制具体的交出CPU的时间,另外,yield方法只能让拥有相同优先级的线程有获取CPU执行时间的机会。
注意,调用yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态,它只需要等待重新获取CPU执行时间,这一点是和sleep方法不一样的。
join阻塞其他线程
t.join()/t.join(long millis),当前线程里调用其它线程t的join方法,当前线程阻塞,但不释放对象锁,直到线程1执行完毕或者millis时间到,当前线程进入可运行状态。
假如在main线程中,调用thread.join方法,则main方法会等待thread线程执行完毕或者等待一定的时间。如果调用的是无参join方法,则等待thread执行完毕,如果调用的是指定了时间参数的join方法,则等待一定的事件。
实际上调用join方法是调用了Object的wait方法,这个可以通过查看源码得知。
wait方法会让线程进入阻塞状态,并且会释放线程占有的锁,并交出CPU执行权限。由于wait方法会让线程释放对象锁,所以join方法同样会让线程释放对一个对象持有的锁。
主线程等待子线程执行结束
下面是生产者消费者中的代码片段,主线程需要调用两个子线程的 join() 方法才能实现等待子线程执行结束,否则下面的测试代码直接就会执行完成,看不到子线程中的结果。
@Test
public void test() throws Exception {
blockingQueue = new LinkedBlockingDeque<>(10);
Producer producer = new Producer();
Consumer consumer = new Consumer();
producer.start();
consumer.start();
// 主线程等待生产者和消费组执行结束
producer.join();
consumer.join();
}
join方法会使得被阻塞线程释放对象锁吗
有一个疑问,join方法会使得被阻塞线程释放对象锁吗?
join 是一个同步方法,调用join的时候会获取调用主体的对象锁,即t1.join() 会先获取t1对象锁,然后join内部进行wait释放锁。
1.如果外部线程已经持有了非t1的锁,调用join是不会释放非t1锁的
2.如果外部线程恰好持有了t1对象锁,那么调用t1.join会释放,此时外部线程不在持有t1对象锁。
wait阻塞释放锁
obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout)timeout时间到自动唤醒。
wait方法会让线程进入阻塞状态,并且会释放线程占有的锁,并交出CPU执行权限。
notify唤醒1个等待此对象的线程
obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
直接调用interrupt方法不能中断正在运行中的线程。
interrupt()中断
interrupt() 这个方法通过修改被调用线程的中断状态来告知那个线程,说它被中断了。
- 对于非阻塞中的线程, 只是改变了中断状态, 即
Thread.isInterrupted()将返回true; - 对于可取消的阻塞状态中的线程, 比如等待在Thread.sleep(), Object.wait(), Thread.join()这些函数上的线程,这个线程收到中断信号后, 会抛出
InterruptedException, 同时会把中断状态置回为true
中断处于阻塞状态的线程(抛InterruptedException异常)
利用 interrupt() 方法对于阻塞中的线程会抛出 InterruptedException 异常的特点来中断处于阻塞状态的线程:
@Override
public void run() {
try {
while (true) {
// 执行任务...
}
} catch (InterruptedException ie) {
// 由于产生InterruptedException异常,退出while(true)循环,线程终止!
}
}
此时,外部调用线程的interrupt()即可中断阻塞中的线程。
中断处于运行状态的线程(只修改标志位)
注意:直接调用 interrupt() 方法不能中断正在运行中的线程,因为 interrupt() 只是修改线程的中断状态标志位,并不会使线程停止。
通常,我们通过“标记”方式终止处于“运行状态”的线程。
方法一、通过“中断标记”终止线程。
public class Thread3 extends Thread{
public void run(){
while(true){
if(Thread.currentThread().isInterrupted()){
System.out.println("Someone interrupted me.");
break;
}
else{
System.out.println("Thread is Going...");
//do something
}
}
}
}
方法二、通过自定义标记终止线程
private volatile boolean flag= true;
protected void stopTask() {
flag = false;
}
@Override
public void run() {
while (flag) {
// 执行任务...
}
}
理解java线程的中断(interrupt)
https://blog.csdn.net/canot/article/details/51087772
Java多线程系列--“基础篇”09之 interrupt()和线程终止方式
https://www.cnblogs.com/skywang12345/p/3479949.html
Thread 类属性及源码
priority:5 优先级
private int priority;
daemon:false 是否守护线程
private boolean daemon = false;
threadLocals 此线程的本地变量
ThreadLocal.ThreadLocalMap threadLocals = null;
inheritableThreadLocals 此线程的可继承本地变量
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
package java.lang;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.WeakReference;
import java.security.AccessController;
import java.security.AccessControlContext;
import java.security.PrivilegedAction;
import java.util.Map;
import java.util.HashMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.locks.LockSupport;
import sun.nio.ch.Interruptible;
import sun.reflect.CallerSensitive;
import sun.reflect.Reflection;
import sun.security.util.SecurityConstants;
public class Thread implements Runnable {
private volatile String name;
// 优先级
private int priority;
public final static int MIN_PRIORITY = 1;
public final static int NORM_PRIORITY = 5;
public final static int MAX_PRIORITY = 10;
private Thread threadQ;
private long eetop;
/* Whether or not to single_step this thread. */
private boolean single_step;
/* Whether or not the thread is a daemon thread. */
private boolean daemon = false;
/* JVM state */
private boolean stillborn = false;
/* What will be run. */
private Runnable target;
/* The group of this thread */
private ThreadGroup group;
/* The context ClassLoader for this thread */
private ClassLoader contextClassLoader;
/* The inherited AccessControlContext of this thread */
private AccessControlContext inheritedAccessControlContext;
/* For autonumbering anonymous threads. */
private static int threadInitNumber;
private static synchronized int nextThreadNum() {
return threadInitNumber++;
}
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
/*
* The requested stack size for this thread, or 0 if the creator did
* not specify a stack size. It is up to the VM to do whatever it
* likes with this number; some VMs will ignore it.
*/
private long stackSize;
/*
* JVM-private state that persists after native thread termination.
*/
private long nativeParkEventPointer;
/*
* Thread ID
*/
private long tid;
/* For generating thread ID */
private static long threadSeqNumber;
/* Java thread status for tools,
* initialized to indicate thread 'not yet started'
*/
private volatile int threadStatus = 0;
}
线程优先级与守护线程
JAVA中线程的优先级
Thread 类中有个成员 priority,表示线程的优先级,最大值为10,最小值为1,默认值为5,值越大优先级越高
private int priority;
每个线程都有一个优先级。“高优先级线程”会优先于“低优先级线程”执行。
创建新的子线程时,子线程的优先级被设置为等于“创建它的主线程的优先级”
线程的优先级仍然无法保障线程的执行次序。只不过,优先级高的线程获取CPU资源的概率较大,优先级低的并非没机会执行。
优先级高的线程不一定先执行
JAVA中设置了线程优先级,能保证这个线程一定先执行吗?
其实,即使设置了线程的优先级,一样无法确保这个线程一定先执行,因为它有很大的随机性。它并无法控制执行哪个线程,因为线程的执行,是抢占资源后才能执行的操作,而抢点资源时,最多是给于线程优先级较高的线程一点机会而已,能不能抓住可是不一定的。。
说到底就一句话:线程优化级较高的线程不一定先执行。
守护线程与非守护线程的区别
Java 的线程分为两种:User Thread(用户线程)、DaemonThread(守护线程)。
只要当前JVM实例中尚存任何一个非守护线程没有结束,守护线程就全部工作;当最后一个非守护线程结束时,守护线程随着JVM一同结束工作,Daemon 作用是为其他线程提供便利服务,守护线程最典型的应用就是GC(垃圾回收器),他就是一个很称职的守护者。
User 和 Daemon 两者几乎没有区别,唯一的不同之处就在于虚拟机的离开:如果 User Thread 已经全部退出运行了,只剩下 Daemon Thread 存在了,虚拟机也就退出了。 因为没有了被守护者,Daemon 也就没有工作可做了,也就没有继续运行程序的必要了。
优先级:
守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。
将线程转换为守护线程可以通过调用 Thread 对象的 setDaemon(true) 方法来实现。在使用守护线程时需要注意一下几点:
(1) thread.setDaemon(true) 必须在 thread.start() 之前设置,否则会跑出一个 IllegalThreadStateException 异常。你不能把正在运行的常规线程设置为守护线程。
(2) 在 Daemon 线程中产生的新线程也是 Daemon 的。
(3) 守护线程应该永远不去访问固有资源,如文件、数据库,因为它会在任何时候甚至在一个操作的中间发生中断。
守护线程有一个应用场景,就是当主线程结束时,结束其余的子线程(守护线程)自动关闭,就免去了还要继续关闭子线程的麻烦。不过博主推荐,如果真有这种场景,还是用中断的方式实现比较合理。
setDaemon()
public final void setDaemon(boolean on)
将该线程标记为守护线程或用户线程。当正在运行的线程都是守护线程时,Java 虚拟机退出。
该方法必须在启动线程前调用。
该方法首先调用该线程的 checkAccess 方法,且不带任何参数。这可能抛出 SecurityException(在当前线程中)。
参数: on - 如果为 true,则将该线程标记为守护线程。
抛出:
IllegalThreadStateException - 如果该线程处于活动状态。
SecurityException - 如果当前线程无法修改该线程。
Java中守护线程的总结
https://blog.csdn.net/shimiso/article/details/8964414
区别守护进程与守护线程
先把 守护线程 与 守护进程 这二个极其相似的说法区分开,
守护进程通常是为了防止某些应用因各种意外原因退出,而在后台独立运行的系统服务或应用程序。 比如:我们开发了一个邮件发送程序,一直不停的监视队列池,发现有待发送的邮件,就将其发送出去。如果这个程序挂了(或被人误操作关了),邮件就不发出去了,为了防止这种情况,再开发一个类似windows 系统服务的应用,常驻后台,监制这个邮件发送程序是否在运行,如果没运行,则自动将其启动。
而我们今天说的java中的守护线程(Daemon Thread) 指的是一类特殊的Thread,其优先级特别低(低到甚至可以被JVM自动终止),通常这类线程用于在空闲时做一些资源清理类的工作,比如GC线程,如果JVM中所有非守护线程(即:常规的用户线程)都结束了,守护线程会被JVM中止,想想其实也挺合理,没有任何用户线程了,自然也不会有垃圾对象产生,GC线程也没必要存在了。
java并发编程学习: 守护线程(Daemon Thread)
https://www.cnblogs.com/yjmyzz/p/daemon-thread-demo.html
Java中创建线程的三种方法
Java使用Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。Java可以用三种方式来创建线程,如下所示:
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
java中创建线程的三种方法以及区别
https://www.cnblogs.com/3s540/p/7172146.html
继承Thread类,重写run方法
通过继承Thread类来创建并启动多线程的一般步骤如下:
1、定义Thread类的子类,并重写该类的run()方法,该方法的方法体就是线程需要完成的任务,run()方法也称为线程执行体。
2、创建Thread子类的实例,也就是创建了线程对象
3、启动线程,即调用线程的start()方法
public class MyThread extends Thread{//继承Thread类
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
new MyThread().start();//创建并启动线程
}
}
或者使用匿名类,写起来更简洁:
public class Main {
public static void main(String[] args){
new Thread(){
@Override
public void run() {
//重写run方法
};
}.start();
}
}
实现Runnable接口,放入Thread类中
通过实现Runnable接口创建并启动线程一般步骤如下:
1、定义Runnable接口的实现类,一样要重写run()方法,这个run()方法和Thread中的run()方法一样是线程的执行体
2、创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程对象
3、第三部依然是通过调用线程对象的start()方法来启动线程
public class MyThread2 implements Runnable {//实现Runnable接口
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
//创建并启动线程
MyThread2 myThread = new MyThread2();
Thread thread = new Thread(myThread);
thread().start();
//或者 new Thread(new MyThread2()).start();
}
}
或者直接使用匿名内部类,写起来更简洁:
public class Main {
public static void main(String[] args){
new Thread(new Runnable(){
@Override
public void run(){
//重写run方法
}
}
).start();
}
}
为什么不能直接调用Runnable接口的run()方法运行?
常见错误:调用run()方法而非start()方法
创建并运行一个线程所犯的常见错误是调用线程的run()方法而非start()方法,如下所示:
Thread newThread = new Thread(MyRunnable());
newThread.run(); //should be start();
起初你并不会感觉到有什么不妥,因为run()方法的确如你所愿的被调用了。但是,事实上,run()方法并非是由刚创建的新线程所执行的,而是被创建新线程的当前线程所执行了。也就是被执行上面两行代码的线程所执行的。想要让创建的新线程执行run()方法,必须调用新线程的start方法。
run方法中只是定义需要执行的任务,如果直接调用run方法,即相当于在主线程中执行run方法,跟普通的方法调用没有任何区别,此时并不会创建一个新的线程来执行定义的任务。
使用Callable和Future
使用Callable和Future创建并启动有返回值的线程有两种方法
一、利用FutureTask封装Callable再由Thread启动,详细步骤如下:
1、创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
2、使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
3、使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
4、调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
二、利用ExecutorService的submit提交Callable任务到线程池执行
详见Callable接口的使用
三种创建线程方法对比
实现Runnable和实现Callable接口的方式基本相同,只不过是后者是执行call()方法有返回值,前者是执行体run()方法无返回值,因此可以把这两种方式归为一种这种方式与继承Thread类的方法之间的差别如下:
1、线程只是实现Runnable或实现Callable接口,还可以继承其他类。
2、这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
3、但是编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
4、继承Thread类的线程类不能再继承其他父类(Java单继承决定)。
注:一般推荐采用实现接口的方式来创建多线程
java中创建线程的三种方法以及区别
https://www.cnblogs.com/3s540/p/7172146.html
线程工厂
创建Thread需要哪些参数
Thread 类参数最全的构造方法如下,需要四个参数:
public Thread(ThreadGroup group, Runnable target, String name, long stackSize)
ThreadGroup group:线程组。如果 group 为 null,并且有安全管理器,则该组由安全管理器的 getThreadGroup 方法确定。如果 group 为 null,并且没有安全管理器,或安全管理器的 getThreadGroup 方法返回 null,则该组与创建新线程的线程被设定为相同的 ThreadGroup。
Runnable target:线程的执行体。如果 target 参数不是 null,则 target 的 run 方法在启动该线程时调用。如果 target 参数为 null,则该线程的 run 方法在该线程启动时调用。
String name:新线程的名称。
long stackSize:新线程的预期堆栈大小,为零时表示忽略该参数。
新创建线程的优先级被设定为创建该线程的线程的优先级,即当前正在运行的线程的优先级。方法 setPriority 可用于将优先级更改为一个新值。
最大值为10,最小值为1,默认值为5
当且仅当创建新线程的线程当前被标记为守护线程时,新创建的线程才被标记为守护线程。方法 setDaemon 可用于改变线程是否为守护线程。
使用线程工厂创建线程有什么好处?
为什么要使用线程工厂呢?
其实就是为了统一在创建线程时设置一些参数,如是否守护线程。设置线程的一些特性等,如优先级、线程组、线程名称(比如我们想使用统一的名称前缀)、线程栈大小。以及还能增加一些线程统计特性。
ThreadFactory
java 提供了一个 ThreadFactory 接口,他只有一个方法,就是创建一个线程
public interface ThreadFactory {
Thread newThread(Runnable r);
}
我们可以继承ThreadFactory接口来实现自己的线程工厂
011-ThreadFactory线程工厂
https://www.cnblogs.com/bjlhx/p/7609100.html
ThreadFactoryBuilder
使用 ThreadFactoryBuilder 可以更方便的创建线程工厂:
com.google.common.util.concurrent.ThreadFactoryBuilder
ThreadFactory tf = new ThreadFactoryBuilder().setNameFormat("masikkk.com-%d").build();
Executors 的默认线程工厂
Java并发API的一些高级工具,如执行者框架(Executor framework)或Fork/Join框架(Fork/Join framework),都使用线程工厂创建线程。
比如ThreadPoolExecutor类就有个参数是ThreadFactory,我们可以传入自己定义的线程工厂。
下面来看看Executors类的默认线程工厂, 我们创建线程池时使用的就是这个线程工厂
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);//原子类,线程池编号
private final ThreadGroup group;//线程组
private final AtomicInteger threadNumber = new AtomicInteger(1);//线程数目
private final String namePrefix;//为每个创建的线程添加的前缀
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();//取得线程组
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);//真正创建线程的地方,设置了线程的线程组及线程名
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)//默认是正常优先级
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
在上面的代码中,可以看到线程池中默认的线程工厂实现是很简单的,它做的事就是统一给线程池中的线程设置线程group、统一的线程前缀名。以及统一的优先级。
011-ThreadFactory线程工厂
https://www.cnblogs.com/bjlhx/p/7609100.html
Callable
Callable 接口实际上是属于 Executor 框架中的功能类,Callable 接口与 Runnable 接口的功能类似,但提供了比 Runnable 更加强大的功能:
- Callable 可以在任务结束的时候提供一个返回值,Runnable 无法提供这个功能
- Callable 的 call 方法分可以抛出异常,而 Runnable 的 run 方法不能抛出异常。
Callable 接口的实例被线程执行后,可以返回值,这个返回值可以被 Future 拿到,也就是说,Future 可以拿到异步执行任务的返回值
利用 FutureTask 封装 Callable 再由 Thread 启动
下面来看一个简单的例子:
public class CallableAndFuture {
public static void main(String[] args) {
Callable<Integer> callable = new Callable<Integer>() {
public Integer call() throws Exception {
return new Random().nextInt(100);
}
};
FutureTask<Integer> future = new FutureTask<Integer>(callable);
new Thread(future).start();
try {
Thread.sleep(5000);// 可能做一些事情
System.out.println(future.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
FutureTask实现了两个接口,Runnable和Future,所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
利用ExecutorService的submit提交Callable任务到线程池执行
下面来看另一种方式使用Callable和Future,通过ExecutorService线程池的submit方法执行Callable,并返回Future,代码如下:
public class CallableAndFuture {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
Future<Integer> future = threadPool.submit(new Callable<Integer>() {
public Integer call() throws Exception {
return new Random().nextInt(100);
}
});
try {
Thread.sleep(5000);// 可能做一些事情
System.out.println(future.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
Java线程(七):Callable和Future
http://blog.csdn.net/ghsau/article/details/7451464
java并发编程--Runnable Callable及Future
https://www.cnblogs.com/MOBIN/p/6185387.html
Runnable接口和Callable接口的异同点
相同点:
1、两者都是多线程的任务接口;
2、两者都需要调用Thread.start()启动线程;
不同点:
1、Runnable是自从java1.1就有了,而Callable是1.5之后才加上去的。
2、Callable规定的方法是call(),Runnable规定的方法是run()。
3、Callable的任务执行后可返回值,而Runnable的任务是不能返回值(是void)。
4、call方法可以抛出异常,run方法不可以。
5、提交到线程池运行的方式不同,Runnable 使用 ExecutorService 的 execute 或 submit 方法,Callable 使用 submit 方法。
Java并发编程:Callable、Future和FutureTask
http://www.cnblogs.com/xiaoxi/p/8303574.html
Future
java5 提供了 Future 接口用以保存异步计算的结果,可以在我们执行任务时去做其他工作。
Future 用于对于具体的 Runnable 或者 Callable 任务的执行结果进行取消、查询是否完成、获取结果
在 Future 接口里定义了几个公共方法来控制它关联的 Callable 任务:
V get() 返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值。如果计算被取消了则抛出异常
V get(long timeout,TimeUnit unit) 返回Callable里call()方法的返回值,最多阻塞timeout时间,经过指定时间没有返回则抛出异常
cancel(boolean mayInterruptIfRunning) 试图取消执行的任务,参数为true时直接中断正在执行的任务,否则直到当前任务执行完成,成功取消后返回true,否则返回false
boolean isDone() 若Callable任务完成,返回True
boolean isCancelled() 如果在Callable任务正常完成前被取消,返回True
FutureTask
Java5提供了Future接口来代表Callable接口里call()方法的返回值,并且为Future接口提供了一个实现类FutureTask,这个实现类既实现了Future接口,又实现了Runnable接口,所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
FutureTask类通过实现RunnableFuture接口来同时实现了Runnable和Future接口
public class FutureTask<V> implements RunnableFuture<V>{
...
}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
java中创建线程的三种方法以及区别
https://www.cnblogs.com/3s540/p/7172146.html
java并发编程--Runnable Callable及Future
https://www.cnblogs.com/MOBIN/p/6185387.html
CompletableFuture
runAsync() 无返回值任务
runAsync() 方法用于执行没有返回值的异步任务。它接受一个 Runnable 函数式接口作为参数,表示要执行的任务。这个方法会立即返回一个 CompletableFuture<Void> 对象,你可以通过这个对象来处理任务的完成状态、异常等。
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// 异步任务逻辑
});
supplyAsync() 有返回值任务
supplyAsync() 方法用于执行有返回值的异步任务。它接受一个 Supplier 函数式接口作为参数,表示要执行的任务,并返回一个 CompletableFuture<T> 对象,其中 T 是任务的返回类型。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// 异步任务逻辑
return 42; // 返回任务结果
});
CompletableFuture.runAsync()/supplyAsync 方法会立即将任务提交给线程池,但是任务是否立即开始执行取决于线程池的状态和调度策略。如果线程池中有空闲线程,那么任务会立即开始执行;如果线程池中没有空闲线程,那么任务可能会被放入队列中等待执行。
get() 等待执行完并获取结果(受检异常)
public T get() throws InterruptedException, ExecutionException
public T get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException
等待此 CompletableFuture 执行完并返回结果,如果发生异常则 抛出一个受检异常(Checked Exceptions)开发者必须显式捕获或抛出这些异常,否则代码无法编译通过。
join() 等待执行完并获取结果(非受检异常/运行时异常)
public T join()
等待此 CompletableFuture 执行完并返回结果,如果发生异常 抛出的都是 非受检异常(Unchecked Exceptions),即 运行时异常 RuntimeException,无需强制捕获,代码更简洁。
join() 可能抛出:
CancellationException如果计算被取消,属于 RuntimeExceptionCompletionException执行异常,属于 RuntimeException
join() 和 get() 的区别就是
- get() 抛出受检异常,必须手动处理。get() 需要显式处理异常,这会破坏链式调用的流畅性。
- join() 抛出非受检异常,可以不处理,也可通过
exceptionally()处理。join() 可以直接嵌入链式调用中,保持代码连贯性。CompletableFuture 的核心目标是支持非阻塞异步编程。join() 的异常抛出机制与 CompletableFuture 的 exceptionally() 或 handle() 方法天然兼容,便于统一处理异常。
allOf() 全部执行
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
传入一个 CompletableFuture 数组,返回一个新的 CompletableFuture, 返回的这个新 CompletableFuture 只有在全部入参 CompletableFuture 都完成后才算完成。任一入参 CompletableFuture 抛出异常则此 CompletableFuture 也抛出异常。
allOf() 的返回结果类型是 CompletableFuture<Void>,并不会返回全部 CompletableFuture 的结果总和(他也不知道该如何 merge 结果),需要全部执行结束后依次遍历通过 get 或 join 获取结果后手动 merge
allOf().get() 执行全部任务示例-无返回结果
List<CompletableFuture<Boolean>> cfs = userIds.stream().map(id ->
CompletableFuture.supplyAsync(() -> {
userService.processUser(id);
return true;
}
, executor)).collect(Collectors.toList());
// allOf 后 get 等待完成
try {
CompletableFuture.allOf(cfs.toArray(new CompletableFuture[0])).get(10, TimeUnit.MINUTES);
} catch (Exception e) {
log.error("wait thread pool termination fail", e);
}
allOf().join() 执行全部任务示例-有返回结果+合并列表
并发从服务A上查询部分用户列表,从服务B上查询部分用户列表,合并用户列表,并按用户编码去重:
CompletableFuture<List<User>> serviceAFuture = CompletableFuture.supplyAsync(() -> getUserFromServiceA(request));
CompletableFuture<List<User>> serviceBFuture = CompletableFuture.supplyAsync(() -> getUserFromServiceB(request));
List<User> allUsers = CompletableFuture.allOf(serviceAFuture, serviceBFuture)
.thenApply(v -> {
List<User> merged = Lists.newArrayList();
merged.addAll(serviceAFuture.join());
merged.addAll(serviceBFuture.join());
merged = CollUtil.distinct(merged, User::getCode, true);
return merged;
})
.join();
依次get() 执行全部任务-有返回结果
try {
CompletableFuture<Weather> weather1CF = CompletableFuture.supplyAsync(() -> weatherQuery1(query));
CompletableFuture<Weather> weather2CF = CompletableFuture.supplyAsync(() -> weatherQuery2(query));
CompletableFuture.allOf(weather1CF, weather2CF).join();
Weather weather1 = weather1CF.get();
Weather weathre2 = weather2CF.get();
ofNullable(weather1)
.ifPresent(detail -> {
log.info("weather1 result {}", weather1);
});
ofNullable(weathre2)
.ifPresent(domain -> {
log.info("weathre2 result {}", weather2);
});
} catch (Exception e) {
log.error("{} law query error", query, e);
}
forEach(CompletableFuture::join) 执行全部任务-无返回结果
对每个 userId 执行 processUser
userIds.stream().map(id ->
CompletableFuture.supplyAsync(() -> userService.processUser(id), executor)
).forEach(CompletableFuture::join);
forEach(CompletableFuture::join) 执行全部任务-有返回结果+汇总结果
先将 userIds 按 10 分组,每个组内并发处理,组之间顺序处理。返回总的处理成功个数。
processUser 成功返回1,失败返回0,最后 join 统计总的处理成功个数
public Long doUserProcess(List<Long> userIds) {
AtomicLong count = new AtomicLong();
Lists.partition(userIds, 10).forEach(ids -> count.addAndGet(batchProcess(ids)));
return count.get();
}
private Long batchProcess(List<Long> userIds) {
List<CompletableFuture<Integer>> cfs = userIds
.stream()
.map(id -> CompletableFuture.supplyAsync(() -> {
Resp resp = userService.processUser(id);
if (isSuccess(resp)) {
return 1;
} else {
log.error("user process error {}", resp);
return 0;
}
}, userProcessExecutor))
.toList();
Long count = cfs.stream().mapToLong(CompletableFuture::join).sum();
return count;
}
allOf().join() 与 forEach(CompletableFuture::join) 对比
下面三种等待全部 CompletableFuture 任务执行完成的方式,结果是一样的,耗时都是最长任务执行时间5秒稍多(前提是 forkjoin 线程池足够空闲)
- 直接在 CompletableFuture 流上依次 join
- 先收集为 CompletableFuture 列表,再依次 join
- 使用 allOf() 后再 join()
@Test
public void testStreamForEachJoin() {
long ts = System.currentTimeMillis();
List.of(
CompletableFuture.runAsync(() -> ThreadUtil.sleep(2000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(3000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(5000))
).forEach(CompletableFuture::join);
System.out.println("forEach(CompletableFuture::join) 耗时 " + (System.currentTimeMillis() - ts));
}
@Test
public void testForEachJoin() {
long ts = System.currentTimeMillis();
List<CompletableFuture<Void>> futures = List.of(
CompletableFuture.runAsync(() -> ThreadUtil.sleep(2000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(3000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(5000))
);
futures.forEach(CompletableFuture::join);
System.out.println("forEach(CompletableFuture::join) 耗时 " + (System.currentTimeMillis() - ts));
}
@Test
public void testAllOf() {
long ts = System.currentTimeMillis();
List<CompletableFuture<Void>> futures = List.of(
CompletableFuture.runAsync(() -> ThreadUtil.sleep(2000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(3000)),
CompletableFuture.runAsync(() -> ThreadUtil.sleep(5000))
);
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
System.out.println("allOf().join() 耗时 " + (System.currentTimeMillis() - ts));
}
anyOf() 任意返回结果
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)
exceptionally()
public CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)
exceptionally() 方法接受一个函数式接口 Function<Throwable, T> 作为参数,用于处理异常情况并返回一个默认值。如果 CompletableFuture 抛出异常,在调用 exceptionally() 方法后,会返回一个新的 CompletableFuture 对象,其结果是由 exceptionally() 方法返回的默认值。
CompletableFuture
.supplyAsync(() -> {
// 异步任务逻辑,可能会抛出异常
throw new RuntimeException("Some error occurred");
})
.exceptionally(throwable -> {
System.out.println("Exception occurred: " + throwable.getMessage());
return 0; // 返回默认值
});
thenApply()
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)
thenApply 对异步计算的结果进行转换处理,接收 Function<? super T,? extends U> 转换函数,返回新的 CompletableFuture<U> 保存转换结果
转换函数参数 Function<? super T,? extends U> fn 接收类型为 T 的输入,返回类型为 U 的输出,函数签名:U apply(T t)
- T 是当前 CompletableFuture 的结果类型
- U 是转换后的结果类型
thenApply 的执行线程:
- 如果前序任务尚未完成,thenApply 会在前序任务完成的那个线程执行
- 如果前序任务立即完成,会在调用 thenApply 的线程(如主线程 main)中执行
thenApplyAsync 的执行线程:
- 默认在 ForkJoinPool 线程池执行
- 通过 executor 在指定线程池中执行
thenApply 转换中间结果:
@Test
public void testThenApply() {
CompletableFuture<String> originFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("Origin task in: " + Thread.currentThread().getName());
ThreadUtil.sleep(3000);
return "origin data";
});
CompletableFuture<String> upperFuture = originFuture.thenApply(result -> {
System.out.println("thenApply in: " + Thread.currentThread().getName());
return result.toUpperCase();
});
System.out.println(upperFuture.join()); // ORIGIN DATA
}
@Test
public void testThenApplyToOtherType() {
CompletableFuture<String> originFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("Origin task in: " + Thread.currentThread().getName());
return "origin data";
});
// 转换为 Integer CompletableFuture
CompletableFuture<Integer> intFuture = originFuture.thenApply(String::length);
System.out.println(intFuture.join()); // 11
}
如果前序任务立即完成,会在调用线程(主线程)立即执行 thenApply 内容
@Test
public void testThenApplyInMain1() {
CompletableFuture<String> originFuture = CompletableFuture.supplyAsync(() -> "origin data");
originFuture.thenApply(result -> {
System.out.println("thenApply in: " + Thread.currentThread().getName()); // thenApply in: main
return result.toUpperCase();
});
}
@Test
public void testThenApplyInMain2() {
// 创建已完成的任务
CompletableFuture<String> completed = CompletableFuture.completedFuture("data");
completed.thenApply(s -> {
// 此时会在主线程 main 立即执行!
System.out.println("thenApply in: " + Thread.currentThread().getName()); // thenApply in: main
return s;
});
}
thenApplyAsync 在线程池中执行:
@Test
public void testThenApplyAsync() {
ExecutorService customExecutor = Executors.newFixedThreadPool(2);
CompletableFuture<String> originFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("Origin task in: " + Thread.currentThread().getName());
ThreadUtil.sleep(1000);
return "origin data";
});
CompletableFuture<Integer> intFuture = originFuture.thenApplyAsync(result -> {
System.out.println("thenApplyAsync(default) in: " + Thread.currentThread().getName());
return result.length();
});
System.out.println(intFuture.join()); // 11
CompletableFuture<byte[]> bytesFuture = originFuture.thenApplyAsync(result -> {
System.out.println("thenApplyAsync(custom) in: " + Thread.currentThread().getName());
return result.getBytes();
}, customExecutor);
System.out.println(bytesFuture.join()); // [B@47987356
}
whenComplete()
CompletableFuture<T> whenComplete(BiConsumer<? super T, ? super Throwable> action)
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> 10);
CompletableFuture<Void> whenCompleteFuture = future.whenComplete((result, exception) -> {
if (exception == null) {
System.out.println("Result: " + result);
} else {
System.out.println("Exception: " + exception.getMessage());
}
});
handle()
public <U> CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)
handle() 方法与 exceptionally() 方法类似,区别在于它可以处理正常结果和异常情况。它接受一个函数式接口 BiFunction<T, Throwable, U> 作为参数,其中 T 是任务执行结果的类型,U 是处理结果的类型。当 CompletableFuture 完成时,无论是正常结果还是异常情况,都会调用 handle() 方法,并将结果(或异常)传递给该方法进行处理。
CompletableFuture
.supplyAsync(() -> {
// 异步任务逻辑,可能会抛出异常
throw new RuntimeException("Some error occurred");
})
.handle((result, throwable) -> {
if (throwable != null) {
System.out.println("Exception occurred: " + throwable.getMessage());
return 0; // 返回默认值
} else {
System.out.println("Result: " + result);
return result;
}
});
whenComplete() 和 handle() 区别
whenComplete 接收的是 BiConsumer, handler 接收的是 BiFunction,BiConsumer 消费无返回值,而 BiFunction 是有返回值的
whenComplete 不会对原始 Future 的结果进行转换或处理,返回原始 Future 的值。handler 返回处理后的值。
whenComplete 会将内部异常往外抛出。handle() 不会将内部异常抛出
ThreadPoolExecutor 线程池
Java线程池的核心类
java.util.concurrent.ThreadPoolExecutor
public class ThreadPoolExecutor extends AbstractExecutorService
类继承关系
Executor 是一个顶层接口,在它里面只声明了一个方法 execute(Runnable), 返回值为 void, 参数为 Runnable 类型,从字面意思可以理解,就是用来执行传进去的任务的;
ExecutorService 继承了 Executor 接口,并新增了一些方法:submit, invokeAll, invokeAny 以及 shutDown 等
AbstractExecutorService 是一个抽象类,它实现了 ExecutorService 接口,基本实现了 ExecutorService 中声明的所有方法;
ThreadPoolExecutor 继承了 AbstractExecutorService
构造方法参数
package java.util.concurrent;
public class ThreadPoolExecutor extends AbstractExecutorService {
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
}
int corePoolSize:核心池的大小
核心线程会一直存活,及时没有任务需要执行
当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
int maximumPoolSize:线程池最大线程数
当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
long keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。
TimeUnit unit:参数keepAliveTime的时间单位。有7种取值,在TimeUnit类中有7种静态属性:TimeUnit.DAYS; TimeUnit.HOURS; TimeUnit.MINUTES; TimeUnit.SECONDS; TimeUnit.MILLISECONDS; TimeUnit.MICROSECONDS; TimeUnit.NANOSECONDS;
当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
如果allowCoreThreadTimeout=true,则会直到线程数量=0
表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
BlockingQueue<Runnable> workQueue:一个阻塞队列,用来存储等待执行的任务
ThreadFactory threadFactory:线程工厂,主要用来创建线程;
RejectedExecutionHandler handler:表示当拒绝处理任务时的策略
两种情况会拒绝处理任务:
当线程数已经达到maxPoolSize,且队列已满,会拒绝新任务
当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
其他非构造参数
allowCoreThreadTimeout:允许核心线程超时
抛出
- IllegalArgumentException - 如果 corePoolSize 或 keepAliveTime 小于 0,或者 maximumPoolSize 小于等于 0,或者 corePoolSize 大于 maximumPoolSize。
- NullPointerException - 如果 workQueue、threadFactory 或 handler 为 null。
JAVA ThreadPoolExecutor线程池参数设置技巧
https://www.imooc.com/article/5887
有哪几种阻塞队列?
workQueue 参数可选的队列有:
ArrayBlockingQueue是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。LinkedBlockingQueue一个基于链表结构的阻塞队列,此队列按 FIFO(先进先出) 排序元素,吞吐量通常要高于 ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。SynchronousQueue一个不存储元素的阻塞队列,即队列长度为0。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。如果想队列长度为0,或者说跳过队列缓存任务这个步骤,可以使用SynchronousQueuePriorityBlockingQueue一个具有优先级得无限阻塞队列。
何时创建新线程?(队列与池交互)
ThreadPoolExecutor 将根据 corePoolSize 和 maximumPoolSize 设置的边界自动调整池大小。当新任务在方法 execute(Runnable) 中提交时,如果运行的线程少于 corePoolSize,则创建新线程来处理请求,即使其他辅助线程是空闲的。如果运行的线程多于 corePoolSize 而少于 maximumPoolSize,则仅当队列满时才创建新线程。如果设置的 corePoolSize 和 maximumPoolSize 相同,则创建了固定大小的线程池。如果将 maximumPoolSize 设置为基本的无界值(如 Integer.MAX_VALUE),则允许池适应任意数量的并发任务。在大多数情况下,核心和最大池大小仅基于构造来设置,不过也可以使用 setCorePoolSize(int) 和 setMaximumPoolSize(int) 进行动态更改。
当提交一个新任务到线程池时,线程池的处理流程如下:
- 首先线程池判断基本线程池是否已满?没满,创建一个工作线程来执行任务。满了,则进入下个流程。
- 其次线程池判断工作队列是否已满?没满,则将新提交的任务存储在工作队列里。满了,则进入下个流程。
- 最后线程池判断整个线程池是否已满?没满,则创建一个新的工作线程来执行任务,满了,则交给饱和策略来处理这个任务。
线程池按以下行为执行任务
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。若添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败(一般来说是任务缓存队列已满),则会尝试创建新的线程去执行这个任务,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
- 当线程数大于等于核心线程数,且任务队列已满。
(1)若线程数小于最大线程数,创建线程
(2)若线程数等于最大线程数,抛出异常,拒绝任务
排队有三种通用策略:
- 直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
- 无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
- 有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
拒绝任务处理策略(饱和策略)
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。
当 Executor 已经关闭,并且 Executor 将有限边界用于最大线程和工作队列容量,且已经饱和时,在方法 execute(java.lang.Runnable) 中提交的新任务将被拒绝。
在以上两种情况下,execute 方法都将调用其 RejectedExecutionHandler 的 RejectedExecutionHandler.rejectedExecution(java.lang.Runnable, java.util.concurrent.ThreadPoolExecutor) 方法。
JDK 的 拒绝策略接口源码如下:
package java.util.concurrent;
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
JDK提供了四种预定义的处理程序策略, 是 ThreadPoolExecutor 类的静态内部类
ThreadPoolExecutor.AbortPolicy,默认策略,处理程序遭到拒绝将抛出运行时RejectedExecutionExceptionThreadPoolExecutor.DiscardPolicy不能执行的任务将被删除。但是不抛出异常。ThreadPoolExecutor.CallerRunsPolicy用调用者所在线程来运行任务。ThreadPoolExecutor.DiscardOldestPolicy弃老(弃旧),如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)。 即丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。
源码如下:
public class ThreadPoolExecutor extends AbstractExecutorService {
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
// 调用者直接执行任务的run()方法
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
// 抛出异常
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
// 忽略
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
// 弃老(弃旧)
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
}
定义和使用其他种类的 RejectedExecutionHandler 类也是可能的,但这样做需要非常小心,尤其是当策略仅用于特定容量或排队策略时。
仅打印日志
(r, executor) -> log.error("overload @ xxxx executor");
Dubbo log并dump堆栈后抛异常
1、Dubbo 中的线程拒绝策略
public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy {
protected static final Logger logger = LoggerFactory.getLogger(AbortPolicyWithReport.class);
private final String threadName;
private final URL url;
private static volatile long lastPrintTime = 0;
private static Semaphore guard = new Semaphore(1);
public AbortPolicyWithReport(String threadName, URL url) {
this.threadName = threadName;
this.url = url;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
String msg = String.format("Thread pool is EXHAUSTED!" +
" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d)," +
" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",
threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(),
e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),
url.getProtocol(), url.getIp(), url.getPort());
logger.warn(msg);
dumpJStack();
throw new RejectedExecutionException(msg);
}
private void dumpJStack() {
//省略实现
}
}
继承了默认的 ThreadPoolExecutor.AbortPolicy,重写了处理方法,增加了日志输出,当前堆栈信息打印之后再抛出异常.
Netty 新启动一个线程执行
2、Netty 中的线程池拒绝策略
private static final class NewThreadRunsPolicy implements RejectedExecutionHandler {
NewThreadRunsPolicy() {
super();
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
final Thread t = new Thread(r, "Temporary task executor");
t.start();
} catch (Throwable e) {
throw new RejectedExecutionException(
"Failed to start a new thread", e);
}
}
}
Netty 中的实现很像 JDK 中的 CallerRunsPolicy,舍不得丢弃任务。
不同的是,CallerRunsPolicy 是直接在调用者线程执行的任务。而 Netty是新建了一个线程来处理的。
所以,Netty的实现相较于调用者执行策略的使用面就可以扩展到支持高效率高性能的场景了。
但是也要注意一点,Netty的实现里,在创建线程时未做任何的判断约束,也就是说只要系统还有资源就会创建新的线程来处理,直到new不出新的线程了,才会抛创建线程失败的异常
ActiveMQ 1分钟内尝试入队
3、ActiveMQ 中的线程池拒绝策略
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(final Runnable r, final ThreadPoolExecutor executor) {
try {
executor.getQueue().offer(r, 60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RejectedExecutionException("Interrupted waiting for BrokerService.worker");
}
throw new RejectedExecutionException("Timed Out while attempting to enqueue Task.");
}
});
activeMq中的策略属于最大努力执行任务型,当触发拒绝策略时,在尝试一分钟的时间重新将任务塞进任务队列,当一分钟超时还没成功时,就抛出异常
PinPoint 拒绝策略链
4、PinPoint 中的线程池拒绝策略
public class RejectedExecutionHandlerChain implements RejectedExecutionHandler {
private final RejectedExecutionHandler[] handlerChain;
public static RejectedExecutionHandler build(List<RejectedExecutionHandler> chain) {
Objects.requireNonNull(chain, "handlerChain must not be null");
RejectedExecutionHandler[] handlerChain = chain.toArray(new RejectedExecutionHandler[0]);
return new RejectedExecutionHandlerChain(handlerChain);
}
private RejectedExecutionHandlerChain(RejectedExecutionHandler[] handlerChain) {
this.handlerChain = Objects.requireNonNull(handlerChain, "handlerChain must not be null");
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
for (RejectedExecutionHandler rejectedExecutionHandler : handlerChain) {
rejectedExecutionHandler.rejectedExecution(r, executor);
}
}
}
pinpoint的拒绝策略实现很有特点,和其他的实现都不同。他定义了一个拒绝策略链,包装了一个拒绝策略列表,当触发拒绝策略时,会将策略链中的rejectedExecution依次执行一遍。
ThreadPoolExecutor 八种拒绝策略,对的,不是4种!
https://mp.weixin.qq.com/s/HRmqBq8NtoW4j6uguZJeBw
线程池状态(如何关闭线程池?)
在 ThreadPoolExecutor 中定义了一个 volatile 变量,另外定义了几个 static final 变量表示线程池的各个状态:
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3;
runState表示当前线程池的状态,它是一个 volatile 变量用来保证线程之间的可见性;
下面的几个 static final 变量表示 runState 可能的几个取值。
当创建线程池后,初始时,线程池处于 RUNNING 状态;
如果调用了 shutdown() 方法,则线程池处于 SHUTDOWN 状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了 shutdownNow() 方法,则线程池处于 STOP 状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于 SHUTDOWN 或 STOP 状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为 TERMINATED 状态。
shutdown()
void shutdown()
如果调用了 shutdown() 方法,则线程池处于 SHUTDOWN 状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
shutdownNow()
List<Runnable> shutdownNow()
如果调用了 shutdownNow() 方法,则线程池处于 STOP 状态,此时线程池不能接受新的任务,如果有等待任务,移出队列;有正在执行的,尝试停止之;
awaitTermination()
boolean awaitTermination(long timeout, TimeUnit unit)
从接口 ExecutorService 继承的方法,用于阻塞当前线程,等待剩余任务执行完,然后继续往下执行。
简单来说,awaitTermination 会一直等待,直到线程池状态为 TERMINATED 或者,等待的时间到达了指定的超时时间。
timeout,最长等待时间;unit,timeout 参数的时间单位。当超过 timeout 时间后,会监测 ExecutorService 是否已经关闭,若关闭则返回true,否则返回false。
shutdown和awaitTermination组合使用
通常shutdown之后调用awaitTermination,作用是:shutdown告诉线程池,执行完所有任务后关闭线程池。后者会阻塞当前线程,等待剩余任务执行完,然后继续往下执行。如果不使用awaitTermination,那么shutdown之后,很可能导致剩余任务得不到执行(整个程序退出),或是执行出现异常(某些资源被释放之类)。
线程池未关闭导致主线程无法退出的问题
如下代码
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
executorService.execute(() -> System.out.println(Thread.currentThread()));
}
执行完后主线程不会退出,因为核心线程池中有一个工作线程(用户线程、非守护线程)不会自己关闭,有用户线程存在,jvm自然不会退出,所以主线程也结束不了。
应该在使用完线程池后主动调用 executorService.shutdown();
使用线程池时候当程序结束时候记得调用shutdown关闭线程池
https://www.jianshu.com/p/6e3f593c2616
局部线程池踩坑记录
下面这段代码,在类作用域中初始化了线程池 executor, 但是在 myTask 方法中执行了 shutdown() 和 awaitTermination() 方法,会导致第一次执行 myTask 方法后线程池就被关闭了,之后线程池无法再执行任务。
public class MyClass {
private static final int CPU_CORE = Runtime.getRuntime().availableProcessors();
private ThreadPoolExecutor executor = new ThreadPoolExecutor(
CPU_CORE,
CPU_CORE * 4,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(5),
new ThreadFactoryBuilder().setNameFormat("export-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
public void myTask(List<String> ids) {
ids.forEach(id -> executor.submit(() -> xxtask()));
try {
executor.shutdown();
executor.awaitTermination(10, TimeUnit.MINUTES);
} catch (InterruptedException e) {
log.error("wait thread pool termination fail", e);
}
}
}
一般不建议使用局部线程池,如果使用局部线程池可能有内存泄漏的风险,见下面这篇文章的分析
线程池踩坑 - 作为实例成员或方法局部变量的误区
https://blog.csdn.net/firefile/article/details/80747569
不推荐将线程池作为局部变量使用,而要作为全局变量。一般都会把线程池作为类的静态成员或者单例成员,生命周期和进程一致
如果方法内定义局部线程池的话,用完后一定要执行 shutdown() 和 awaitTermination() 来手动关闭,否则会造成内存泄漏
向线程池中提交任务
execute() Runnable 任务
void execute(Runnable task)
execute() 方法在线程池的顶层接口 Executor 中声明,只能用于提交 Runnable 任务。
我们可以使用 execute 提交 Runnable 任务,但是 execute 方法没有返回值,所以无法判断任务知否被线程池执行成功。
在将来某个时间执行给定任务。可能在新线程中执行,也可能在现有池线程中执行该任务。如果无法将任务提交执行,或者因为此执行程序已关闭,或者因为已达到其容量,则该任务由当前 RejectedExecutionHandler 处理。
execute() 方法实际上是 Executor 中声明的方法,在 ThreadPoolExecutor 进行了具体的实现,这个方法是 ThreadPoolExecutor 的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
submit() Runnable/Callable 任务
submit() 方法在线程池的次顶层接口 ExecutorService 中声明,可用于提交 Runnable 和 Callable 任务。
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
我们也可以使用 submit 提交 Callable 任务,它会返回一个 future, 可以通过这个 future 来判断任务是否执行成功,通过 future 的 get 方法来获取返回值,get 方法会阻塞住直到任务完成,而使用 get(long timeout, TimeUnit unit) 方法则会阻塞一段时间后立即返回,这时有可能任务没有执行完。
返回一个表示任务的未决结果的 Future。该 Future 的 get 方法在成功完成时将会返回该任务的结果。
如果想立即阻塞任务的等待,则可以使用 result = exec.submit(aCallable).get(); 形式的构造。
invokeAll() 提交Callable集合全部执行
invokeAll 在 ExecutorService 中声明,用于批量提交 Callable 任务并全部执行。
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
tasks 是任务集合,timeout 是超时时间,unit 是时间单位。
invokeAll() 的两种重载形式都会阻塞,必须等待所有的任务执行完成后统一返回。
第二种形式增加了超时时间控制,这里的超时时间是针对的所有tasks,而不是单个task的超时时间。如果超时,会取消没有执行完的所有任务,并抛出超时异常。
invokeAll() 方法处理一个任务的集合 Collection,并返回一个 Future 的列表 List,任务集合列表和返回的 Future 列表存在顺序对应的关系,通过顺序的遍历 List<Future> 列表可以获取对应任务的执行结果。
List<Future>接收invokeAll()结果示例
使用 invokeAll() 可以很方便的将单个方法调用改为并发的批量调用,如果原始方法本身无返回值,可以加一个 return true
例如:
@Test
public void testFutureResult() {
int coreNum = Runtime.getRuntime().availableProcessors();
System.out.println("机器核数:" + coreNum);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
coreNum, coreNum * 2,
60, TimeUnit.SECONDS,
new SynchronousQueue<>(),
new ThreadFactoryBuilder().setNameFormat("masikkk.com-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
// Callable 任务列表
List<Callable<String>> tasks =
Stream.iterate(1, n -> n + 1).limit(10).map(i -> (Callable<String>) () -> print(i)).collect(
Collectors.toList());
try {
List<Future<String>> futures = threadPoolExecutor.invokeAll(tasks);
for (Future<String> future : futures) {
// 打印 Futura 中的值
System.out.println(future.get());
}
} catch (Exception e) {
e.printStackTrace();
}
}
public String print(int i) {
System.out.println(Thread.currentThread().getName());
return "输入" + i;
}
Target type of a lambda conversion must be an interface
通过 stream 构造 List<Callable> 任务集合时经常会遇到这个提示,比如如下代码
List<Callable<FuncReturnType>> callList = userIds.stream()
.map(uid -> () -> func(uid))) // 此处提示 Target type of a lambda conversion must be an interface
.collect(Collectors.toList());
解决方法是 uid 转 lambda 表达式时加上强制类型转换,强转为 Callable<FuncReturnType> 类型
List<Callable<FuncReturnType>> callList = userIds.stream()
.map(uid -> (Callable<FuncReturnType>) () -> func(uid))) // 强转
.collect(Collectors.toList());
如果func()无返回类型怎么办?
方法1、func() 加个 return true, 返回类型改为 boolean
方法2、不改动 func() 方法,在外层再包一层:
Collection<Callable<Boolean>> taskList = IntStream.range(0, 100).mapToObj(i -> (Callable<Boolean>) () -> {
testMethod();
return Boolean.TRUE;
}
).collect(Collectors.toList());
Java “target type of lambda conversion must be an interface”
https://stackoverflow.com/questions/34426794/java-target-type-of-lambda-conversion-must-be-an-interface
invokeAny() 提交Callable集合任意一个有结果就返回
invokeAll 在 ExecutorService 中声明,用于批量提交 Callable 任务但只要其中任意一个任务有结果(返回或抛异常)就返回,并取消所有其他任务。
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
invokeAll()和invokeAny()的典型用法
1、有三个提供天气服务的API,同时去调用者3个,有任意一个返回则结束,用 invokeAny()
2、订单中台的订单查询接口要聚合普通单、团购单、线下单,并发去调这3种订单查询,等都返回后,拼到一起,用 invokeAll()
ThreadPoolExecutor使用示例
@Test
public void testExecute() throws Exception {
int coreNum = Runtime.getRuntime().availableProcessors();
System.out.println("机器核数:" + coreNum);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
coreNum, coreNum * 2,
60, TimeUnit.SECONDS,
new SynchronousQueue<>(),
new ThreadFactoryBuilder().setNameFormat("masikkk.com-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 15; i++) {
final int ii = i;
threadPoolExecutor.execute(() -> {
System.out.println(Thread.currentThread().getName());
int sleepMills = (int) (Math.random() * 3000);
try {
Thread.sleep(sleepMills);
} catch (InterruptedException e) {
}
});
}
// 等待线程池执行结束
threadPoolExecutor.shutdown();
threadPoolExecutor.awaitTermination(100, TimeUnit.SECONDS);
}
运行结果如下,可以看到线程池中创建了 8 个线程(也就是最大工作线程)后,再提交任务时由于拒绝策略是调用者线程执行,就在主线程中执行了。
机器核数:4
masikkk.com-0
masikkk.com-1
masikkk.com-2
masikkk.com-3
masikkk.com-4
masikkk.com-5
masikkk.com-6
main
masikkk.com-7
masikkk.com-3
masikkk.com-1
masikkk.com-5
masikkk.com-7
masikkk.com-0
masikkk.com-2
观测线程池运行状态
ThreadPoolExecutor 中提供了几个方法便于我们了解当前线程池的运行状态
getActiveCount() 获取当前活跃线程数
getCompletedTaskCount() 获取已完成任务数,是个近似值。包括正常完成的任务和异常结束的任务。只有当任务完成后,这个数量才会增加。
getTaskCount() 获取总任务数,是个近似值。线程池已经接收的任务数量,包括已完成的,正在执行的,还在队列等待执行的任务。
getQueue().size() 排队等待任务数
@Test
public void test2FeatureAddConcurrently() throws Exception {
int total = 10000;
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor)Executors.newFixedThreadPool(75);
long time = System.currentTimeMillis();
IntStream.range(0, total).forEach(i -> threadPoolExecutor.submit(() -> {
commonService.commonAdd(mockData());
}));
// 观察线程池
while (true) {
System.out.println();
int queueSize = threadPoolExecutor.getQueue().size();
System.out.println("当前排队线程数:" + queueSize);
int activeCount = threadPoolExecutor.getActiveCount();
System.out.println("当前活动线程数:" + activeCount);
long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();
System.out.println("执行完成任务数:" + completedTaskCount);
long taskCount = threadPoolExecutor.getTaskCount();
System.out.println("总任务数:" + taskCount);
Thread.sleep(3000);
if (completedTaskCount >= total) {
break;
}
}
System.out.println(System.currentTimeMillis() - time);
}
线程池如何处理抛异常的线程?
1、当执行方式是 execute 时,可以看到堆栈异常的输出。
当执行方式是 submit 时,堆栈异常没有输出。但是调用 Future.get() 方法时,可以捕获到异常。
2、不会影响线程池里面其他线程的正常执行。
3、线程池会把这个线程移除掉,并创建一个新的线程放到线程池中。
分析:
线程池中的线程会被封装为 ThreadPoolExecutor 的内部类 Worker ,最终执行时都是通过 runWorker() 来执行的。
对于 Runnable 任务,run 的时候抛出的异常会在 runWorker 中被捕获,最终在 java.lang.ThreadGroup#uncaughtException 进行了异常处理,也就是打印出异常堆栈。
对于 Callable 任务,首先被封装为 FutureTask ,再通过 execute() 当做 Runnable 去执行,看一下 FutureTask 的 run 方法就会发现其中调用 call() 方法时进行了异常捕获,并最终通过 call 方法的返回值把异常返回
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
有的线程它死了,于是它变成一道面试题
https://mp.weixin.qq.com/s/wrTVGLDvhE-eb5lhygWEqQ
合理配置线程池的大小
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。
- CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。
- IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2×Ncpu。
- 混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
根据任务阻塞系数和CPU个数设置线程池大小
Blocking Coefficient(阻塞系数) = 阻塞时间/(阻塞时间+使用CPU的时间)
计算密集型任务的阻塞系数为0,而IO密集型任务的阻塞系数则接近于1。
阻塞系数越接近1,表示任务花在等待 io 上的时间占比越大。阻塞系数越接近0,表示任务花在等待io上的视觉占比越小。
传入阻塞系数,线程池的大小计算公式为:CPU可用核心数 / (1 - 阻塞因子)
hutool 的 cn.hutool.core.thread.ThreadUtil.newExecutorByBlockingCoefficient() 实现了根据CPU个数和阻塞系数创建对应大小的线程池
public static ThreadPoolExecutor newExecutorByBlockingCoefficient(float blockingCoefficient) {
if (blockingCoefficient >= 1 || blockingCoefficient < 0) {
throw new IllegalArgumentException("[blockingCoefficient] must between 0 and 1, or equals 0.");
}
// 最佳的线程数 = CPU可用核心数 / (1 - 阻塞系数)
int poolSize = (int) (RuntimeUtil.getProcessorCount() / (1 - blockingCoefficient));
return ExecutorBuilder.create().setCorePoolSize(poolSize).setMaxPoolSize(poolSize).setKeepAliveTime(0L).build();
}
根据CPU个数配置线程池大小示例
我们可以通过 Runtime.getRuntime().availableProcessors() 方法获得当前设备的CPU个数。
例如,先读配置文件中的线程池大小参数,如果读不到则设置为 [core, core*2] 大小
ExecutorService executor = new ThreadPoolExecutor(
Optional.ofNullable(properties.getCoreSize()).orElse(Runtime.getRuntime().availableProcessors()),
Optional.ofNullable(properties.getMaxSize()).orElse(Runtime.getRuntime().availableProcessors() * 2),
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(Optional.ofNullable(properties.getQueueSize()).orElse(100)),
new ThreadFactoryBuilder().setNameFormat("XxxTask-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
深入理解Java之线程池
http://www.importnew.com/19011.html
聊聊并发(三)Java线程池的分析和使用
http://ifeve.com/java-threadpool/
多线程和线程池(为什么要用线程池?)
一种是 多线程,一种是线程池。对于多线程模式,也就说来了任务,就会新建一个线程来执行任务
这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。
因此,为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题:
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
那么有没有一种办法使得线程可以复用,就是执行完一个任务,并不被销毁,而是可以继续执行其他的任务?
在Java中可以通过线程池来达到这样的效果。
- Java并发编程:线程池的使用
http://www.cnblogs.com/dolphin0520/p/3932921.html
beforeExecute()/afterExecute()/扩展线程池
ThreadPoolExecutor 是可扩展的,通过查看源码可以发现,它提供了几个可以在子类化中改写的方法:beforeExecute, afterExecute, terminated
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
可以注意到,这三个方法都是protected的空方法,目的就是为了让子类扩展的。
在执行任务的线程中将调用 beforeExecute 和 afterExecute 等方法,在这些方法中还可以添加日志、计时、监视或者统计信息收集的功能。
无论任务是从run中正常返回,还是抛出一个异常而返回,afterExecute都会被调用。如果任务在完成后带有一个Error,那么就不会调用afterExecute。
如果 beforeExecute 抛出一个 RuntimeException,那么任务将不被执行,并且 afterExecute 也不会被调用。
在线程池完成关闭时调用terminated,也就是在所有任务都已经完成并且所有工作者线程也已经关闭后,terminated可以用来释放Executor在其生命周期里分配的各种资源,此外还可以执行发送通知、记录日志或者手机finalize统计等操作。
Executors 自带线程池
在 java doc 中,并不提倡我们直接使用 ThreadPoolExecutor,而是使用 Executors 类中提供的几个静态方法来创建线程池
但 阿里 Java 编程规范中严禁使用 Executors 自带线程池,如下:
- 【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和SingleThreadPool: 允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。 2)CachedThreadPool和ScheduledThreadPool: 允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
Executors 提供如下四个配置好的线程池:
Executors.newCachedThreadPool() 创建一个缓冲池,缓冲池容量大小为Integer.MAX_VALUE
Executors.newSingleThreadExecutor() 创建容量为1的缓冲池
Executors.newFixedThreadPool(int) 创建固定容量大小的缓冲池
Executors.newScheduledThreadPool(int) 调度型线程池-这个池子里的线程可以按schedule依次delay执行,或周期执行
newFixedThreadPool(int nThreads)
newFixedThreadPool 将创建一个固定长度的线程池,每当提交一个任务时就创建一个线程,直到达到线程池的最大数量,这是线程池的规模将不再变化(如果某个线程由于发生了未预期的 Exception 而结束,那么线程池会补充一个新的线程)。
newFixedThreadPool 创建的线程池 corePoolSize 和 maximumPoolSize 值是相等的,它使用的 LinkedBlockingQueue 阻塞队列默认大小为 Integer.MAX_VALUE
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newCachedThreadPool
newCachedThreadPool 将创建一个可缓存线程的线程池。根据任务按需创建线程,并且当任务结束后会将该线程缓存 60 秒,如果期间有新的任务到来,则会重用这些线程,如果没有新任务,则这些线程会被终止并移除缓存。此线程池适用于处理量大且短时的异步任务。
newCachedThreadPool 将 corePoolSize 设置为0,将 maximumPoolSize 设置为 Integer.MAX_VALUE,使用的 SynchronousQueue, 也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newSingleThreadExecutor
newSingleThreadExecutor 是一个单线程的 Executor,它创建单个工作者线程来执行任务,如果这个线程异常结束,会创建另一个线程来替代。它还能确保依照任务在队列中的顺序来串行执行。
newSingleThreadExecutor 将 corePoolSize 和 maximumPoolSize 都设置为1,也使用的 LinkedBlockingQueue;
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newScheduledThreadPool
newScheduledThreadPool 创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于 Timer。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
从它们的具体实现来看,它们实际上也是调用了 ThreadPoolExecutor,只不过参数都已配置好了。
其中调度线程池的构造方法如下:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
本质上也是调用其父类 ThreadPoolExecutor 的构造器,只是它使用的工作队列是 java.util.concurrent.ScheduledThreadPoolExecutor.DelayedWorkQueue,通过名字我们都可以猜到这个是一个延时工作队列
实际中,如果Executors提供的三个静态方法能满足要求,就尽量使用它提供的三个方法,因为自己去手动配置ThreadPoolExecutor的参数有点麻烦,要根据实际任务的类型和数量来进行配置。
深入理解Java之线程池
http://www.importnew.com/19011.html
Java ExecutorService四种线程池的例子与说明
http://blog.csdn.net/nk_tf/article/details/51959276
java常用的几种线程池比较
https://www.cnblogs.com/aaron911/p/6213808.html
Java并发编程(19):并发新特性—Executor框架与线程池(含代码)
http://www.importnew.com/20809.html
KeyAffinityExecutor
https://github.com/PhantomThief/more-lambdas-java
按指定的Key亲和顺序消费的执行器。
它可以确保投递进来的任务按Key相同的任务依照提交顺序依次执行。在既要通过并行处理来提高吞吐量、又要保证一定范围内的任务按照严格的先后顺序来运行的场景下非常适用。
实现:
内部维护一个 key 到 Executor 的映射,相同 key 的任务用同一个线程池(不一定完全同一个,可复用)
使用:
class MyClass {
private final KeyAffinityExecutor<Integer> keyExecutor = newSerializingExecutor(10, "user-fans-count-%d");
void foo(User user) {
Future<Integer> fansCount = keyExecutor.submit(user.getUserId(), () -> {
return fansService.getByUserId(user.getUserId());
});
}
}
https://segmentfault.com/a/1190000041033155
ThreadPoolTaskExecutor Spring 提供的线程池
Spring 中的 org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor 是基于 JDK 并发包中的 java.util.concurrent.ThreadPoolExecutor 来实现的。
建议在 Spring 项目中使用 ThreadPoolTaskExecutor, 对 ThreadPoolExecutor 做了很多封装,使用起来更加简单优雅。
public class ThreadPoolTaskExecutor extends ExecutorConfigurationSupport
implements AsyncListenableTaskExecutor, SchedulingTaskExecutor {}
他继承了 ExecutorConfigurationSupport 类, 此类实现了 BeanNameAware, InitializingBean, DisposableBean 这三个接口主要是做一些初始化和销毁资源处理操作, 给 ThreadPoolTaskExecutor 进行自动初始化和销毁赋能。
public abstract class ExecutorConfigurationSupport extends CustomizableThreadFactory
implements BeanNameAware, InitializingBean, DisposableBean{}
初始化过程分析
由于 ThreadPoolTaskExecutor 的父类 ExecutorConfigurationSupport 实现了 InitializingBean 接口,所以只要重写其中的 afterPropertiesSet() 方法即可定制初始化动作。
public abstract class ExecutorConfigurationSupport extends CustomizableThreadFactory
implements BeanNameAware, InitializingBean, DisposableBean {
@Override
public void afterPropertiesSet() {
initialize();
}
public void initialize() {
if (logger.isInfoEnabled()) {
logger.info("Initializing ExecutorService" + (this.beanName != null ? " '" + this.beanName + "'" : ""));
}
if (!this.threadNamePrefixSet && this.beanName != null) {
setThreadNamePrefix(this.beanName + "-");
}
this.executor = initializeExecutor(this.threadFactory, this.rejectedExecutionHandler);
}
protected abstract ExecutorService initializeExecutor(
ThreadFactory threadFactory, RejectedExecutionHandler rejectedExecutionHandler);
}
最终通过抽象方法 initializeExecutor 来初始化 executor,在 ThreadPoolTaskExecutor 中的实现:
@Override
protected ExecutorService initializeExecutor(
ThreadFactory threadFactory, RejectedExecutionHandler rejectedExecutionHandler) {
BlockingQueue<Runnable> queue = createQueue(this.queueCapacity);
ThreadPoolExecutor executor;
if (this.taskDecorator != null) {
executor = new ThreadPoolExecutor(
this.corePoolSize, this.maxPoolSize, this.keepAliveSeconds, TimeUnit.SECONDS,
queue, threadFactory, rejectedExecutionHandler) {
@Override
public void execute(Runnable command) {
super.execute(taskDecorator.decorate(command));
}
};
}
else {
executor = new ThreadPoolExecutor(
this.corePoolSize, this.maxPoolSize, this.keepAliveSeconds, TimeUnit.SECONDS,
queue, threadFactory, rejectedExecutionHandler);
}
if (this.allowCoreThreadTimeOut) {
executor.allowCoreThreadTimeOut(true);
}
this.threadPoolExecutor = executor;
return executor;
}
可以看到就是用参数 new 一个 ThreadPoolExecutor
销毁过程分析
由于 ThreadPoolTaskExecutor 的父类 ExecutorConfigurationSupport 实现了 DisposableBean 接口,所以只要重写其中的 destroy() 方法即可定制销毁动作。
public abstract class ExecutorConfigurationSupport extends CustomizableThreadFactory
implements BeanNameAware, InitializingBean, DisposableBean {
@Override
public void destroy() {
shutdown();
}
public void shutdown() {
if (logger.isInfoEnabled()) {
logger.info("Shutting down ExecutorService" + (this.beanName != null ? " '" + this.beanName + "'" : ""));
}
if (this.executor != null) {
if (this.waitForTasksToCompleteOnShutdown) {
this.executor.shutdown();
}
else {
this.executor.shutdownNow();
}
awaitTerminationIfNecessary(this.executor);
}
}
}
主要是用了 ExecutorService 的 shutdown 做一些资源的处理
使用
使用 ThreadPoolTaskExecutor 可以像配置 Bean 一样配置线程池:
@Bean("taskExecutor")
public Executor schedulingTaskExecutor() {
return initExecutor(4, 4, 1, new ThreadPoolExecutor.AbortPolicy(), "taskExecutor-");
}
private Executor initExecutor(int corePoolSize, int maxPoolSize, int queueCapacity, RejectedExecutionHandler rejectedExecutionHandler, String threadNamePrefix) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(60);
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setAwaitTerminationSeconds(60);
executor.setThreadNamePrefix(threadNamePrefix);
executor.setRejectedExecutionHandler(rejectedExecutionHandler);
executor.setTaskDecorator(new MyDecorator());
executor.initialize();
return executor;
}
ThreadPoolTaskExecutor 线程名称
Spring 的 ThreadPoolTaskExecutor 底层使用 JDK 的 ThreadPoolExecutor,其默认线程工厂 (DefaultThreadFactory) 维护一个 全局计数器。
每次创建新线程时,序号自动 +1(从1开始计数),不会重置。即使旧线程被销毁,新线程仍会分配新序号。
所以,即使设置 maxPoolSize = 2,创建的线程名称也可能有 namePrefix-100 这种很大的序号。
public class CustomizableThreadCreator implements Serializable {
private String threadNamePrefix;
private int threadPriority = Thread.NORM_PRIORITY;
private boolean daemon = false;
@Nullable
private ThreadGroup threadGroup;
private final AtomicInteger threadCount = new AtomicInteger();
protected String nextThreadName() {
return getThreadNamePrefix() + this.threadCount.incrementAndGet();
}
}
TaskDecorator 线程装饰器
ThreadPoolTaskExecutor 的 setTaskDecorator 方法用于为线程池任务添加装饰器,主要解决父子线程间上下文传递和任务执行前后的统一处理问题。
使用 MDC 等 ThreadLocal 变量时一件很难受的事是到线程池后就丢了 ThreadLocal 变量,使用 ThreadPoolTaskExecutor 的 TaskDecorator 线程装饰器可解决此问题
注意:注意线程池中的线程是一直存在一直被复用的,所以线程执行完成后需要在 TaskDecorator 的 finally 方法中移除传递的上下文对象,否则就存在内存泄漏的问题。
@FunctionalInterface
public interface TaskDecorator {
Runnable decorate(Runnable runnable);
}
取出主线程的 MDC 放入线程池
class MdcCopyDecorator implements TaskDecorator {
@Nonnull
@Override
public Runnable decorate(@Nonnull Runnable runnable) {
// 主线程
Map<String,String> previous = MDC.getCopyOfContextMap();
return () -> {
// 子线程
try {
// 将主线程的 MDC 放入子线程
MDC.setContextMap(previous);
runnable.run();
} finally {
MDC.clear();
}
};
}
}
executor.setTaskDecorator(new MdcCopyDecorator());
记录任务执行时间
public class TimingTaskDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
return () -> {
long start = System.currentTimeMillis();
try {
runnable.run();
} finally {
long duration = System.currentTimeMillis() - start;
System.out.printf("任务[%s]执行耗时: %dms%n", runnable.toString(), duration);
}
};
}
}
RequestContextHolder 传入线程池线程
注意完成后 finally 内清理上下文
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setTaskDecorator(runnable -> {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
return () -> {
try {
RequestContextHolder.setRequestAttributes(requestAttributes);
runnable.run();
} catch (Throwable e) {
log.warn("async runner got an throwable", e);
} finally {
RequestContextHolder.resetRequestAttributes();
}
};
});