大模型相关资源
学习入门
大语言模型综述
LLMBook-zh/LLMBook-zh.github.io
https://github.com/LLMBook-zh/LLMBook-zh.github.io
RUCAIBox/LLMSurvey
https://github.com/RUCAIBox/LLMSurvey
英文原版:
A Survey of Large Language Models
https://arxiv.org/abs/2303.18223
MiniMind 从零学习训练大模型
https://github.com/jingyaogong/minimind
self-llm
https://github.com/datawhalechina/self-llm
Happy-LLM
https://github.com/datawhalechina/happy-llm
从零实现 Llama3 模型
https://github.com/wdndev/llama3-from-scratch-zh
MetaSearch 深度迭代检索增强系统
https://github.com/marstaos/MetaSearch
Gemini CLI
https://github.com/google-gemini/gemini-cli
This account requires setting the GOOGLE_CLOUD_PROJECT env var
Failed to login. Message: This account requires setting the GOOGLE_CLOUD_PROJECT env var.
See https://goo.gle/gemini-cli-auth-docs#workspace-gca
打开 Google Cloud 控制台,查看 项目 ID
https://console.cloud.google.com/
vim ~/.zshrc
export GOOGLE_CLOUD_PROJECT="YOUR_PROJECT_ID"
source ~/.zshrc
MTEB
embeddings-benchmark / mteb
https://github.com/embeddings-benchmark/mteb
MMTEB: Massive Multilingual Text Embedding Benchmark
https://arxiv.org/abs/2502.13595
MTEB(Massive Text Embedding Benchmark) 大规模文本嵌入基准测试,是一个开源的综合性评估平台,旨在系统化评测文本嵌入模型的性能。它提供了多种语言的数十个数据集,用于各种 NLP 任务,例如文本分类、聚类、检索和文本相似性的评估。
MTEB 包含以下 8 种任务类型:
- 双语文本挖掘(Bitext Mining)
- 目标:寻找两种语言句子集之间的最佳匹配。
- 流程:输入是来自两种不同语言的两个句子集,对于来自第一个句子集的句子,找到在第二个子集中最匹配的句子。模型将句子编码成向量后用余弦相似度来寻找最相似的句子对。
- 评估指标:F1(主指标)、准确率、召回率。
- 文本分类(Classification)
- 目标:基于嵌入向量标注文本类别(如情感分析、新闻分类)
- 流程:用嵌入向量训练LR分类器(限制100次迭代),然后使用测试集来打分。
- 评估指标:准确率(多分类)、精确率(二分类)
- 文本聚类(Clustering)
- 目标:将句子或段落分组为有意义的簇
- 流程:在编码后的文档上训练一个 mini-batch k-means 模型(batch size=32, k=标签个数)
- 评估指标:V-measure(平衡同质性和完整性)
- 句子对分类(Pair Classification)
- 目标:判断两文本是否语义等价(如重复问题检测)
- 流程:计算文本对多种距离(余弦、点积、欧氏、曼哈顿等),优化阈值判断二元关系
- 评估指标:基于余弦相似度的平均精度(AP)
- 重排序(Reranking)
- 目标:根据与查询的相关性对结果进行重新排序
- 流程:输入是一个查询语句以及一个包含相关和不相关文本的列表。模型编码文本后比较与查询语句的余弦相似性。
- 评估指标:MAP(Mean Average Precision,主指标)
- 检索(Retrieval)
- 目标:从海量文档中找出相关结果(如知识库问答)
- 流程:编码查询和语料库文档,计算余弦相似度返回Top-k
- 评估指标:nDCG@10(主指标)、Recall@k、MRR@k
- 语义文本相似度(STS)
- 目标:量化句子对的语义相关性(如FAQ匹配)
- 流程:嵌入句子后计算相似度(如余弦),与人工评分标签对比
- 评估指标:基于余弦的Spearman相关系数(主指标)
- 摘要(Summarization)
- 目标:评估机器生成摘要的质量
- 流程:嵌入人工摘要与机器摘要,计算机器摘要与最近人工摘要的相似度
- 评估指标:Spearman相关性(主指标)
CMTEB
Chinese Massive Text Embedding Benchmark
https://github.com/FlagOpen/FlagEmbedding/tree/master/research/C_MTEB
Embedding 向量化
向量模型可以将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
BGE 向量模型(BAAI智源)
BAAI(Beijing Academy of Artificial Intelligence) 北京智源人工智能研究院 发布最强开源可商用中英文语义向量模型BGE(BAAI General Embedding),在中英文语义检索精度与整体语义表征能力均超越了社区所有同类模型,如 OpenAI 的 text embedding 002等。此外,BGE 保持了同等参数量级模型中的最小向量维度,使用成本更低。
BGE模型将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
C-Pack: Packed Resources For General Chinese Embeddings
https://arxiv.org/abs/2309.07597
FlagOpen / FlagEmbedding
https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
text2vec-base-chinese 中文语句转向量
中文语句转 768 维向量,可用于 语义匹配
shibing624/text2vec-base-chinese
https://huggingface.co/shibing624/text2vec-base-chinese
tao-8k
https://huggingface.co/Amu/tao-8k
Huggingface 开发者 amu 研发并开源的长文本向量表示模型,支持8k上下文长度的长文本向量表示模型,模型效果在 C-MTEB 上居前列,是当前最优的中文长文本embeddings模型之一
NDCG 归一化折损累计增益
NDCG(Normalized Discounted Cumulative Gain) 归一化折损累计增益,是信息检索和推荐系统中用于衡量排序质量的核心指标,尤其关注结果的相关性及其位置对整体效果的影响。
通常用在搜索排序任务中,在这样的任务里,通常会返回一个 list 作为搜索排序的结果进行输出,为了验证这个 list 的合理性,就需要对这个 list 的排序进行评价。
核心概念与计算逻辑
1、CG(累计增益,Cumulative Gain)
CG 仅对前 k 个结果的相关性分数简单累加,公式为:
$$CG@k = \sum_{i=1}^k rel_i$$
其中,$rel_i$ 表示第i个位置的结果相关性(比如 es 检索结果的相关性得分 _score,或者简单的召回正确得分即为1)。
局限性:CG未考虑排序位置的影响。例如,高相关性结果排在末尾与前列时,CG值相同。
2、DCG(折损累计增益,Discounted Cumulative Gain)
DCG 在 CG 基础上引入位置折扣因子,降低靠后结果的贡献。常用公式有两种:
(1)基础形式(适用于二元或分级相关性):
$$DCG@k = rel_1 + \sum_{i=2}^k \frac{rel_i}{\log_2(i+1)}$$
(2)增强形式(适用于多级相关性,如0-5分):
$$DCG@k = \sum_{i=1}^k \frac{2^{rel_i} - 1}{\log_2(i+1)}$$
核心思想:位置越靠前,对分数的贡献越大(因分母随位置增加而增大)。
3、IDCG(理想DCG,Ideal DCG)
将前 k 个结果按真实相关性从高到低排序后计算 DCG,即完美排序下的最大可能值。
$$IDCG@k = \sum_{i=1}^k \frac{2^{rel_{(i)}} - 1}{\log_2(i+1)}$$
其中,$rel_{(i)}$ 表示降序排列后的相关性分数。
4、NDCG(归一化DCG)
将 DCG 与 IDCG 的比值作为最终指标,公式为:
$$NDCG@k = \frac{DCG@k}{IDCG@k}$$
NDCG 的取值范围为[0, 1],值越接近1表示排序结果越接近理想状态。
适用领域:
- 搜索引擎:评估搜索结果排序是否符合用户需求(如高相关结果是否靠前)。
- 推荐系统:衡量推荐列表的排序质量(如热门商品是否合理分布)。
- 广告排序:优化广告投放的点击率与收益。
工具
AI工具集
https://ai-bot.cn/
AI工具中文文档库
http://www.aidoczh.com/
MCP 模型上下文协议
MCP(Model Context Protocol) 模型上下文协议,是由 Anthropic 提出并于 2024 年 11 月开源的一种通信协议,旨在解决大型语言模型(LLM)与外部数据源及工具之间无缝集成的需求。
https://mcp.so/
https://mcpservers.org/
https://github.com/modelcontextprotocol/servers
MCP server 开发示例
https://modelcontextprotocol.io/quickstart/server
GitHub MCP Server
https://github.com/github/github-mcp-server
大模型排行榜与竞技场
OpenCompass 大模型排行榜
大模型榜单
https://rank.opencompass.org.cn/home
大模型竞技场,可对比多个模型的效果
https://opencompass.org.cn/arena
Chatbot Arena 大模型竞技场
https://openlm.ai/chatbot-arena/
百度千帆文心一言免费 ERNIE-Speed 模型对接
千帆ModelBuilder 部分ERNIE系列模型免费开放公告
通过ak/sk调用v1接口(baidu格式)
1、注册百度智能云账号,找到自己的 ak,sk,需要实名认证后才能免费调用 ERNIE-Speed-8K
百度智能云-如何获取AKSK
2、进入 管理控制台 - 计费管理,选择免费的模型,开通计费。
虽然 ERNIE-Speed-128K 和 ERNIE-Speed-8K 是免费的,但也需要开通计费,否则接口调用报错 {"error_code":17,"error_msg":"Open api daily request limit reached"}
千帆 - 管理控制台 - 计费管理
3、把 postman 签名脚本加入 pre-script,配置环境变量 ak、sk
百度智能云-生成签名(认证字符串)的脚本
4、通过api调用 ERNIE-Speed
百度智能云 - 推理服务Api V1 - ERNIE-Speed-128K
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/6ltgkzya5
通过ApiKey调用v2接口(兼容OpenAI格式)
推理服务V2 - 认证鉴权
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Um2wxbaps
1、在 API Key 查看自己的 Api Key
如果没开通 千帆ModelBuilder 权限无法调用接口,需先开通
2、调接口时加个 header 即可: 'Authorization: Bearer bce-v3/ALTAK-*/2d7*'
百度智能云 - 推理服务Api V2 -- 完全兼容 OpenAI 标准
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Fm2vrveyu
UI界面
Chrome扩展 Page Assist
https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo
Open WebUI
https://github.com/open-webui/open-webui
UI界面,支持 Ollama 和 OpenAI 兼容的 API,支持网页搜索、本地 RAG 集成、权限管理、适配移动端、Markdown 和 LaTeX 等功能
LLMOps 大模型平台
Ollama 大模型部署平台
主要通过命令行操作,适合有一定技术背景的用户
https://ollama.com/
https://github.com/ollama/ollama
Mac Ollama+PageAssist本地部署DeepSeekR1
ollama 安装后直接 ollama run deepseek-r1:7b 自动下载并启动模型
或者可以分两步,先下载,再启动
ollama pull deepseek-r1:7b
ollama run deepseek-r1:7b
Mac 上的模型下载目录:~/.ollama/models
ollama ps 查看运行中的模型
ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:7b 0a8c26691023 6.0 GB 100% GPU 3 minutes from now
停止模型
ollama stop deepseek-r1:7b
注意:默认情况下,模型会在内存中保留 5 分钟后才被卸载,此间如果向模型发送对话,还会立即将模型加载起来。
可以在启动 Ollama 服务器时通过设置 OLLAMA_KEEP_ALIVE 环境变量来更改所有模型加载到内存中的时间。
退出ollama
在 Mac 顶部状态栏找到 ollama 图标,点退出即可。
LM Studio 大模型部署平台
https://lmstudio.ai/
提供图形化用户界面,使得操作更为直观和简单,适合新手和追求易用性的用户
独显 8G 以上显存,推荐选 DeepSeek-R1-Distill-Qwen-7B 或者 DeepSeek-R1-Distill-Qwen-32B
Dify 大模型应用平台
https://dify.ai/zh
LangSmith 大模型应用平台
https://www.langchain.com/langsmith
LLM DevOps平台,专门用于开发、测试、部署LLM(大语言模型)应用程序。
LangSmith 的关键功能包括链路追踪调试应用、提示工具协作构建提示、数据集管理测试数据、自动评估应用质量、一键部署等。
模型训练/微调
Search-R1
https://github.com/PeterGriffinJin/Search-R1
训练使推理大模型可调用搜索引擎
ZeroSearch
https://github.com/Alibaba-nlp/ZeroSearch?tab=readme-ov-file
模型蒸馏
手把手教你三步极速蒸馏DeepSeek R1,效果媲美OpenAI o3 mini!
https://cloud.baidu.com/news/news_2fd7c390-d23d-434f-b7d3-1689b33fd732
Unsloth 模型微调优化
https://github.com/unslothai/unsloth
用于微调和优化大型语言模型(LLM)的 Python 工具库。它通过动态量化和显存优化技术,提高了模型微调速度,同时将显存占用降低 70%-80%,并支持多种硬件配置、LLM、超长上下文任务等功能。除此之外,还提供了可直接在线体验的 Jupyter Notebook 示例,降低了大模型微调的门槛。
mlx/mlx-examples 苹果的大模型框架及示例
2023年苹果开源的适用于 macOS 和 Apple Silicon 的高效灵活的机器学习框架 MLX
https://github.com/ml-explore/mlx/
mlx-examples 库中包含了各种使用 MLX 框架的独立示例。
https://github.com/ml-explore/mlx-examples
有用示例:
1、Transformer 语言模型训练
https://github.com/ml-explore/mlx-examples/tree/main/transformer_lm
2、使用 LLMs 目录中的 LLaMA、Mistral、通义千问 等进行大规模文本生成
https://github.com/ml-explore/mlx-examples/tree/main/llms
3、采用 Mixtral 8x7B 的专家混合 (MoE) 语言模型
https://github.com/ml-explore/mlx-examples/tree/main/llms/mixtral
4、使用 LoRA 或 QLoRA 进行参数高效微调
https://github.com/ml-explore/mlx-examples/tree/main/lora
5、使用 T5 的文本到文本多任务 Transformer
https://github.com/ml-explore/mlx-examples/tree/main/t5
6、使用 BERT 进行双向语言理解
https://github.com/ml-explore/mlx-examples/tree/main/bert
7、用 Stable Diffusion生成图像
https://github.com/ml-explore/mlx-examples/tree/main/stable_diffusion?ref=geekyuncle.com
8、使用 OpenAI 的 Whisper 进行语音识别
https://github.com/ml-explore/mlx-examples/tree/main/whisper?ref=geekyuncle.com
性能优化
大模型推理性能指标(TTFT/TGR)
大语言模型推理后端基准评测
https://zhuanlan.zhihu.com/p/711229268
Time to First Token (TTFT):表示由发送请到模型吐出第一个token的时间(以毫秒计)
Token Generation Rate (TGR):以秒为单位,衡量一秒种内系统吐出的tokens数。
LLM 推理的核心指标
https://ninehills.tech/articles/107.html
LLM 推理的核心指标:
- Time To First Token (TTFT): 首 Token 延迟,即从输入到输出第一个 token 的延迟。在在线的流式应用中,TTFT 是最重要的指标,因为它决定了用户体验。
- Time Per Output Token (TPOT): 每个输出 token 的延迟(不含首个Token)。在离线的批处理应用中,TPOT 是最重要的指标,因为它决定了整个推理过程的时间。
- Latency:延迟,即从输入到输出最后一个 token 的延迟。
Latency = (TTFT) + (TPOT) * (the number of tokens to be generated).
Latency 可以转换为 Tokens Per Second (TPS):TPS = (the number of tokens to be generated) / Latency。 - Throughput:吞吐量,即每秒针对所有请求生成的 token 数。以上三个指标都针对单个请求,而吞吐量是针对所有并发请求的。
优秀LLM
DeepSeek-V3/R1
https://www.deepseek.com/
相同水平下,训推资源仅1/10
https://github.com/deepseek-ai/DeepSeek-V3
https://github.com/deepseek-ai/DeepSeek-R1
DeepSeek V3 详细解读:模型&Infra 建设
https://mp.weixin.qq.com/s/DKdXcguKcCS5gcwIRLH-Cg
DeepSeek R1 阅读清单
https://ninehills.tech/articles/121.html
多模态大模型
LLaVA-OneVision
hf:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
arxiv:https://arxiv.org/abs/2408.03326
OpenAI Whisper 语音转文字模型
openai / whisper-large-v3
https://huggingface.co/openai/whisper-large-v3
Automatic Speech Recognition(ASR), Speech to Text (STT)
https://huggingface.co/tasks/automatic-speech-recognition
VQA 视觉问答
VQA(Visual Question Answering)指的是,给机器一张图片和一个开放式的的自然语言问题,要求机器输出自然语言答案。
答案可以是以下任何形式:短语、单词、 (yes/no)、从几个可能的答案中选择正确答案。VQA是一个典型的多模态问题,融合了CV与NLP的技术,计算机需要同时学会理解图像和文字。为了回答某些复杂问题,计算机还需要了解常识,基于常识进行推理(common-sense resoning)。
MiniCPM-V 多图/视频理解/OCR/端侧可用
MiniCPM 端侧大模型系列,是由面壁智能(ModelBest)联合 OpenBMB 开源社区和清华 NLP 实验室开源的轻量高性能端侧大模型。包含基座模型 MiniCPM 和多模态模型 MiniCPM-V 双旗舰,凭借以小博大、高效低成本的特性享誉全球。
面壁小钢炮MiniCPM通关宝典
https://modelbest.feishu.cn/wiki/D2tFw8Pcsi5CIzkaHNacLK64npg
MiniCPM端侧系列模型的使用指南
OpenBMB / MiniCPM-CookBook
https://github.com/OpenBMB/MiniCPM-CookBook
https://github.com/OpenBMB/MiniCPM-V/blob/main/README_zh.md
MiniCPM-V 是 面壁智能 面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。
特定领域大模型
Awesome Domain LLM
https://github.com/luban-agi/Awesome-Domain-LLM
LawGPT 法律中文大语言模型
https://github.com/pengxiao-song/LaWGPT
chatlaw
https://chatlaw.cloud/
知识库/知识加工
Embedding 模型中的“迟分”策略
长文本 Embedding 模型中的“迟分”策略
https://mp.weixin.qq.com/s?__biz=MzkyODIxMjczMA==&mid=2247501187&idx=1&sn=94fd0b8f53b39bd0adbaab86834996cd
JinaAI 智能切分
RAG 系统的分块难题:小型语言模型如何找到最佳断点?
https://mp.weixin.qq.com/s/_8aStJchSoHN6jYVMb0Hkw
JinaReader 网页读取
将 URL 转换为大模型友好输入,只需在前面添加 r.jina.ai 即可。
https://jina.ai/reader/
HuggingFists 低代码工作流
https://github.com/Datayoo/HuggingFists
https://github.com/Datayoo/HuggingFists/blob/main/README_ZH.md
HuggingFists 支持通过低代码的方式使用Hugging Face网站提供的各类模型
HuggingFists 还内置了丰富的数据接入、解析、处理等算子,方便用户搭建出复杂的数据处理及模型应用场景
RagFlow
https://github.com/infiniflow/ragflow
https://demo.ragflow.io/knowledge
FastGPT 知识库
https://github.com/labring/FastGPT
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
OHR-Bench 文档OCR对RAG检索效果的影响评估
opendatalab / OHR-Bench
https://github.com/opendatalab/OHR-Bench
OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation
https://arxiv.org/abs/2412.02592
检索增强生成(RAG)通过整合外部知识来增强大型语言模型(LLM),以减少幻觉,并在不进行再训练的情况下整合最新信息。作为RAG的重要组成部分,外部知识库通常是通过使用光学字符识别(OCR)从非结构化PDF文档中提取结构化数据来构建的。然而,鉴于OCR的不完美预测和结构化数据固有的非均匀表示,知识库不可避免地包含各种OCR噪声。在本文中,我们介绍了OHRBench,这是了解OCR对RAG系统级联影响的第一个基准。OHRBench包括来自六个真实RAG应用领域的350个精心挑选的非结构化PDF文档,以及从文档中的多模态元素中导出的问答,挑战了用于RAG的现有OCR解决方案。为了更好地了解OCR对RAG系统的影响,我们识别了两种主要类型的OCR噪声:语义噪声和格式噪声,并应用扰动来生成一组具有不同程度OCR噪声的结构化数据。使用OHRBench,我们首先对当前的OCR解决方案进行了全面评估,发现没有一个解决方案能够为RAG系统构建高质量的知识库。然后,我们系统地评估了这两种噪声类型的影响,并证明了RAG系统的脆弱性。此外,我们讨论了在RAG系统中使用没有OCR的视觉语言模型(VLM)的潜力。
MinerU 扫描件pdf解析转md/json
一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。
https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
Dingo 数据质量评估
https://github.com/DataEval/dingo/blob/dev/README_zh-CN.md
Dingo 是一款数据质量评估工具,帮助你自动化检测数据集中的数据质量问题。Dingo 提供了多种内置的规则和模型评估方法,同时也支持自定义评估方法。Dingo 支持常用的文本数据集和多模态数据集,包括预训练数据集、微调数据集和评测数据集。
主要用于评估大模型训练数据集的质量。
主要有两种质量评估方式:
1、基于规则的
https://github.com/DataEval/dingo/blob/main/dingo/model/rule/rule_common.py
例如
- RuleDocRepeat 文本重复
- RuleIDCard 包含身份证号
- RuleSpecialCharacter 包含特殊字符
2、基于大模型的
https://github.com/DataEval/dingo/blob/main/dingo/model/prompt/prompt_text_quality.py
例如:
- PromptTextQualityV3: Your primary objective is to assess the suitability of this dataset for training a large language model
ChatGPT 资源
免费chatgpt3.5
https://chat18.aichatos98.com/
低价购买gpt试用账号
https://xedu.me/
OpenAI API 代理
https://www.openai-proxy.com/
直接将官方接口域名 api.openai.com 替换为 https://api.openai-proxy.com 即可在国内网络环境下直接调用,支持SSE。
https://openai-sb.com/
Agent 智能体
Manus 动作执行AI智能体
https://manus.im/
LangGraph(LangChain出品) agent 框架
https://github.com/langchain-ai/langgraph
agent-service-toolkit 智能体工具包(内含LangGraph)
https://github.com/JoshuaC215/agent-service-toolkit
该项目能够帮助开发者用 Python 快速搭建和运行基于 LangGraph 框架的 AI 代理服务。它结合 FastAPI、Streamlit 和 Pydantic 等技术栈,提供了用户界面、自定义 Agent、流式传输等功能,并集成了内容审核(LlamaGuard)和用户反馈机制(LangSmith),极大地简化了 AI Agent 应用的开发和优化过程。
基于qwen的agent demo
https://github.com/owenliang/agent
Wren AI 文本转sql智能体
开源 Text-to-SQL 智能体
https://github.com/Canner/WrenAI?tab=readme-ov-file
OpenAI swarm agent 编排框架
https://github.com/openai/swarm
CrewAI Agent 智能体框架
https://docs.crewai.com/introduction
LLM Powered Autonomous Agents
LLM Powered Autonomous Agents
https://lilianweng.github.io/posts/2023-06-23-agent/
剖析BabyAGI:原生多智能体案例一探究竟
https://blog.csdn.net/Attitude93/article/details/136415737
coze/扣子-智能体编排
bot编排,app商店
https://www.coze.cn/home
LLM 相关资源
langchain-java
https://github.com/HamaWhiteGG/langchain-java
Poe 大模型聚合
https://poe.com/
从零开始写一个gpt
https://www.youtube.com/watch?v=kCc8FmEb1nY&ab_channel=AndrejKarpathy
LangGPT prompt 学习
https://aq92z6vors3.feishu.cn/wiki/RXdbwRyASiShtDky381ciwFEnpe
Express+Vue3实现gpt页面
https://github.com/Chanzhaoyu/chatgpt-web
llm.c 纯c实现训练gpt-2
https://github.com/karpathy/llm.c
morphic-问答式AI搜索
https://www.morphic.sh/
https://github.com/miurla/morphic
kimi-长文档理解
kimi 超长文档、链接内容总结
https://kimi.moonshot.cn/
RAG 检索增强
RAG(Retrieval Augmented Generation,检索增强生成)是一个将大规模语言模型(LLM)与来自外部知识源的检索相结合的框架。
为什么需要 RAG?
LLM 的训练集是固定的,知识是静态、封闭、有限的,在具体细分行业使用 LLM 时,需要结合外部检索工程框架弥补 LLM 知识不足的问题。
RAG 基本流程:
1、知识索引。
事先将文本数据进行处理,通过向量化技术(embedding)将文本映射到向量空间并存储到向量数据库中,或者利用 Elasticsearch 全文索引文档,构建出可检索的知识片段。
涉及文档处理、文档分割、向量化、向量数据库。
2、知识检索。
输入问题,在知识库中进行检索(向量相似度匹配、全文检索),找到与问题最相关的一批文档。
3、问答。
把问题+检索得到的与问题最相关的文档一起输入到 LLM,让 LLM 根据相关文档回答问题,甚至返回答案所引用的文档,这里需要仔细的调整 prompt
Applying OpenAI's RAG Strategies
https://blog.langchain.dev/applying-openai-rag/
langchain 文档分割demo
https://langchain-text-splitter.streamlit.app/
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本。
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
知识图谱
HippoRAG2
https://github.com/OSU-NLP-Group/HippoRAG/tree/main
HippoRAG 2 是由俄亥俄州立大学团队于2025年推出的检索增强生成(RAG)框架,旨在通过模拟人类长期记忆的神经机制,突破传统RAG在多跳推理、动态知识整合和上下文关联性方面的局限性。其核心创新在于结合知识图谱(KG)与个性化PageRank(PPR)算法,实现更接近人类记忆的智能问答系统。
一、离线索引:构建开放知识图谱
三元组提取:使用LLM从文本中抽取(主语-关系-宾语)三元组,例如从“托马斯研究阿尔茨海默病”提取 (Thomas, researches, Alzheimer's)。
同义词消歧:基于嵌入模型(如NV-Embed-v2)检测短语相似性,添加同义词边(如“AI”与“人工智能”关联)。
密集-稀疏集成:
- 短语节点:稀疏编码表示核心概念(如“斯坦福大学”)。
- 段落节点:密集编码保留上下文细节(如教授履历)。
二、在线检索:上下文感知的关联推理
查询链接:通过嵌入模型匹配查询与KG中的三元组和段落,定位种子节点(如将“阿尔茨海默病研究”链接到相关节点)。
识别记忆过滤:LLM过滤无关三元组,例如剔除“胶水粘奶酪”等错误信息。
个性化 PageRank 算法:
- 随机游走:基于种子节点权重(如斯坦福大学、阿尔茨海默病)计算节点重要性。
- 公式简化:PR(v) = (1-d) * seed(v) + d * Σ(PR(u)/out_degree(u)),其中阻尼因子d=0.5。
段落排序:根据PageRank得分返回最相关段落,用于最终问答生成。
LightRAG
https://github.com/HKUDS/LightRAG
LightRAG 是一个高效、轻量级的检索增强生成(Retrieval-Augmented Generation, RAG)框架,旨在简化复杂文档的检索与生成任务。其核心特点是 快速构建知识图谱 与 多模式检索能力,支持多种文件类型(PDF、DOC、PPT、CSV等)和灵活的模型集成。
多模式检索:
- 本地模式 (Local): 基于上下文依赖的实体检索。
- 全局模式 (Global): 利用全局知识图谱关系检索。
- 混合模式 (Hybrid/Mix): 结合知识图谱与向量检索,提供更全面的答案。
- Naive模式: 基础检索,无复杂处理。
GraphRAG
https://github.com/microsoft/graphrag
GraphRAG 是微软开源的一个基于知识图谱的检索增强生成(RAG)系统,旨在通过结构化数据提升大语言模型(LLM)对私有数据的处理能力。
知识图谱增强的RAG
与传统RAG(基于向量搜索)不同,GraphRAG 通过从非结构化文本中提取结构化知识图谱(Knowledge Graph),帮助LLM更好地理解数据间的深层关联(如实体、关系、事件)。
知识图谱作为“记忆结构”,可显著提升LLM在复杂查询(如跨文档推理、多跳问答)中的表现。
NER 命名实体识别
命名实体识别(Named Entity Recognition, NER)是自然语言处理(NLP)的核心任务之一,旨在从非结构化文本中定位并分类具有特定语义的实体(如人名、地名、组织机构名、时间、日期等)。
包括:
- 实体抽取:从文本中提取人名、地名、组织名等关键实体,作为知识图谱的节点。
- 实体链接:将识别出的实体与知识库中的现有实体匹配(如“Apple”需区分科技公司或水果)。
- 关系抽取基础:为后续实体间关系抽取提供结构化数据(如“马斯克-创立-SpaceX”)。
实体抽取与标准化
示例:从“李华在2024年访问了北京”中识别“李华”(人名)、“北京”(地名)、“2024年”(时间)。
作用:构建知识图谱的实体节点,支持后续关系抽取。
实体链接与消歧
挑战:同一实体可能有多种含义(如“Apple”指公司或水果)。
解决方案:结合上下文(如“购买iPhone”中“Apple”指向科技公司)。
关系抽取
流程:NER识别实体后,通过关系抽取模型(如PCNN)提取实体间关系。
示例:从“马斯克创立了SpaceX”中抽取“创立”关系。
SPO 主谓宾三元组
SPO(Subject-Predicate-Object) 三元组
SPO 基于句法结构的三元组,将句子的主谓宾映射为(主语,谓语,宾语)。例如:“刘翔出生于上海” →(刘翔,出生地,上海)
S(Subject):动作或状态的主体,如实体或事件。
P(Predicate):连接主宾的关系或动作。
O(Object):动作的承受者或状态对象
应用:信息抽取任务中,SPO结构便于从文本中提取结构化知识
词义消岐WSD
词义消岐(Word Sense Disambiguation, WSD),是确定多义词在特定上下文中正确含义的任务。
由于自然语言中普遍存在一词多义现象(如“苹果”可指水果或科技公司),WSD 对提升机器理解文本的准确性至关重要,尤其在翻译、问答系统和信息检索中。
“火箭”
句子1:“火箭队赢得比赛。” -> 指NBA球队
句子2:“火箭发射成功。” -> 指燃气推进装置
Neo4j 图数据库
https://neo4j.com/
https://github.com/neo4j/neo4j
Neo4j 是一款高性能的 NoSQL 图数据库,专注于处理高度互联的复杂关系数据。其核心特点是通过图结构(节点、关系、属性)存储数据,而非传统关系型数据库的表格形式。
数据模型
属性图模型:数据由 节点(Node)、关系(Relationship) 和 属性(Key-Value) 构成。例如,社交网络中用户为节点,关注关系为边,用户年龄为属性。
存储方式:数据存储在 图网络 中,而非表格,支持高效的多跳关系查询(如查找朋友的朋友)
查询语言
Cypher:Neo4j 的声明式查询语言,语法类似 SQL。例如,MATCH (a:Person)-[:FRIEND]->(b) RETURN a.name, b.name 可查询用户的朋友列表
HugeGraph 图数据库
https://hugegraph.apache.org/
Apache HugeGraph 是一款高性能、分布式的开源图数据库系统,专注于处理大规模复杂关系数据的存储与分析。
特点:
百亿级数据支持:HugeGraph 支持快速导入百亿级别的顶点和边,提供毫秒级的 OLTP(联机事务处理)关联查询能力。
分布式架构:通过自控分布式存储引擎 HStore(基于 Raft + RocksDB)实现数据分片、副本平衡与自动容灾,支持横向扩展和高可用性。
计算优化:内置大规模并行图计算框架,支持多轮迭代算法(如 PageRank、最短路径),并优化超级点处理,避免数据倾斜问题。
标准化与兼容性
兼容 Gremlin:完全支持 Apache TinkerPop3 框架,用户可直接使用 Gremlin 语言进行复杂图遍历与查询。
多后端存储:支持 RocksDB、Cassandra、HBase 等多种存储引擎,并可插件化扩展。
Text2Cypher 文本转Cypher语法
https://neo4j.com/labs/neodash/2.4/user-guide/extensions/natural-language-queries/
Text2Cypher 是一种将自然语言转换为图数据库查询语言(Cypher)的技术,旨在通过大语言模型(LLM)降低用户与图数据库交互的门槛。
Text2Cypher 的核心是通过 LLM 理解用户自然语言中的查询意图,结合图数据库的 Schema(如节点、关系、属性),生成符合 Cypher 语法的查询语句。
例如,用户提问“雨果·维文参演了哪些电影?”,LLM 会将其转换为
MATCH (p:Person {name: 'Hugo Weaving'})-[:ACTED_IN]->(m:Movie) RETURN m.title
Mermaid 文字转图表
https://mermaid.nodejs.cn/intro/
Mermaid 允许你使用文本和代码创建图表和可视化。
Mermaid 是一个基于 JavaScript 的图表绘制工具,可渲染 Markdown 启发的文本定义以动态创建和修改图表。
Mermaid 是一种基于文本的轻量级图表生成工具,通过类似 Markdown 的简洁语法定义流程图、时序图、甘特图等复杂图形。它由 JavaScript 驱动,可直接嵌入文档并自动渲染为矢量图表,是技术文档编写、项目管理和数据可视化领域的高效工具
token数计算
你提问耗费了 100 token,GPT 根据你的输入,生成文本(也就是回答)了 200 token,那么一共消费的 token 数就是 300 。
通常,4 个英文字符占一个token,而1个汉字大致是1个token
gpt 会忽略空格,用 https://charactercalculator.com/zh-cn/ 看忽略空格的字符数
OpenAI tokenizer 工具计算token数
在 openAI 网站上有工具
https://platform.openai.com/tokenizer
OpenCompass 大模型评测
困惑度 PPL(perplexity)
将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。
例如,若模型在 问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。
infer_cfg 推理配置
infer_cfg 配置使用了 OpenICL 的思想,使用 retriever 从数据集中查询出一些 上下文样例in-context example,拼入 prompt 模板中。
infer_cfg 配置示例:
infer_cfg=dict(
ice_template=dict( # 用于构造 In Context Example (ice) 的模板
type=PromptTemplate,
template='{question}\n{answer}'
),
prompt_template=dict( # 用于构造主干 prompt 的模板
type=PromptTemplate,
template='Solve the following questions.\n</E>{question}\n{answer}',
ice_token="</E>"
),
retriever=dict(type=FixKRetriever, fix_id_list=[0, 1]), # 定义 in context example 的获取方式
inferencer=dict(type=GenInferencer), # 使用何种方式推理得到 prediction
)
retriever 上下文样例检索方法
retriever 配置上下文样例的获取方式
ZeroRetriever(zero-shot) 零样本
retriever 是 ZeroRetriever 就是 zero-shot 零样本,不需要查询 in-context example
few-shot 少量样本
其他 retriever 是 few-shot,需要定义 ice_template 字段,设置 上下文样例 In Context Example(ICE) 的模板
inferencer 推理类型
OpenCompass 中主要支持了两种 Infernecer:GenInferencer 和 PPLInferencer
PPLInferencer 判别式推理
PPLInferencer 对应判别式推理。在推理时,模型被要求计算多个输入字符串各自的混淆度 (PerPLexity / ppl),并将其中 ppl 最小的项作为模型的推理结果。
GenInferencer 生成式推理
GenInferencer 对应生成式的推理。在推理时,模型被要求以输入的提示词为基准,继续往下续写。
OpenICL
Shark-NLP / OpenICL
https://github.com/Shark-NLP/OpenICL
OpenICL 是一个用于 上下文学习(In-context learning) 的工具包,同时也是一个 LLM 评估开源工具包,OpenCompass 中的评估就使用了 OpenICL
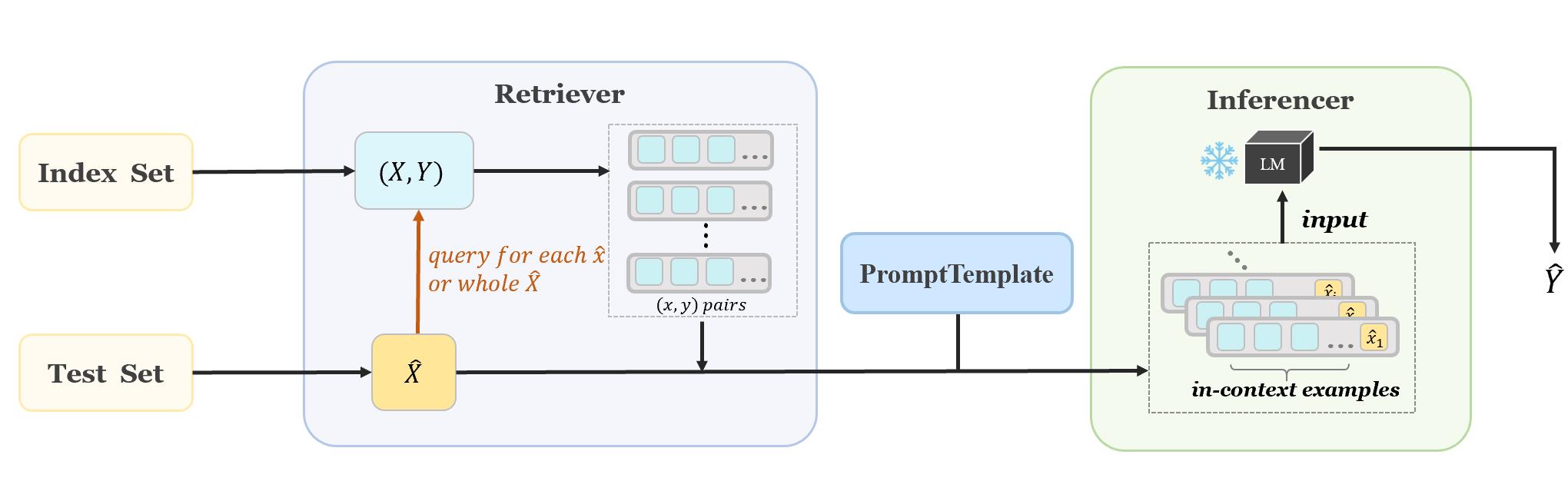
OpenICL 流程
OpenICL 流程:通过用户指定的检索方法(例如TopK或VoteK)从索引集中获取适当的上下文示例,插入到 prompt 模板中,一起输入到大模型。
如何快速地设计并评估fewshot示例的效果:OpenICL上下文示例学习框架推荐及实现源码
https://aibard123.com/digest/2023/1120/如何快速地设计并评估fewshot示例的效果OpenICL上下文示例学习框架推荐及实现源码/
AGIEval 中文测试集
https://opendatalab.com/OpenDataLab/AGIEval/tree/main/raw
JTokkit 用于大模型的Java分词编码库
https://github.com/knuddelsgmbh/jtokkit
计算 token 数
encoding.countTokens("This is a sample sentence.");
编码:
IntArrayList encoded = encoding.encode("This is a sample sentence.");
chat/completions ChatGPT聊天补全API
https://platform.openai.com/docs/api-reference/chat/create
基本上使用 https://api.openai.com/v1/chat/completions 这个核心 API 就行。
认证
sk 放 header 中即可
messages 角色 role
- user 用户问的问题或指令放 messages 中的 user role
- assistant 多轮对话时,gpt返回的内容放 assistant 中
- system 角色扮演的 promt 放 system 中
多轮对话
传入 messages 列表,将之前 gpt 的返回放到 assistant role 中
流式返回
stream 传 true,会开启 Server-Send Events(SSE),服务端主动将回答内容流式推送给客户端。
top_p
温度参数 temperature
默认值 1
值越大(如0.8或0.9),回答越随机越有创造性,适合:写故事、创意写作等
当温度值接近0时如0.2或0.3),模型生成的文本将更加确定和一致,适合:回答问题、提供事实等
示例:
{
"model": "gpt-3.5-turbo",
"temperature": 0.5,
"stream": true,
"messages": [
{
"role": "user",
"content": "如何使用Postman来测试ChatGPT的Stream API"
}
]
}