MongoDB
MongoDB中文手册|官方文档中文版
https://docs.mongoing.com/
CEPH 分布式存储系统
Ceph 是一个开源的分布式存储系统,旨在提供高性能、高可用性和高扩展性的存储解决方案。
它支持三种存储接口:对象存储(RADOSGW)、块存储(RBD)和文件系统存储(CephFS),能够满足不同应用场景的需求。Ceph 的核心设计理念是去中心化、自我修复和自动平衡,使其能够轻松应对大规模存储环境的挑战。
Ceph 的主要组件:
- RADOS(Reliable Autonomic Distributed Object Store)
核心存储层:RADOS 是 Ceph 的基石,负责实际的数据存储和管理。它由多个 OSD(Object Storage Daemon)组成,每个 OSD 管理一个或多个存储设备。
数据分布:RADOS 使用 CRUSH(Controlled Replication Under Scalable Hashing)算法来分布数据,确保数据在集群中的均匀分布,并支持动态扩展。 - LIBRADOS
编程接口:LIBRADOS 提供了对 RADOS 的直接访问接口,允许应用程序直接与 Ceph 存储集群交互。 - RADOSGW(RADOS Gateway)
对象存储接口:RADOSGW 提供了兼容 Amazon S3 和 OpenStack Swift 的 RESTful API,使得 Ceph 可以作为对象存储使用。 - RBD(RADOS Block Device)
块存储接口:RBD 提供了基于 RADOS 的块设备,可以像普通磁盘一样挂载到虚拟机或物理机上,常用于虚拟化环境。 - CephFS
文件系统接口:CephFS 是一个基于 RADOS 的分布式文件系统,提供了 POSIX 兼容的文件系统接口,适用于需要共享文件存储的场景。 - MON(Monitor)
集群监控:MON 负责监控集群状态,维护集群成员信息和集群状态图(Cluster Map)。通常需要奇数个 MON 节点(如 3 个、5 个)以保证高可用性。 - MDS(Metadata Server)
元数据服务:MDS 仅在 CephFS 中使用,负责管理文件系统的元数据,如目录结构、文件属性等。MDS 不是必需的,对于简单的块存储或对象存储场景,可以不需要 MDS。
数据分布与复制
- Ceph 使用 CRUSH 算法来计算对象应该存储在哪个 OSD 上。CRUSH 算法考虑了集群的拓扑结构(如机架、主机、磁盘等),以确保数据在集群中的均匀分布。
- 数据在存储时会被复制到多个 OSD 上(通常为 3 份),以提高数据的可用性和容错性。
自我修复与平衡
- 当 OSD 发生故障或新 OSD 加入时,Ceph 会自动触发数据迁移和重新平衡过程,以确保数据均匀分布和冗余度。
读写操作
- 客户端通过 LIBRADOS 或特定接口(如 RADOSGW、RBD、CephFS)与 Ceph 集群交互。
- 写操作:数据被分割成对象,计算其放置位置,并写入到相应的 OSD 上。
- 读操作:根据对象的位置信息,从相应的 OSD 上读取数据。
简介
MongoDB 是 C++ 编写的一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为 Web 应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于 Json 对象。字段值可以包含其他文档,数组及文档数组。
MongoDB 与 Redis 比较
MongoDB 文件存储是 Bson 格式,类似 Json, 或自定义的二进制格式。MongoDB 与 Redis性能都很依赖内存的大小,MongoDB有丰富的数据表达、索引;最类似于关系数据库,支持丰富的查询语言,Redis数据丰富,较少的 IO,这方面MongoDB优势明显。
MongoDB 不支持事务,靠客户端自身保证,Redis 支持事务,比较弱,仅能保证事务中的操作按顺序执行,这方面Redis优于MongoDB。
MongoDB 对海量数据的访问效率提升,Redis 较小数据量的性能及运算,这方面MongoDB优于Redis。
MongoDB 有 MapReduce 功能,提供数据分析,Redis没有,这方面MongoDB优于Redis。
MongoDB 与关系数据库术语对比
mongodb 与关系型数据库的对比
| 关系数据库概念 | MongoDB概念 | 说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 无 | 表连接,MongoDB 不支持(嵌套文档) |
| primary key | primary key | 主键,MongoDB 自动将 _id 字段设置为主键 |
| aggregate(group) | aggregate(pipeline mapReduce) | 聚合 |
场景
适用场景
1)实时的CRU操作,例如网站、论坛的实时数据处理。它非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2)缓存。由于性能很高,它适合作为信息基础设施的缓存层。在系统重启之后,由它搭建的持久化缓存层可以避免下层的数据源过载。
3)高伸缩性的场景,分布式集群动态增删节点。非常适合由数十或数百台服务器组成的数据库,内部包含对 MapReduce 引擎的内置支持。
4)用于对象及 JSON 数据的存储:Mongo 的 BSON 数据格式非常适合文档化格式的存储及查询
不适用场景
1)高度事务性操作,如银行或会计系统。
2)传统商业智能(BI)应用,如提供高度优化的查询方式。
3)复杂的跨文档(表)级联查询。
选型决策
列出应用特征的 Yes/No 选项
1、应用不需要事务及复杂 join 支持必须 Yes
2、新应用,需求会变,数据模型无法确定,想快速迭代开发?
3、应用需要2000-3000以上的读写QPS(更高也可以)?
4、应用需要TB甚至 PB 级别数据存储?
5、应用发展迅速,需要能快速水平扩展?
6、应用要求存储的数据不丢失?
7、应用需要99.999%高可用?
8、应用需要大量的地理位置查询、文本查询?
如果上述有1个 Yes,可以考虑 MongoDB,2个及以上的 Yes,选择MongoDB绝不会后悔
场景举例
游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新
物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
视频直播,使用 MongoDB 存储用户信息、礼物信息等
MongoDB 数据类型
String 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
Integer 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
Boolean 布尔值。用于存储布尔值(真/假)。
Double 双精度浮点值。用于存储浮点值。
Min/Max keys 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
Arrays 用于将数组或列表或多个值存储为一个键。
Timestamp 时间戳。记录文档修改或添加的具体时间。
Object 用于内嵌文档。
Null 用于创建空值。
Symbol 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
Date 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
Object ID 对象 ID。用于创建文档的 ID。
Binary Data 二进制数据。用于存储二进制数据。
Code 代码类型。用于在文档中存储 JavaScript 代码。
Regular expression 正则表达式类型。用于存储正则表达式。
MongoDB WiredTiger 存储引擎
MongoDB 2.8 开始,WiredTiger 作为一个可选的存储引擎。
MongoDB 从 3.2 版本开始,使用 WiredTiger 作为默认的存储引擎(之前是 MMAPv1)。
WiredTiger 存储引擎可以支持 B-Tree 和 LSM 两种结构组织数据,MongoDB 在使用 WiredTiger 作为存储引擎时默认配置是使用了 B-Tree 结构。
磁盘文件
WiredTiger 在磁盘上的数据文件主要是:
- collection-xxx.wt 数据文件
- index-xxx.wt 索引文件
查看collection对应的磁盘存储文件
db.col.stats({"indexDetails":true}) 查看collection对应的磁盘存储文件:
例如 db.getCollection('20231012.chunks').stats({"indexDetails":true});
{
"sharded" : true,
"capped" : false,
"wiredTiger" : {
"uri" : "statistics:table:public.45storage/collection-103--6147808241749407599"
}
"indexDetails" : {
"_id_" : {
"type" : "file",
"uri" : "statistics:table:public.45storage/index-104--6147808241749407599"
},
"files_id_hashed" : {
"metadata" : {
"formatVersion" : 8
},
"type" : "file",
"uri" : "statistics:table:public.45storage/index-105--6147808241749407599"
},
"files_id_1_n_1" : {
"metadata" : {
"formatVersion" : 12
},
"type" : "file",
"uri" : "statistics:table:public.45storage/index-109--6147808241749407599"
}
}
}
数据文件为 collection-103--6147808241749407599
此collection有三个索引,分别对应3个 index- 文件
MongoDB 磁盘碎片整理
drop db 会立即释放磁盘空间。
drop collection 会立即释放磁盘空间。
从 collection 中 remove 删除文档后,size 的值会减少,但 storageSize 的值不一定会减少。当 storageSize 大于 size 时,表示已产生磁盘碎片。再次向 collection 中插入数据会复用磁盘碎片空间
查看全部collection大小及文档数
查看 MongoDB 当前 db 中全部 collection 大小:
查看当前db中全部 collection 大小:
db.getCollectionNames().forEach((item, index) => { print(item, db.getCollection(item).totalSize()/1024/1024, 'MB') });
查看当前db中全部 collection 大小,带文档数:
db.getCollectionNames().forEach((col) => { print(col, db.getCollection(col).totalSize()/1024/1024, 'MB,', db.getCollection(col).count(), '文档数') });
查看collection可释放磁盘碎片空间大小
https://www.mongodb.com/docs/manual/reference/command/collStats/#output
1、方法1
(1)在单实例 MongoDB 上,执行 db.getCollection('colName').stats().wiredTiger["block-manager"]
file bytes available for reuse 就是预计可回收磁盘空间
mongos> db.getCollection('user_20230516').stats().wiredTiger["block-manager"]
{
"allocations requiring file extension" : 94415,
"blocks allocated" : 173636,
"blocks freed" : 72784,
"checkpoint size" : 18899197952,
"file allocation unit size" : 4096,
"file bytes available for reuse" : 9609216,
"file magic number" : 120897,
"file major version number" : 1,
"file size in bytes" : 18908823552,
"minor version number" : 0
}
(2)在 MongoDB 分片集群上,需要看每个 shard 中的 file bytes available for reuse 并相加
{
"sharded" : true,
"capped" : false,
"ns" : "users.20231015.chunks",
"count" : 8,
"size" : 1917318,
"storageSize" : 84805332992,
"totalIndexSize" : 21622784,
"totalSize" : 84826955776,
"avgObjSize" : 239664,
"nindexes" : 3,
"nchunks" : 1867,
"shards" : {
"mongodb-shard-2" : {
"ns" : "users.20231015.chunks",
"size" : 0,
"count" : 0,
"storageSize" : 12288,
"freeStorageSize" : 4096,
"capped" : false,
"wiredTiger" : {
"block-manager" : {
"allocations requiring file extension" : 1,
"blocks allocated" : 48672,
"blocks freed" : 220305,
"checkpoint size" : 0,
"file allocation unit size" : 4096,
"file bytes available for reuse" : 4096,
"file magic number" : 120897,
"file major version number" : 1,
"file size in bytes" : 12288,
"minor version number" : 0
}
},
"nindexes" : 3,
"totalIndexSize" : 4444160,
"totalSize" : 4456448
},
"mongodb-shard-0" : {
"ns" : "users.20231015.chunks",
"size" : 958659,
"count" : 4,
"avgObjSize" : 239664,
"storageSize" : 41290293248,
"freeStorageSize" : 41289293824,
"capped" : false,
"wiredTiger" : {
"type" : "file",
"uri" : "statistics:table:public.45storage/collection-163-9018203968001408105",
"block-manager" : {
"allocations requiring file extension" : 0,
"blocks allocated" : 50727,
"blocks freed" : 221557,
"checkpoint size" : 983040,
"file allocation unit size" : 4096,
"file bytes available for reuse" : 41289293824,
"file magic number" : 120897,
"file major version number" : 1,
"file size in bytes" : 41290293248,
"minor version number" : 0
}
},
"nindexes" : 3,
"totalIndexSize" : 8634368,
"totalSize" : 41298927616
},
"mongodb-shard-1" : {
"ns" : "users.20231015.chunks",
"size" : 958659,
"count" : 4,
"avgObjSize" : 239664,
"storageSize" : 43515027456,
"freeStorageSize" : 43514036224,
"capped" : false,
"wiredTiger" : {
"type" : "file",
"uri" : "statistics:table:public.45storage/collection-124-5520456299697473172",
"block-manager" : {
"allocations requiring file extension" : 116,
"blocks allocated" : 68053,
"blocks freed" : 248551,
"checkpoint size" : 974848,
"file allocation unit size" : 4096,
"file bytes available for reuse" : 43514036224,
"file magic number" : 120897,
"file major version number" : 1,
"file size in bytes" : 43515027456,
"minor version number" : 0
}
},
"nindexes" : 3,
"totalIndexSize" : 8544256,
"totalSize" : 43523571712
}
},
"ok" : 1
}
2、方法2
执行 db.runCommand({collStats: "colName"}),看返回的统计信息
几个关键字段:
- size 表示集合的逻辑存储大小,单位 bytes
- storageSize 表示集合的物理存储大小,单位 bytes
- freeStorageSize 磁盘碎片中空闲并可以被回收的磁盘空间,单位 bytes
如果是 Mongo 分片集群的话,这些统计信息在每个 shard 分片中,需要将各个 shard 的统计信息加起来
"mongodb-shard-0" : {
"ns" : "db.colName",
"size" : 9743609,
"count" : 41,
"avgObjSize" : 237649,
"storageSize" : 60178153472,
"freeStorageSize" : 60168359936,
"capped" : false,
...
}
mongodb-shard-0 分片中,size 为 9mb,storageSize 60gb,可释放磁盘碎片 freeStorageSize 为 60gb
MongoDB 手动清理磁盘碎片
https://www.mongodb.com/docs/manual/reference/command/compact/
使用 compact 命令回收磁盘碎片 db.runCommand({ "compact": "colName", "force": true })
- 在 WriedTiger 引擎下,compact 会整理碎片后并且释放未使用的磁盘空间给系统
- 在 MMAPv1 引擎下,compact 会整理碎片,重建索引,但是不会将未使用的空间释放会给系统,而是重新分配给新插入的数据
Compact 动作最终由存储引擎 WiredTiger 完成,WiredTiger 在执行 compact 时,会不断将集合文件后面的数据往前面空闲的空间写,然后逐步 truancate 文件回收物理空间。每一轮 compact 前,WT 都会先检查是否符合 comapact 条件:
- 前面80%的空间里,是否有20%的空闲空间,用于写入文件后面20%的数据,或者
- 前面90%的空间里,是否有10%的空闲空间,用于写入文件后面10%的数据
如果上面都不满足,说明执行compact肯定无法回收10%的物理空间,此时 compact 就回退出。所以有时候遇到对一个大集合进行 compact,compact立马就返回ok,集合的物理空间也没有变化,就是因为 WiredTiger 认为这个集合没有 compact 的必要。
mongodb-shard-0:PRIMARY> db.runCommand({ "compact": "20231008.chunks", "force": true })
{
"bytesFreed" : 60184039424,
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("7fffffff000000000000000c")
},
"lastCommittedOpTime" : Timestamp(1697451830, 1),
"$configServerState" : {
"opTime" : {
"ts" : Timestamp(1697451824, 1),
"t" : NumberLong(11)
}
},
"$clusterTime" : {
"clusterTime" : Timestamp(1697451830, 1),
"signature" : {
"hash" : BinData(0,"hhMum+DVvAKO58LaFemyBc0KJ+4="),
"keyId" : NumberLong("7287038090751770647")
}
},
"operationTime" : Timestamp(1697451830, 1)
}
注意:
1、从 v4.4 版本开始,compact 命令不再阻塞正压缩的collection所属数据库的 CRUD 操作,v4.3 及之前会阻塞同数据库的 CRUD 操作。
https://www.mongodb.com/docs/v4.4/reference/command/compact/
2、分片集群中需登录每个 data 节点依次执行 compact 命令(只在 primary 分片执行 compact,并不会自动同步在 secondary 分片上执行 compact)
3、compact 命令不能在 mongos 上执行,否则报错:
mongos> db.runCommand({ "compact": "colName", "force": true })
{
"ok" : 0,
"errmsg" : "compact not allowed through mongos",
"code" : 115,
"codeName" : "CommandNotSupported",
"operationTime" : Timestamp(1697107226, 17)
}
4、在 primary 节点上执行 compact 时,必须加 force:true 参数,否则报错:
mongodb-shard-0:PRIMARY> db.runCommand({ "compact": "colName"})
{
"ok" : 0,
"errmsg" : "will not run compact on an active replica set primary as this is a slow blocking operation. use force:true to force"
}
5、在 SECONDARY 节点执行前需要先执行 rs.secondaryOk() 命令,否则 SECONDARY 不可读写,会报错:
not master and slaveOk=false
Java 清理 MongoDB 分片集群磁盘碎片
How to run Compact command on sharded mongo over mongos localhost?
https://stackoverflow.com/questions/70590344/how-to-run-compact-command-on-sharded-mongo-over-mongos-localhost
参照上面回答里的 js 脚本,在 java 中查询出分片副本信息,挨个创建 MongoClient 连接副本节点去执行 compact 命令。
MongoDB local 数据库
https://www.mongodb.com/docs/manual/reference/local-database/
每个 mongod 实例都有一个自己的 local 数据库,存储副本集元数据、oplog信息,这些信息是每个 mongod 进程独有的。
local 数据库中的 collection 只会存在本地,不会进行复制。
admin 数据库则主要存储 MongoDB 的用户、角色等信息。
local 数据库 collection:
- oplog.rs:这个集合存储了所有的写操作日志,包括插入、更新、删除等操作。它是 MongoDB 副本集的核心组件,用于实现数据的同步和复制。
- startup_log:这个集合记录了 MongoDB 服务器的启动日志,包括服务器版本、启动时间、配置信息等等。它可以用于故障排查和性能优化。
mongodb-shard-1:PRIMARY> use local
switched to db local
mongodb-shard-1:PRIMARY> show collections;
oplog.rs
replset.election
replset.initialSyncId
replset.minvalid
replset.oplogTruncateAfterPoint
startup_log
system.replset
system.rollback.id
固定集合(Capped Collections)
MongoDB 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素!
通过 createCollection 来创建一个固定集合,且 capped 选项设置为true:
>db.createCollection("cappedLogCollection",{capped:true,size:10000})
写入确认策略
https://www.mongodb.com/docs/manual/reference/write-concern/
w:1
{w: 1} 默认,数据写到Primary上(不保证journal已经写成功)就向客户端确认
w:majority
{w: "majority"} 数据写到大多数节点后再向客户端确认
内存
MongoDB 如何使用内存
目前,MongoDB 使用的是内存映射存储引擎,它会把磁盘IO操作转换成内存操作,如果是读操作,内存中的数据起到缓存的作用,如果是写操作,内存还可以把随机的写操作转换成顺序的写操作,总之可以大幅度提升性能。MongoDB 并不干涉内存管理工作,而是把这些工作留给操作系统的虚拟缓存管理器去处理,这样的好处是简化了 MongoDB 的工作,但坏处是你没有方法很方便的控制 MongoDB 占多大内存,事实上 MongoDB 会占用所有能用的内存,所以最好不要把别的服务和 MongoDB 放一起。
如何强行收回内存
1、重启mongodb,或者调用 db.runCommand({closeAllDatabases:1}) 来清除内存
2、使用Linux命令清除缓存中的数据:echo 3 > /proc/sys/vm/drop_caches
wiredTigerCacheSizeGB
mongod 提供了额外的可选参数 wiredTigerCacheSizeGB 来控制 WiredTiger 存储引擎所占用的 cache size
例如
wiredTigerCacheSizeGB=10
注意:
1、若不设置 wiredTigerCacheSizeGB 大小,mongodb 服务会根据本机内存设置内存大小
2、cache size设置较低,同时mongodb复杂查询很频繁的话,会有延迟发生。
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB 在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
db.col.getIndexes() 查看索引
> db.msg_send.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"expireAt" : 1
},
"name" : "expireAt",
"expireAfterSeconds" : NumberLong(0)
}
]
db.col.totalIndexSize() 查看索引大小
db.col.dropIndexes() 删除所有索引
db.col.dropIndex("idx_name") 删除指定索引
db.col.createIndex() 创建索引
MongoDB 使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(), 之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
从 5.0 开始会废弃 db.collection.ensureIndex()
db.collection.createIndex(keys, options)
keys 指定一个或多个索引字段,例如 {"name":1}, {"name":1, "age":-1}, 1 是升序,-1 是降序
options 选项指定索引特性
例如在后台创建索引 db.collection.createIndex({"name":1}, {background: true})
background Boolean 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 默认值为false。
unique Boolean 建立的索引是否唯一。指定为true创建唯一索引。默认值为false.
name string 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。
dropDups Boolean 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false.
sparse Boolean 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false.
expireAfterSeconds integer 指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间。
v index version 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。
weights document 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
default_language string 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
language_override string 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language.
Mongo 分片集群需要一个 hashed 索引
问题:
Mongo 分片集群查询或写入操作时报错:
com.mongodb.MongoCommandException: Command failed with error 72 (InvalidOptions): 'Please create an index that starts with the proposed shard key before sharding the collection' on server mongodb:27017. The full response is {"ok": 0.0, "errmsg": "Please create an index that starts with the proposed shard key before sharding the collection", "code": 72, "codeName": "InvalidOptions", "operationTime": {"$timestamp": {"t": 1699258459, "i": 4}}, "$clusterTime": {"clusterTime": {"$timestamp": {"t": 1699258459, "i": 4}}, "signature": {"hash": {"$binary": "gUfg03v2britWIkjGWD+wJjjh6g=", "$type": "00"}, "keyId": {"$numberLong": "7287038090751770647"}}}}
原因:
Mongo 分片集群需要一个 hashed 索引的字段做分片key,因为无 hashed 索引 key mongo 不知道如何进行分片路由
解决:
手动创建索引
mongos> db.getCollection('userinfo.chunks').createIndex({"files_id" : "hashed"});
{
"raw" : {
"mongodb-shard-0/mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-2.mongodb-headless.default.svc.cluster.local:27017" : {
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"commitQuorum" : "votingMembers",
"ok" : 1
}
},
"ok" : 1,
"operationTime" : Timestamp(1699259546, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1699259546, 3),
"signature" : {
"hash" : BinData(0,"MhvJKDwboieJ/KXlkCqloMNbxEs="),
"keyId" : NumberLong("7287038090751770647")
}
}
}
TTL索引设置数据生存时间
TTL 索引是一种特殊索引,通过这种索引 MongoDB 会过一段时间后自动移除集合中的文档。
可以设置在指定的时间段后或在指定的时间点过期,MongoDB 有独立线程去清除数据,类似于设置定时自动删除任务。
TTL 索引不能保证过期数据会被立刻删除。在文档过期和 MongoDB 从数据库中删除文档之间,可能会有延迟。
删除过期数据的后台任务每隔 60 秒运行一次。所以,在文档过期之后和后台任务运行结束之前,文档会依然存在于集合中。
Timing of the Delete Operation
https://docs.mongodb.com/manual/core/index-ttl/#timing-of-the-delete-operation
通过 db.collection.createIndex() 命令配合 expireAfterSeconds 选项来对集合中某个字段做 TTL 索引。
这个字段必须是 Date 类型或者是一个包含 Date 类型值的数组字段。
如果这个键是一个数组,那么当其中最早过期的时间得到匹配时,这篇文档就会过期失效了。
指定一段时间后过期
例如设置以下数据在 3600 秒之后过期
{
"_id": "5f43d5c00b34962beb026aad",
"createdAt": Date(),
"requestTime": 1598281152423,
"logId": "1598281152423-6245975993217447",
}
createdAt 字段是插入时间,在其上创建正序索引,指定 expireAfterSeconds 3600 秒之后过期,含义是:在 createdAt 字段的值的时刻基础上,再加上 3600 秒之后的那个时间点过期。
db.logs.createIndex({ "createdAt": 1 }, {expireAfterSeconds: 3600 })
指定过期时间点
有时为了避开访问高峰期,希望在凌晨某个时间点过期,此时可以在文档中加入一个指定过期时间点的字段,然后将 expireAfterSeconds 设为 0
例如
{
"_id": "5f43d5c00b34962beb026aad",
"createdAt": Date(),
"expireAt": ISODate("2020-09-02T11:44:11.528Z"),
"logId": "1598281152423-6245975993217447",
}
然后在 expireAt 字段创建正序索引,指定 expireAfterSeconds 为 0, 所以 Mongo 会在 expireAt 的时间点加上 0 秒后的时间点删除数据。
db.logs.createIndex({ "expireAt": 1 }, {"expireAfterSeconds": 0})
GridFS
GridFS 是 MongoDB 的一个子模块,用于分布式存储文件。
GridFS 是 MongoDB 提供的二进制数据存储方案,对于 MongoDB 的 BSON 格式的数据(文档)存储有尺寸限制,最大为 16M。
从 GridFS 存储中删除无用的垃圾文件, MongoDB 依然不会释放磁盘空间的。这会造成磁盘一直在消耗,而无法回收利用的问题。
Mongo 复制集
Mongodb 副本集是一种典型的高可用部署模式,副本集是一组服务器,一般是一个主节点(Primary)用来处理客户端的读写请求,多个副本节点(Secondary)节点对主节点的数据进行备份,以防止主节点宕机导致的单点故障。一旦主节点宕机后,那么整个副本集会进行一次新的选举,选举出一个新的节点成为主服务器。这种副本集部署模式,在主节点挂掉后,仍然可以从副本节点进行读取数据。保证业务的可用性。
MongoDB 的副本集协议(内部称为pv1),是一种 raft-like 协议,即基于 raft 协议的理论思想实现,并且对之进行了一些扩展。
心跳检测
一旦一个副本集创建成功,那么每一个节点之间都保持着通信,每 2s 会向整个副本集的其他节点发一次心跳通知,也就是一个 pings 包。在任意一个节点的数据库内部,维护着整个副本集节点的状态信息,一旦某一个节点超过10s不能收到回应,就认为这个节点不能访问。
另外,对于主节点而言,除了维护这个状态信息外,还要判断是否和大多数节点可以正常通信,如果不能,则要主动降级。
选举的前提条件,参与选举的节点必须大于等于 N/2 + 1 个节点,如果正常节点数已经小于一半,则整个副本集的节点都只能为只读状态,整个副本集将不能支持写入。也不能够进行选举。
成员角色
Primary
Secondary
正常情况下,复制集的 Seconary 会参与 Primary 选举(自身也可能会被选为 Primary),并从 Primary 同步最新写入的数据,以保证与 Primary 存储相同的数据。
Secondary 可以提供读服务,增加 Secondary 节点可以提供复制集的读服务能力,同时提升复制集的可用性。另外,Mongodb 支持对复制集的 Secondary 节点进行灵活的配置,以适应多种场景的需求。
Arbiter
Arbiter 节点只参与投票,不能被选为 Primary,并且不从 Primary 同步数据。
比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
Arbiter 本身不存储数据,是非常轻量级的服务,当复制集成员为偶数时,最好加入一个 Arbiter 节点,以提升复制集可用性。
Priority0
Priority0 节点的选举优先级为0,不会被选举为 Primary
比如你跨机房A、B部署了一个复制集,并且想指定 Primary 必须在A机房,这时可以将B机房的复制集成员Priority设置为0,这样 Primary 就一定会是A机房的成员。
(注意:如果这样部署,最好将『大多数』节点部署在A机房,否则网络分区时可能无法选出Primary)
Vote0
Mongodb 3.0 里,复制集成员最多50个,参与Primary选举投票的成员最多7个,其他成员(Vote0)的vote属性必须设置为0,即不参与投票。
Hidden 隐藏节点
Hidden 节点不能被选为主(Priority 为 0),并且对 Driver 不可见。因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务。
客户端将不会把读请求分发到隐藏节点上,即使我们设定了 复制集读选项 。
这些隐藏节点将不会收到来自应用程序的请求。我们可以将隐藏节点专用于报表节点或是备份节点。 延时节点也应该是一个隐藏节点。
Delayed 延迟节点
Delayed 节点必须是 Hidden 节点,并且其数据落后与Primary一段时间(可配置,比如1个小时)。
因 Delayed 节点的数据比 Primary 落后一段时间,当错误或者无效的数据写入 Primary 时,可通过 Delayed 节点的数据来恢复到之前的时间点。
Primary选举
复制集通过 replSetInitiate 命令(或 mongo shell 的 rs.initiate() )进行初始化,初始化后各个成员间开始发送心跳消息,并发起 Priamry 选举操作,获得『大多数』成员投票支持的节点,会成为 Primary, 其余节点成为 Secondary。
大多数
假设复制集内投票成员(后续介绍)数量为 N, 则大多数为 N/2 + 1, 当复制集内存活成员数量不足大多数时,整个复制集将无法选举出 Primary, 复制集将无法提供写服务,处于只读状态。
通常建议将复制集成员数量设置为奇数。
Mongo Sharding Cluster 分片集群
MongoDB 分片集群技术
https://www.cnblogs.com/clsn/p/8214345.html
分⽚(sharding) 是 MongoDB ⽤来将⼤型集合分割到不同服务器(或者说⼀个集群)上所采⽤的⽅法。
Sharding Cluster 使得集合的数据可以分散到多个 Shard(复制集或者单个 Mongod 节点)存储,使得 MongoDB 具备了横向扩展(Scale out)的能力
分片集群架构
Sharding cluster 由 Shard, Mongos 和 Config server 3 个组件构成:
- mongos 是一个数据路由进程,是 Sharded cluster 的访问入口,客户端应直接连接 mongos 读写数据。 Mongos 本身并不持久化数据,Sharded cluster 所有的元数据都会存储到 Config Server,而用户的数据则会分散存储到各个shard。Mongos 启动后,会从config server加载元数据,开始提供服务,将用户的请求正确路由到对应的Shard。
- Config Server 存储集群的所有元数据。包括所有shard节点的信息,分⽚功能的⼀些配置信息等。
- shard 存储真正的数据,以 chunk 为单位存数据。
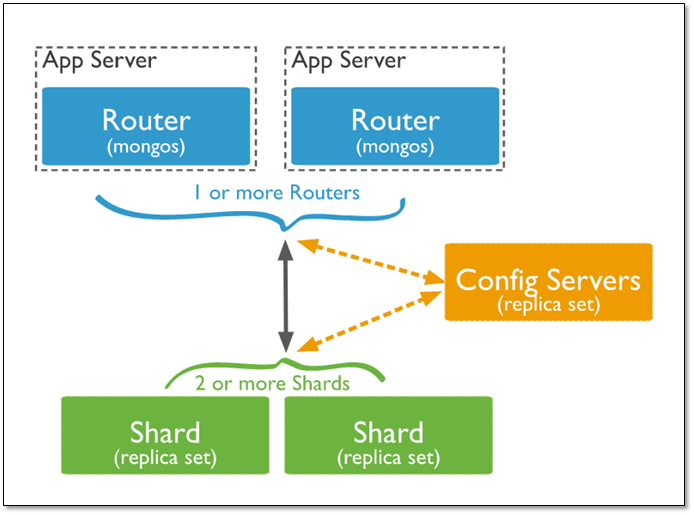
Mongo分片集群架构
mongos
mongos 根据 config server 中的分片元数据信息,将客户端发来的请求准确无误的路由到集群中的一个或一组 shard 上,同时会把接收到的响应拼装起来发回到客户端。
当数据写入时,Mongos 根据分片键设计写入数据。
当外部语句发起数据查询时,MongoDB 根据数据分布自动路由至指定节点返回数据。
Mongos 是 MongoDB 分片集群的访问入口,Mongos 收到 Client 访问请求,会根据从 Config Server 获取的路由表将请求转发到后端对应的 Shard 上。
分片集群Mongos到Shard请求管理
https://mongoing.com/archives/3983
Config Server
存储集群所有节点、分片数据路由信息。默认需要配置 3 个 Config Server 节点。
shard
分片策略
Sharded cluster 支持将单个集合的数据分散存储在多个 shard 上,用户可以指定根据集合内文档的某个字段即 shard key 来分布数据,目前主要支持 2 种数据分布的策略:
- 范围分片(Range based sharding)
- hash分片(Hash based sharding)
片键shard key
MongoDB 中数据的分片是以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。
对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB 按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。
分片键是不可变。
分片键必须有索引。
分片键大小限制512bytes。
分片键用于路由查询。
MongoDB不接受已进行collection级分片的collection上插入无分片键的文档(也不支持空值插入)
范围分片(range)
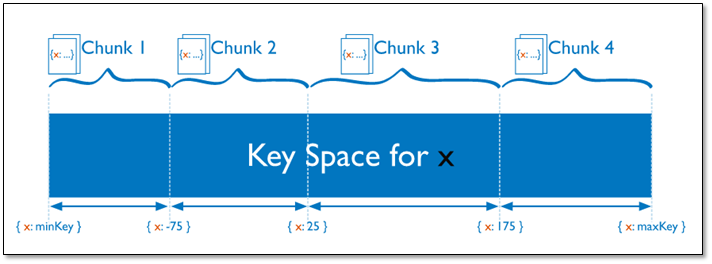
范围分片
对于基于范围的分片,MongoDB 按照片键的范围把数据分成不同部分。
假设有一个数字的片键:想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点。MongoDB 把这条直线划分为更短的不重叠的片段,并称之为数据块,每个数据块包含了片键在一定范围内的数据。在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
优势:范围查询性能好,
劣势:数据分布不均,有热点。
哈希分片(hash)
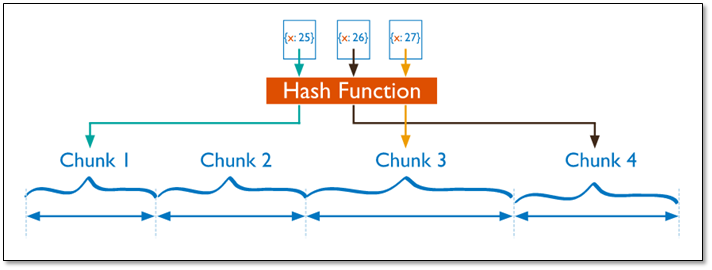
哈希分片
对于基于哈希的分片,MongoDB 计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有”相近”片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
优势:数据分布均匀
劣势:范围查询效率低
chunk
在一个 shard server 内部,MongoDB 还是会把数据分为 chunks, 每个 chunk 代表这个 shard server 内部一部分数据。
Splitting 当一个 chunk 的大小超过配置中的 chunk size 时,MongoDB 的后台进程会把这个 chunk 切分成更小的 chunk,从而避免 chunk 过大的情况
Balancing 在 MongoDB 中,balancer 是一个后台进程,负责 chunk 的迁移,从而均衡各个 shard server 的负载,系统初始 1 个 chunk,chunk size 默认值 64M, 生产库上选择适合业务的 chunk size是最好的,如果单位时间内的存储需求很大,设置更大的 chunk。MongoDB 会自动拆分和迁移 chunks。
chunk size选择
MongoDB 默认的 chunkSize 为 64MB,如无特殊需求,建议保持默认值;chunkSize 会直接影响到 chunk 分裂、迁移的行为。
chunkSize 越小,chunk 分裂及迁移越多,数据分布越均衡;反之,chunkSize 越大,chunk 分裂及迁移会更少,但可能导致数据分布不均。
chunkSize 太小,容易出现 jumbo chunk(即 shardKey 的某个取值出现频率很高,这些文档只能放到一个 chunk 里,无法再分裂)而无法迁移;
chunkSize 越大,则可能出现 chunk 内文档数太多(chunk 内文档数不能超过 250000 )而无法迁移。
chunk 自动分裂只会在数据写入时触发,所以如果将 chunkSize 改小,系统需要一定的时间来将 chunk 分裂到指定的大小。
chunk 只会分裂,不会合并,所以即使将 chunkSize 改大,现有的 chunk 数量不会减少,但 chunk 大小会随着写入不断增长,直到达到目标大小。
chunk 的分裂和迁移非常消耗 IO 资源;
chunk 分裂的时机:在插入和更新,读数据不会分裂。
chunksize的选择:
- 小的 chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。
- 大的chunksize:数据分裂少。数据块移动集中消耗IO资源。通常100-200M
chunk分裂与迁移
随着 chunk 中数据的增长,chunk 的大小超过了配置的 chunk size(默认是64M),则这个 chunk 就会分裂成两个。数据的增长会让 chunk 分裂得越来越多。
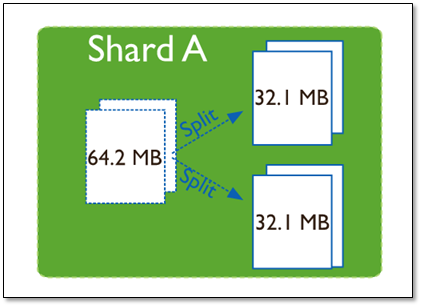
chunk分裂
这时候,各个 shard 上 chunk 的数量就会不平衡。此时,mongos 中的一个组件 balancer 就会执行自动平衡。把 chunk 从数量最多的 shard 节点挪动到数量最少的节点。
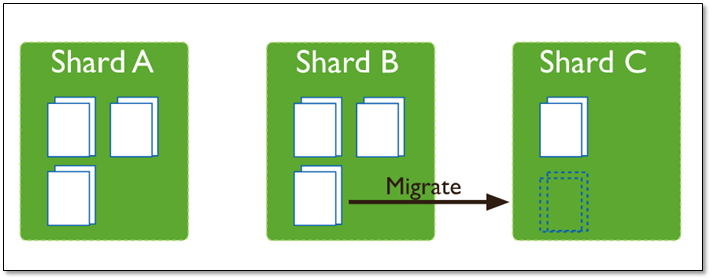
chunk迁移
not master and slaveOk=false
在 SECONDARY 节点执行命令报错:
mongodb-shard-2:SECONDARY> show dbs;
uncaught exception: Error: listDatabases failed:{
"operationTime" : Timestamp(1697601119, 3),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotPrimaryNoSecondaryOk"
}
原因:
SECONDARY 不可读写
解决:
先在 SECONDARY 节点执行 rs.secondaryOk() 命令,之后 SECONDARY 节点就可读写了。
MongoDB 分片集群 Balance 机制
为什么需要 Balance?
MongoDB 分片集群在日常的使用过程中有以下几个场景需要 Balance 机制做 Shard 间的数据迁移:
1、写入数据的分布不均匀。分片集群在设置 Range 或者 Hashed 的分片策略后,如果写入的数据 sharding key 分布不均匀,会造成多个 shard 上 的 chunk 数量分布不均匀,需要 Balance 机制介入;
2、用户调用 removeShard 命令后,被移除的 shard 上的 chunk 会被全部迁移到其他的 shard 上;
注意:如果用户想要移除的 shard 为 primary shard,则无法发起 removeShard,需要用户手动发起 movePrimary 做 primary shard 的数据迁移后再执行 removeShard
3、MongoDB 支持 shard tag 功能,可以对指定的 shard 打上标签,然后将指定的 key range 内的 chunk 分配到指定的 taged shard 上,例如:
// shard和tag一对一
// 给 shard-A 打上标签 zoneA
sh.addShardTag("shard-A", "zoneA")
sh.addShardTag("shard-B", "zoneB")
// 将 x 范围 1-1000 的数据分配到 zoneA 标签上
sh.addTagRange("shtest.coll", {x: 1}, {x: 1000}, "zoneA")
sh.addTagRange("shtest.coll", {x: 2000}, {x: 5000}, "zoneB")
// 一个tag可以指定到多个shard上,一个shard也可以有多个tag
sh.addShardTag("shard-A", "zoneA")
sh.addShardTag("shard-B", "zoneA")
sh.addShardTag("shard-A", "zoneB")
sh.addShardTag("shard-B", "zoneB")
sh.addTagRange("shtest.coll", {x: 1}, {x: 1000}, "zoneA")
sh.addTagRange("shtest.coll", {x: 2000}, {x: 5000}, "zoneB")
对 shard-A 和 shard-B 添加了标签,在用户不断写入数据时,依然会按照 sharding 策略写入到对应的 shard 中,但是在 Balance 过程中,会按照 shard tag 迁移。
谁来做 Balance?
不同的 Mongodb 版本略有不同,区别如下:
- 3.2 版本是由 Mongos 组件后台的 Balancer 线程完成;
- 3.4 及以后的版本,由 Config Server 组件后台的 Balancer 线程完成,官方文档有误
- 3.2,3.4 版本需要抢锁,抢锁成功的节点才运行 Balancer 线程,3.6 及以后版本直接运行在 config server 的 primary 节点上;
3.2 版本和 3.4 版本中,Balance 的流程是大致相同的,只是执行者不同:
每个 mongos 或者 config server 的节点上都会分别起一个 Balancer 线程,利用 findAndModify 命令去更新 config.lock 中的记录的方式去抢锁(set state=1 if state==0),更新成功即为抢锁成功,拿到锁的节点会继续执行 Balancer 的迁移逻辑,没抢到锁的等待10s后继续抢锁。
Balance 流程
获取chunk分布信息
在开始 Balance 之前,Balancer 会获取 Chunk 的分布信息以及对应的 Shard、Collection、ZoneTag 信息
1、获取Shard分布信息,主要包括shardId、maxSizeMB、currSizeMB、isDraining,shardTags
2、获取开启了 sharding 的 collection 列表
3、获取 shardId 到 Chunk 列表的映射关系
4、获取 RangeTag 信息,这里说的zone的命名,感觉是因为shard tag主要用于给shard打上地域标签,用于给数据按照地域分区
根据TagRange分裂Chunk
如果集合没有设置 tag range,这个步骤不需要做任何事情,设置了 tag Range 的话,会根据 range 进行 chunk 的分裂:
1、检查所有设置过的 TagRange 和 Chunk 是否存在交叉的情况,得到需要分裂的 chunk 和分裂点
2、将分裂点提交给 config server 的 _configsvrCommitChunkSplit Command 完成meta信息的修改
比如存在两个chunk,分别是chunkA(20, 80), chunkB(100, 150), 同时存在tag Range(50, 120),那么会将chunkA和chunkB分别分裂成chunkA1(20,50), chunkA2(50,80), chunkB1(100,120), chunkB2(120,150)
生成待迁移的列表信息
在分裂完Chunk后,会根据Shard和Tag的信息扫描Chunk,生成待迁移的迁移列表信息,迁移信息的结构如下:
struct MigrateInfo {
std::string ns;
// 迁移目标shard
ShardId to;
// 迁移源shard
ShardId from;
// 待迁移的chunk区间信息
BSONObj minKey;
BSONObj maxKey;
};
迁移列表的信息生成包含以下几个步骤:
1、将 draining 状态的 shard 中的 chunk 加入待迁移列表:
- 用户执行过 removeShard 操作后,shard 会处于 draining 状态,直到所有的 chunk 都完成迁移后,shard 才会真正被 remove;
- 选择迁移目标 Shard 时,选择 chunk 数最少的 Shard;
2、将 tag 不一致的 chunk 加入待迁移列表:
- 检查各个 Shard 中的所有 chunk,如果 chunk 的 {minKey, maxKey} 范围所属的 tag range 和当前所在 chunk 的 tag 不符,将 chunk 加入待迁移列表;
- 选择迁移目标 Shard 时,选择 chunk 数最少的 Shard;
- 如果没有 tag,跳过;
3、针对整个分片集群中的 shard tag 做均衡: (totalNumberOfChunksWithTag: tag下的chunk总数,totalNumberOfShardsWithTag:tag下的shard总数)
- 计算每个 shard 上的最佳 chunk 数为:(totalNumberOfChunksWithTag / totalNumberOfShardsWithTag) + (totalNumberOfChunksWithTag % totalNumberOfShardsWithTag ? 1 : 0)
- 如果各个 shard 的chunk数都 <= 最佳chunk数,退出迁移;
- 取chunk数最多的为源shard,chunk数最少的为目的shard创建迁移列表,重新执行这一步,直到找不到匹配的迁移shard;
4、将完成筛选的迁移列表信息写入 config.migrations 中
注意:
(1)在按照tag做均衡时,以上过程的1,2,3步时,参与迁移的源shard和目的shard不会重复被选中。比如第2步将shardA的部分chunk加入到shardA到shardB的迁移列表中后,第3步判断时,不会再选择shardA和shardB参与迁移,两个shard之间只会有1个chunk迁移
(2)在一轮Balance流程中,每个Shard只可能参与一个chunk在迁移
(3)如果chunk超过了chunkSize,如默认64MB,且无法被分裂(collection中的记录shard key非常集中),则会被标记为JumboChunk,除了移除draining shard的场景下会被整体迁移,其他场景不会被选中迁移。
执行迁移
迁移流程是源 shard 主动发起,并由目标 shard 配合完成,源 shard 的几个步骤:
- 准备工作,获取待迁移 collection 的分布式锁,向目标 shard 发送 _recvChunkStart 命令后进入 kCloning 状态,源 shard 不能修改 collection 的 meta 信息;
- 开始 clone,进入 kCloning 状态后,会接收来自目的 shard 的 _migrateClone 命令
- 等待,每隔10s向目标 shard 发送 _recvChunkStatus 命令,检查目标 shard 的迁移状态
- 临界,目标 shard 进入 STEADY 状态后,进入临界状态,临界状态,源 shard 的集合进入只读操作
- 迁移完成,目标 shard 完成了最后的数据修改操作的同步后,并提交 chunk 的新的位置信息到 config server。
- 删除数据。迁移完成后,就会执行删除原数据的操作,在完成迁移之后,会将待删除的 chunk 加入删除队列中,由源 shard 上的 RangeDeleter 完成延迟异步删除;
在迁移过程中,目标 shard 有以下几个状态:
- READY,目标 shard 已经收到了 _recvChunkStart 命令,启动单独的线程处理迁移;
- CLONE,目标 shard 开始拷贝 chunk 数据,并开始向源 shard 发送 _migrateClone 命令同步迁移 chunk 的快照数据;
- CATCHUP,拷贝数据完成,并开始追迁移过程中的oplog;
- STEADY,准备接收源 shard 调用 _recvChunkCommit 命令,会持续拉取最新的修改;
- COMMIT_START,已经接收到 _recvChunkCommit 命令,并拉取源 shard 最新的修改
- DONE,完成迁移
Balance 相关命令
sh.isBalancerRunning() 查看Balance是否运行中
如果balancer进程当前正在运行并且正在迁移块,则返回 true;如果平衡器进程未运行,则返回 false。
使用 sh.getBalancerState() 确定是启用还是禁用了平衡器。
sh.getBalancerState() 查看Balance是否开启
启用balancer时返回true,如果禁用平衡器则返回 False。
这不能反映平衡操作的当前状态,如果Balance运行中使用 sh.disableBalancing() 禁用 Balance,此时 balance 开启状态是 false,但 sh.isBalancerRunning() 为true
sh.enableBalancing() 开启Balance
sh.enableBalancing() 开启 Balance
sh.enableBalancing('db.col') 针对指定collection开启Balance
sh.disableBalancing() 禁用Balance
sh.disableBalancing() 禁用平衡器
sh.disableBalancing('db.col') 针对指定collection关闭Balance。这不会影响同一集群中其他分片集合的chunks平衡。
只能在 mongos 实例上运行sh.disableBalancing()。如果在mongod实例上运行,则sh.disableBalancing()错误。
sh.startBalancer() 启动 Balancer
只能在mongos实例上运行sh.startBalancer()。如果在mongod实例上运行,则sh.startBalancer()错误。
sh.stopBalancer() 停止Balancer
如果当前有Balance任务在跑,会等当前的任务完成后停止
设置balancer开启的时间窗口
db.settings.update(
{ _id: "balancer" },
{ $set: { activeWindow : { start : "<start-time>", stop : "<stop-time>" } } },
{ upsert: true }
)
Balance 的配置保存在 config.setting 中:
{ "_id" : "chunksize", "value" : NumberLong(64) }
{ "_id" : "balancer", "stopped" : false, "mode": "full"}
mongos
MongoDB 认证
MongoDB 角色
MongoDB 有一些内置的角色,如下:
- 数据库用户角色:read、readWrite
- 数据库管理角色:dbAdmin、dbOwner、userAdmin
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色:backup、restore
- 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 超级用户角色:root
- 内部角色:__system
权限:
- read:允许用户读取指定数据库。
- readWrite:允许用户读写指定数据库。
- dbAdmin:允许用户在指定数据库中执行管理函数,例如索引创建与删除,查看统计或访问 system.profile。
- userAdmin:允许用户向 system.users 集合写入,可以在指定数据库里创建、删除和管理用户。
- clusterAdmin:只能在 admin 数据库中创建此角色用户,赋予用户所有分片和复制集相关函数的管理权限。
- readAnyDatabase:只能在 admin 数据库中创建此角色用户,赋予用户所有数据库的读权限。
- readWriteAnyDatabase:只能在 admin 数据库中创建此角色用户,赋予用户所有数据库的读写权限。
- userAdminAnyDatabase:只能在 admin 数据库中创建此角色用户,赋予用户所有数据库的 userAdmin 权限。
- dbAdminAnyDatabase:只能在 admin 数据库中创建此角色用户,赋予用户所有数据库的 dbAdmin 权限。
- root:只能在 admin 数据库中创建此角色用户,超级账号,超级所有权限。其实 dbOwner 、userAdmin、userAdminAnyDatabase 角色间接或直接提供了系统超级用户的权限。
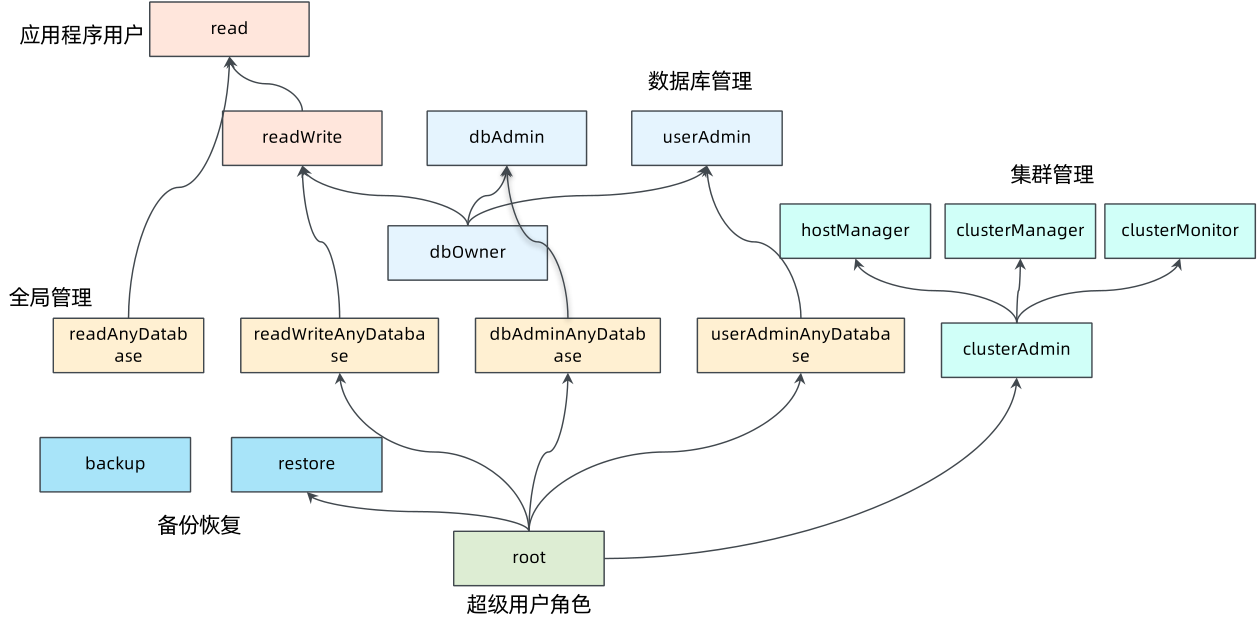
Mongo内置角色
MongoDB 开启认证
Mongodb 支持 SCRAM 认证,该认证通过用户名、密码认证,基于用户角色进行访问控制,添加账号步骤如下。
创建管理员账户
1、以无访问认证方式启动 mongodb,未开启认证环境下,登录 mongo
mongo localhost:27017
2、查看 mongo 版本:
> db.version();
3.2.16
3、查看数据库:
> show dbs;
local 0.000GB
mytest-db 0.459GB
4、切换到 admin 数据库(注意现在还没有 admin 数据库)
3.0 版本后没有 admin 数据库,但我们可以手动 use 一个。注:use 命令在切换数据库时,如果切换到一个不存在的数据库,MongodDB 会自动创建该数据库
其实 use 后 show dbs 也无法立即看到 admin 数据库,重新登录或者真正有数据插入时才会创建 admin 库
5、创建管理员账户
配置访问控制的第一步是创建用户管理员账户。用户管理员应只有创建用户账户的权限,而不能管理数据库或执行其他管理任务。这确保数据库管理和用户账户管理之间有清晰的界限。
如果 mongo 版本是 3.0 以前,则用 db.addUser 创建用户
db.createUser({
user: "adminuser",
pwd: "adminpd",
roles: [{role: "userAdminAnyDatabase", db: "admin"}]
});
Successfully added user: {
"user" : "adminuser",
"roles" : [
{
"role" : "userAdminAnyDatabase",
"db" : "admin"
}
]
}
角色说明: userAdminAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的 userAdmin 权限
创建普通账户
1、切换到 mytest-db 数据库
> use mytest-db;
switched to db mytest-db
2、创建普通账户
db.createUser({
user:"dbuser",
pwd: "dbuserpd",
roles: [{ role: "readWrite", db: "mytest-db"}]
});
Successfully added user: {
"user" : "dbuser",
"roles" : [
{
"role" : "readWrite",
"db" : "mytest-db"
}
]
}
重启Mongo开启认证
1、编辑 mongo 配置文件,开启认证
编辑 mongodb-3.2.16/conf/mongo_conf.conf 将 auth 设为 true
port=27017
dbpath=/data1/mongo_data/
logpath=logs/mongo.log
pidfilepath=pid/config.pid
fork=true
logappend=true
auth=true
2、重新启动 mongo,开启认证
# ./bin/mongod -f conf/mongo_conf.conf
about to fork child process, waiting until server is ready for connections.
forked process: 1474
child process started successfully, parent exiting
登录Mongo后通过 db.auth() 认证
1、重新登录 mongo
mongo localhost:27019
登录后,如果不先认证,执行命令会报错:
> show dbs;
2021-12-01T17:38:59.195+0800 E QUERY [thread1] Error: listDatabases failed:{
"ok" : 0,
"errmsg" : "not authorized on admin to execute command { listDatabases: 1.0 }",
"code" : 13
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
Mongo.prototype.getDBs@src/mongo/shell/mongo.js:62:1
shellHelper.show@src/mongo/shell/utils.js:769:19
shellHelper@src/mongo/shell/utils.js:659:15
@(shellhelp2):1:1
切换到对应数据库后,用 db.auth('用户名', '密码') 认证即可:
> use admin;
switched to db admin
> db.auth('adminuser','adminpd')
1
> show dbs;
admin 0.000GB
local 0.000GB
mytest-db 0.459GB
> use mytest-db;
switched to db mytest-db
> db.auth('dbuser','dbuserpd')
1
> show collections;
fs.chunks
fs.files
带认证信息登录mongo
或者可以直接登录填入账号密码
mongo localhost:27019 -u adminuser -p adminpd --authenticationDatabase admin
mongo localhost:27019 -u dbuser -p dbuserpd --authenticationDatabase mytest-db
未开启认证的mongo带密码无法登录
未开启认证的 mongo 带密码无法登录,所以服务连接带上认证参数后,就不能连接无密码的 mongo 了。
# mongo localhost:27019 -u dbuser -p dbuserpd --authenticationDatabase admin
MongoDB shell version v3.6.14
connecting to: mongodb://localhost:8017/test?authSource=admin&gssapiServiceName=mongodb
2022-03-16T13:30:02.938+0000 E QUERY [thread1] Error: Authentication failed. :
connect@src/mongo/shell/mongo.js:263:13
@(connect):1:6
exception: connect failed
Mongo Profiler 慢查询记录
Database Profiler
https://www.mongodb.com/docs/manual/tutorial/manage-the-database-profiler/
开启 Profiler 记录
Profiling 级别:
- 0 关闭,不收集任何数据。
- 1 收集慢查询数据,默认记录超 100 毫秒的操作。
- 2 收集所有数据
1、修改 mongo.conf 配置文件开启 Mongo Profiler 记录
#开启慢查询,200毫秒的记录
profile = 1
slowms = 200
2、通过命令开启(重启后失效)
db.getProfilingStatus() 查看 Profiling 状态,was 是级别,slowms 是慢查询阈值,默认是 0 级 100 毫秒
db.setProfilingLevel(1,1000); 设置级别和慢查询时间,经测试好像 Profiler 级别是各个 DB 独立的,但 slowms 时间阈值是各个 DB 共享的
mongodb-shard-0:PRIMARY> db.getProfilingStatus();
{
"was" : 0,
"slowms" : 100,
"sampleRate" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("7fffffff0000000000000003")
},
"lastCommittedOpTime" : Timestamp(1651718015, 1),
"$configServerState" : {
"opTime" : {
"ts" : Timestamp(1651718009, 2),
"t" : NumberLong(1017)
}
},
"$clusterTime" : {
"clusterTime" : Timestamp(1651718015, 1),
"signature" : {
"hash" : BinData(0,"ACzOHeOEXiTez+Mpo/bQp7q6rx8="),
"keyId" : NumberLong("7075910314662821911")
}
},
"operationTime" : Timestamp(1651718015, 1)
}
mongodb-shard-0:PRIMARY> db.setProfilingLevel(1,1000);
{
"was" : 0,
"slowms" : 100,
"sampleRate" : 1,
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("7fffffff0000000000000003")
},
"lastCommittedOpTime" : Timestamp(1651718025, 1),
"$configServerState" : {
"opTime" : {
"ts" : Timestamp(1651718016, 2),
"t" : NumberLong(1017)
}
},
"$clusterTime" : {
"clusterTime" : Timestamp(1651718025, 1),
"signature" : {
"hash" : BinData(0,"4n6mFR5/lZKTb81r5hvbEwP7R0s="),
"keyId" : NumberLong("7075910314662821911")
}
},
"operationTime" : Timestamp(1651718025, 1)
}
关闭 Profiler 记录:
db.setProfilingLevel(0)
查看慢查询日志
查询全部慢日志 db.system.profile.find().pretty();
或查询耗时 ts 最大的 10 条记录 db.system.profile.find().limit(10).sort( { ts : -1 } ).pretty()
Intel/M1 Mac Brew 安装 MongoDB Community
MongoDB 已经宣布不再开源,从2019年9月2日开始 HomeBrew 也从核心仓库当中移除了 mongodb 模块
MongoDB 官方提供了一个单独的 HomeBrew 的社区版本安装 Tap
https://github.com/mongodb/homebrew-brew
1、brew tap 安装 mongodb/brew 源
brew tap mongodb/brew
2、安装最新 mongodb 社区版 brew install mongodb-community
或者指定版本安装 brew install mongodb-community@4.4
Intel Mac 安装目录 /usr/local/Cellar/mongodb-community/4.4.5
M1 Mac 安装目录 /opt/homebrew/Cellar/mongodb-community/5.0.6
M1 Mac 安装目录 /opt/homebrew/Cellar/mongodb-community/6.0.1
使用 brew services 启动并添加开机启动:
brew services start mongodb-community
前台启动
Intel 版 Mongo mongod --config /usr/local/etc/mongod.conf
M1 版 Mongo mongod --config /opt/homebrew/etc/mongod.conf
登录 Mongo
5.0 及之前,安装 Mongo 时会自动安装 mongo 命令行,启动 mongodb-community 服务后直接运行 mongo 命令即可登录 localhost:27017
6.0 开始,官方用 mongosh 代替 mongo 命令行,安装 Mongo 6.0 后也不再有 mongo 命令,而是会安装 /opt/homebrew/Cellar/mongosh/1.6.0,启动 mongodb-community 服务后直接运行 mongosh 命令即可登录 localhost:27017
启动/停止 MongoDB
启动 MongoDB
1、启动
mongod --dbpath /home/user1/mongodb/data --logpath /home/user1/mongodb/log/logs --fork
mongo服务启动必须要指定文件存放的目录dbpath,--fork以守护进程运行,如果带—fork参数则必须要指定—logpath即日志存放的位置
2、指定配置文件启动
mongod -f conf/mongo_conf.conf
mongod 和 mongo 的区别
mongod 是 MongoDB 的服务端后台进程,mongo 是客户端。
停止 MongoDB
1、查看进程并 kill
ps aux|grep mongod
kill -9 pid
2、在客户端中使用 shutdown 命令
> use admin
switched to db admin
> db.auth('admin','123456')
> db.shutdownServer()
mongo 连接
mongo 连接本地27017端口(5.0及之前)
mongo 连接本机 27017 端口的 mongo 等于 mongo localhost:27017 或 mongo 127.0.0.1:27017
mongosh 连接本地27017端口(6.0及之后)
从 MongoDB 6.0 开始,使用 mongosh 命令行代替 mongo 命令行
https://www.mongodb.com/docs/manual/release-notes/6.0-compatibility/
mongosh
Current Mongosh Log ID: 637ddc86ac2620380ae3baeb
Connecting to: mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.6.0
Using MongoDB: 6.0.1
Using Mongosh: 1.6.0
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
mongo --host host --port port 连接指定host上的mongo
如果忽略 --host 默认连接 127.0.0.1, 如果忽略 --port 默认连接 27017
mongo --host host 连接指定 host 上 27017 端口的 mongo
mongo --port 27017 连接本地 27017 端口的 mongo
mongo host:port 连接指定host端口
mongo 192.168.1.100:27017 指定 host 和端口连接 mongo
# mongo localhost:27019
MongoDB shell version: 3.2.16
connecting to: localhost:27019/test
mongo host:port/db 指定host端口数据库连接
mongo 192.168.1.100:27017/test 指定host、端口、数据库名连接
mongo host:port/db -u u -p p 指定账号密码连接
mongo 192.168.1.200:27017/test -u user -p password 指定host、端口、用户名、密码、数据库名连接
mongo 192.168.1.200:27017/test -uuser -ppassword
mongostat
mongostat 是 mongodb 自带的状态检测工具,在命令行下使用,会间隔固定时间(默认1s)获取 mongodb 的当前运行状态,并输出。
MongoDB 数据导入导出
mongodb 备份、还原、导入、导出简单操作
https://segmentfault.com/a/1190000006236494
mongodump 导出数据库
MongoDB Database Tools - mongodump
https://www.mongodb.com/docs/database-tools/mongodump/
mongodump 可从 mongos 或 mongod 导出数据
mongodump -h ip --port 端口 -u 用户名 -p 密码 -d 数据库 -o 文件存在路径
--authenticationDatabase admin 如果开启了认证,必须指定认证数据库,否则报错:
2022-06-12T03:07:41.845+0000 could not connect to server: connection() error occured during connection handshake: auth error: sasl conversation error: unable to authenticate using mechanism "SCRAM-SHA-1": (AuthenticationFailed) Authentication failed.
注意: mongodump 和 mongoexport 导出的数据库、表不包含索引,使用 mongorestore/mongoimport 导入后需要重建索引
例如,导出 users 库
$ mongodump -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d users -o /opt/bitnami/mongodb/
2022-06-14T01:59:48.283+0000 writing users.user to /opt/bitnami/mongodb/users/user.bson
2022-06-14T01:59:51.248+0000 [#.......................] users.user 7802/111808 (7.0%)
2022-06-14T01:59:54.248+0000 [#######.................] users.user 34752/111808 (31.1%)
2022-06-14T01:59:56.410+0000 [########################] users.user 111808/111808 (100.0%)
2022-06-14T01:59:56.410+0000 done dumping users.user (111808 documents)
会在输出目录中生成 users 目录,里面有各个 collection 的数据和元数据信息
464M user.bson
4.0K user.metadata.json
注意如果最后的输出目录提示无写权限,改为一个有写权限的目录
2022-06-14T01:57:44.964+0000 Failed: error dumping metadata: error creating directory for metadata file /users: mkdir /users: permission denied
mongorestore 导入数据库
MongoDB Database Tools - mongorestore
https://www.mongodb.com/docs/database-tools/mongorestore/
mongorestore -h ip --port 端口 -u 用户名 -p 密码 -d 数据库 文件存在路径
--authenticationDatabase admin 如果开启了认证,必须指定认证数据库
例如,导入 users 库
mongorestore -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d users /opt/bitnami/mongodb/users
注意:
导入时,目标库中不存在的 collection 会新建,已有同名 collection 会在其中插入文档,如果相同 id 的文档也存在会报错,但不影响其他collection和文档导入:
2023-05-18T14:57:42.357+0800 continuing through error: E11000 duplicate key error collection: user.20230515.chunks index: _id_ dup key: { _id: ObjectId('64622323d930381dae2e13b0') }
mongoexport 导出collection数据
MongoDB Database Tools - mongoexport
https://www.mongodb.com/docs/database-tools/mongoexport/
mongoexport -h ip --port 端口 -u 用户名 -p 密码 -d 数据库 -c 表名 -o 文件名
--authenticationDatabase admin 如果开启了认证,必须指定认证数据库
此外还支持下面的高级选项:
-f 指定导出字段,以字号分割,-f name,email,age 表示导出 name,email,age 这三个字段
-q 可以根查询条件导出, -q '{ "_id" : "10001" }' 导出 uid 为 100 的数据
--csv 表示导出的文件格式为 csv 的
例如分别导出 chunks 和 files 表
mongoexport -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d image-storage -c img_collection_20220623.chunks -o /opt/bitnami/mongodb/face-chunks.dat
mongoexport -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d image-storage -c img_collection_20220623.files -o /opt/bitnami/mongodb/face-files.dat
大collection导出有进度
2022-06-12T03:16:50.654+0000 connected to: mongodb://localhost:27017/
2022-06-12T03:16:51.655+0000 [........................] image-storage.img_collection_20220623.chunks 0/13674 (0.0%)
2022-06-12T03:17:01.654+0000 [##############..........] image-storage.img_collection_20220623.chunks 8000/13674 (58.5%)
2022-06-12T03:17:08.139+0000 [########################] image-storage.img_collection_20220623.chunks 13674/13674 (100.0%)
2022-06-12T03:17:08.139+0000 exported 13674 records
mongoimport 导入collection数据
MongoDB Database Tools - mongoimport
https://www.mongodb.com/docs/database-tools/mongoimport/
mongoimport -h ip --port 端口 -u 用户名 -p 密码 -d 数据库 -c 表名 --upsert --drop 文件名
--authenticationDatabase admin 如果开启了认证,必须指定认证数据库
--upsert 插入或者更新现有数据
mongoimport -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d image-storage -c img_collection_20220623.files --upsert /opt/bitnami/mongodb/face-files.dat
mongoimport -h localhost --port 27017 -u root -p passwd --authenticationDatabase admin -d image-storage -c img_collection_20220623.chunks --upsert /opt/bitnami/mongodb/face-chunks.dat
数据量大时导入有进度
2022-06-12T04:40:12.071+0000 connected to: mongodb://localhost:27017/
2022-06-12T04:40:15.072+0000 [#.......................] image-storage.img_collection_20220623.chunks 188MB/2.38GB (7.7%)
2022-06-12T04:42:27.072+0000 [###############.........] image-storage.img_collection_20220623.chunks 1.58GB/2.38GB (66.2%)
2022-06-12T04:43:06.302+0000 [########################] image-storage.img_collection_20220623.chunks 2.38GB/2.38GB (100.0%)
2022-06-12T04:43:06.302+0000 13674 document(s) imported successfully. 0 document(s) failed to import.
导出的数据库和collection会丢失原有索引和分片信息
导入的 collection 会丢失原有索引,需要手动创建
1、查看原 mongo collection 中的索引
mongos> db.img_collection_20220623.files.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"filename" : 1,
"uploadDate" : 1
},
"name" : "filename_1_uploadDate_1"
}
]
mongos> db.img_collection_20220623.chunks.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"files_id" : "hashed"
},
"name" : "files_id_hashed"
},
{
"v" : 2,
"unique" : true,
"key" : {
"files_id" : 1,
"n" : 1
},
"name" : "files_id_1_n_1"
}
]
2、在导入后的 mongo collection 上创建索引
db.img_collection_20220623.files.createIndex({"filename" : 1, "uploadDate" : 1});
db.img_collection_20220623.chunks.createIndex({"files_id" : "hashed"});
db.img_collection_20220623.chunks.createIndex({"files_id" : 1, "n" : 1});
3、如果原 collection 有按某个索引分片,手动创建分片
比如按 files_id 分片
sh.shardCollection("image-storage.img_collection_20220623.chunks", {"files_id": "hashed"});
mongos> sh.shardCollection("image-storage.img_collection_20220623.chunks", {"files_id": "hashed"});
{
"collectionsharded" : "image-storage.img_collection_20220623.chunks",
"collectionUUID" : UUID("8202afb5-f27a-490a-8012-a781479836a1"),
"ok" : 1,
"operationTime" : Timestamp(1655024627, 125),
"$clusterTime" : {
"clusterTime" : Timestamp(1655024627, 125),
"signature" : {
"hash" : BinData(0,"L+r/xU83i+Ai/vUkYg17dhw8bcQ="),
"keyId" : NumberLong("7106747423933857815")
}
}
}
MongoDB 查看版本号
mongo --version(未连接时)
未登录 mongo 时 mongo --version 或 mongod --version
mongo --version
MongoDB shell version v4.4.0
Build Info: {
"version": "4.4.0",
"gitVersion": "563487e100c4215e2dce98d0af2a6a5a2d67c5cf",
"modules": [],
"allocator": "system",
"environment": {
"distarch": "x86_64",
"target_arch": "x86_64"
}
}
db.version() 已连接时
已登录 mongo 后:
> db.version();
4.4.0
mongo shell(4.x及之前) 和 mongosh(5.0)
Legacy mongo Shell
https://www.mongodb.com/docs/manual/reference/mongo/
MongoDB 5.0 开始用 mongosh 代替 mongo shell,包括如下改进:
- 语法高亮
- 命令行历史记录
- 日志记录
新的 mongosh 可以向前兼容多数 mongo shell 命令,语法保持不变。
Database Methods 数据库命令
https://docs.mongodb.com/manual/reference/method/js-database/
查看所有账号信息
> use admin
switched to db admin
> db.auth('admin','123456')
1
> db.system.users.find().pretty()
db.adminCommand() 执行admin数据库命令
https://docs.mongodb.com/manual/reference/method/db.adminCommand/#mongodb-method-db.adminCommand
db.runCommand() 在当前数据库执行命令
https://www.mongodb.com/docs/manual/reference/method/db.runCommand/
https://www.mongodb.com/docs/manual/reference/command/
数据库命令
renameCollection-迁移collection
https://www.mongodb.com/docs/manual/reference/command/renameCollection/
db1 中的 test1 改名为 test2
db.adminCommand({renameCollection: "db1.test1", to: "db1.test2"})
还可以跨 db 迁移 collection, 比如将 db1.test1 迁移到 db2.test2
db.adminCommand({renameCollection: "db1.test1", to: "db2.test2"})
此时会将 db1.test1 的数据拷贝到 db2.test2, 如果 db2 中已有 test2 集合会将其 drop 掉。
renameCollection
https://docs.mongodb.com/manual/reference/command/renameCollection/
getShardMap 查询分片信息
https://www.mongodb.com/docs/manual/reference/command/getShardMap/
返回分片集群信息,必须在 admin 数据库上执行此命令
- shard 和 config server 的副本集信息
- 各个分片的连接url信息
mongos> db.adminCommand("getShardMap").map;
{
"config" : "mongodb-configsvr/mongodb-configsvr-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-configsvr-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-configsvr-2.mongodb-headless.default.svc.cluster.local:27017",
"mongodb-shard-0" : "mongodb-shard-0/mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-2.mongodb-headless.default.svc.cluster.local:27017",
"mongodb-shard-1" : "mongodb-shard-1/mongodb-shard1-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard1-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard1-data-2.mongodb-headless.default.svc.cluster.local:27017",
"mongodb-shard-2" : "mongodb-shard-2/mongodb-shard2-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard2-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard2-data-2.mongodb-headless.default.svc.cluster.local:27017"
}
replSetGetStatus 查询副本状态
https://www.mongodb.com/docs/manual/reference/command/replSetGetStatus/
返回副本集状态,members 中能看到每个副本的角色是 primary 还是 secondary
必须在 config server 或 data 节点执行此命令,必须在 admin 数据库上执行此命令
mongodb-shard-0:PRIMARY> db.adminCommand({ replSetGetStatus: 1 })
{
"set" : "mongodb-shard-0",
"date" : ISODate("2023-10-18T11:32:04.818Z"),
"myState" : 1,
"term" : NumberLong(12),
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"votingMembersCount" : 3,
"writableVotingMembersCount" : 3,
"lastStableRecoveryTimestamp" : Timestamp(1697628710, 6),
"members" : [
{
"_id" : 0,
"name" : "mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 204900,
"syncSourceHost" : "",
"syncSourceId" : -1,
"self" : true
},
{
"_id" : 1,
"name" : "mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 204894,
"syncSourceHost" : "mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017"
},
{
"_id" : 2,
"name" : "mongodb-shard0-data-2.mongodb-headless.default.svc.cluster.local:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 204824,
"syncSourceHost" : "mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017"
}
],
"ok" : 1
}
compact
https://www.mongodb.com/docs/manual/reference/command/compact/
不能在 mongos 上执行 compact 命令。
show dbs 查看数据库及大小
show dbs 或 show databases 查看数据库及大小
mongos> show dbs;
admin 0.000GB
config 0.006GB
msg 3.123GB
storage 94.942GB
use db 切换/创建数据库
mongo 中创建数据库采用的也是 use 命令,如果 use 后面跟的数据库名不存在,那么 mongo 将会新建该数据库。
不过,实际上只执行 use 命令后,mongo 是不会新建该数据库的,直到你像该数据库中插入了数据。
db 查看当前数据库
show collections 查看当前库中的集合列表
show tables 查看当前库中的集合列表
db.getCollectionNames() 返回集合列表
等于 show collections 命令结果
https://www.mongodb.com/docs/manual/reference/method/db.getCollectionNames/
db.stats() 查看使用量统计
https://www.mongodb.com/docs/manual/reference/method/db.stats/
先 use 切换数据库,然后执行 db.stats() 查看数据库使用量
collections:当前collection个数
objects:当前数据库所有collection数据条数
dataSize:所有数据的总大小,单位 bytes
storageSize:所有数据占的磁盘大小
indexes:索引数
indexSize:索引大小
scaleFactor:数据量单位缩放因子,默认为1,以字节返回大小的数据。要以KB 单位,指定scale值1024
mongos> db.stats();
{
"raw" : {
"mongodb-shard-0/mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-arbiter-0.mongodb-headless.default.svc.cluster.local:27017" : {
"db" : "storage",
"collections" : 46,
"views" : 0,
"objects" : 747853,
"avgObjSize" : 135104.86402809108,
"dataSize" : 101038577878,
"storageSize" : 101909536768,
"indexes" : 114,
"indexSize" : 53190656,
"totalSize" : 101962727424,
"scaleFactor" : 1,
"fsUsedSize" : 429770670080,
"fsTotalSize" : 984367513600,
"ok" : 1
}
},
"objects" : 747853,
"avgObjSize" : 135104,
"dataSize" : 101038577878,
"storageSize" : 101909536768,
"totalSize" : 101962727424,
"indexes" : 114,
"indexSize" : 53190656,
"scaleFactor" : 1,
"fileSize" : 0,
"ok" : 1,
"operationTime" : Timestamp(1655292494, 20),
"$clusterTime" : {
"clusterTime" : Timestamp(1655292496, 1),
"signature" : {
"hash" : BinData(0,"2NmKAmyTrRr94GZVMah2cPIHsq0="),
"keyId" : NumberLong("7105939909952667671")
}
}
}
db.dropDatabase() 删除db
> db.dropDatabase()
{ "dropped" : "test", "ok" : 1 }
db.getCollection('col') 返回collection
返回 collection 对象实例,或者说一个功能上等于 db.col. 语法的实例,后续可执行任何 collection 操作。
例如 db.getCollection("20220304.chunks").dataSize()
SyntaxError: unexpected token: numeric literal
名字不是合法 JavaScript 标识符的 collection 执行命令会报错,比如这种数字开头的 collection 名
mongos> db.20220304.chunks.totalSize();
uncaught exception: SyntaxError: unexpected token: numeric literal :
@(shell):1:2
解决:
使用 db.getCollection('20220304.chunks') 获取 collection 对象之后再操作
mongos> db.getCollection('20220304.chunks').totalSize();
733184
Numeric collection name
https://jira.mongodb.org/browse/SERVER-29953
db.createCollection(name, options) 创建集合
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
capped 布尔(可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。
autoIndexId 布尔 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。
size 数值 (可选)为固定集合指定一个最大值,即字节数。如果 capped 为 true,也需要指定该字段。
max 数值(可选)指定固定集合中包含文档的最大数量。
注意:MongoDB 中不需要单独创建集合。当插入文档到某个集合时,MongoDB 会自动创建不存在的集合。
db.currentOp() 查看正在执行的连接
https://www.mongodb.com/docs/manual/reference/method/db.currentOp/
查看当前正在进行的 mongo 操作,类似 MySQL 的 show processlist
secs_running 操作持续时间(秒),等于当前时间减去操作开始时间
microsecs_running 操作持续时间(微秒)
active 操作是否开启,空连接或内部空闲线程是非活跃的
op 操作类型,比如 insert, update, query, remove
ns 操作的db和collection名,格式 <database>.<collection>
查询执行时间超过1秒的慢查询操作
db.currentOp({ "secs_running": { "$gt": 1 }, "active": true })
Collection Methods 集合命令
Collection Methods
https://docs.mongodb.com/manual/reference/method/js-collection/
db.col.drop() 删除集合
批量删除collection脚本
比如删除 202206 开头的 collection
var colls = db.getCollectionNames()
for(var i in colls){
if (colls[i].startsWith('202206')) {
db.getCollection(colls[i]).drop()
print(colls[i])
}
}
db.col.renameCollection() 集合重命名
修改 msg 集合名为 msg_bak_531
> db.msg.renameCollection("msg_bak_531");
{ "ok" : 1 }
db.col.insert() 插入文档
如果集合 col 在该数据库中不存在, MongoDB 会自动创建该集合并插入文档。
db.test.insert({ item: "card", qty: 15 });
db.col.save() 插入或更新文档
save() 如果 _id 主键存在则更新数据,如果不存在就插入数据。
该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
db.col.insertMany() 批量插入数据
db.col.find() 文档查询
> db.col.find();
{ "_id" : ObjectId("605852c8268f6ff446491871"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
{ "_id" : ObjectId("6058672a268f6ff446491872"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
条件查询
查询 success 是 false 的文档
db.col.find({"success":false});
查询name是xiaoming,createdDate 大于xx的数据
db.col.find({"name": "xiaoming", "createdDate": {"$gt": ISODate("2023-12-12T10:00:49.411Z")}});
json嵌套查询
查询 msg 表中 code=code37,content.userName 等于 xiaoming 的数据
db.msg.find({
"code": "code37",
"content.userName": {
$eq:"xiaoming"
}
}).limit(1);
sort() 排序
1 升序,-1 降序
查询时间倒序排序第一个成功的:
db.col.find({"success":true}).sort({"createdDate":-1}).limit(1);
limit() 指定返回结果数
> db.col.find().limit(2);
skip() 指定偏移量
count() 计数
count 计数
db.col.find({"success":false}).count();
count("a":null) 查询字段为空或不存在的文档
> db.col.find({"type":null}).limit(2);
db.col.count() 查看集合中的文档数
https://www.mongodb.com/docs/manual/reference/method/db.collection.count/
count 计数
db.col.count(query) 等于 db.col.find(query).count()
例如,统计 success 是 true 的文档个数:
db.col.count({"success":false});
无查询条件时是非精确统计
无 query 查询语句时,count() 执行的是非精确统计,直接查询 collection 的元数据返回。
在分片集群上,无 query 查询语句时,count() 会统计到孤儿文档,导致返回数据不准确。
db.col.dataSize() 集合的数据大小(bytes)
https://www.mongodb.com/docs/manual/reference/method/db.collection.dataSize/
返回为 collection 分配的空间大小,包括未使用的空间,是数据压缩前的大小,单位 bytes
mongos> db.20220615.chunks.dataSize();
2026475991
db.col.storageSize() 集合的存储大小(bytes)
https://www.mongodb.com/docs/manual/reference/method/db.collection.storageSize/
如果压缩了集合数据,则存储大小反映了压缩后的大小,可能小于 dataSize(),单位 bytes
或者 db.getCollection("aaa").storageSize()
例1,查看集合 20220615.chunks 的大小
mongos> db.20220615.chunks.storageSize();
2052100096
例2,数字开头的 collection 名需要使用 getCollection("") 方法,否则报语法错误
mongos> db.'20221116.chunks'.storageSize()
uncaught exception: SyntaxError: missing name after . operator :
@(shell):1:3
mongos> db.getCollection("20221116.chunks").storageSize();
286720
Numeric collection name
https://jira.mongodb.org/browse/SERVER-29953
db.col.totalIndexSize() 集合的索引大小(bytes)
https://www.mongodb.com/docs/manual/reference/method/db.collection.totalIndexSize/
集合的索引大小
mongos> db.20220615.chunks.totalIndexSize() ;
933888
db.col.totalSize() 数据+索引大小(bytes)
https://www.mongodb.com/docs/manual/reference/method/db.collection.totalSize/
数据 + 索引大小,单位 bytes,等于 storageSize() + totalIndexSize()
mongos> db.20220615.chunks.totalSize();
2053033984
db.col.stats() 集合的统计信息
https://www.mongodb.com/docs/manual/reference/method/db.collection.stats/
db.col.deleteMany() 条件删除
删除 type 字段为 null 或不存在的文档
> db.col.deleteMany({"type":null});
{ "acknowledged" : true, "deletedCount" : 6896 }
db.col.remove() 条件删除
删除 success 是 false 的文档
db.col.remove({"success": false});
db.col.aggregate() 聚合查询
db.collection.aggregate()
https://docs.mongodb.com/manual/reference/method/db.collection.aggregate/
文档重复查询及删除
查询 msgcode 重复的文档
db.col.aggregate([
{ $group: { _id : '$msgCode', count: { $sum : 1 } } },
{ $match: { count: { $gt : 1} } }
])
查询 msgcode 重复的文档并删除
db.col.aggregate([
{ $group: {_id : '$msgCode', count: {$sum : 1}, dups:{$addToSet:'$_id'}}},
{ $match: {count: {$gt:1} }
} ]).forEach(function(it) {
it.dups.shift();
db.msg_send.remove({_id: {$in: it.dups}});
});
解释:
$group 中是聚合条件,根据 msgCode 字段聚合。
count 统计重复出现的次数, $match 过滤出现重复的数据
$addToSet 将聚合的数据id放入到 dups 数组中方便后面使用
forEach 对查询结果进行遍历
shift() 作用是剔除队列中第一条id,避免删掉所有的数据
删除重复msgcode
https://segmentfault.com/a/1190000020056997
Replication Methods 复制集命令
https://docs.mongodb.com/manual/reference/method/js-replication/
rs.status() 查看复制集状态
https://docs.mongodb.com/manual/reference/method/rs.status/#mongodb-method-rs.status
> rs.status();
{
"ok" : 0,
"errmsg" : "not running with --replSet",
"code" : 76,
"codeName" : "NoReplicationEnabled"
}
rs.printReplicationInfo()
打印副本集成员的 oplog 的格式化报告。显示的报告会格式化 db.getReplicationInfo() 返回的数据。
Sharding Methods 分片命令
https://docs.mongodb.com/manual/reference/method/js-sharding/
sh.status() 查看分片集群状态
https://docs.mongodb.com/manual/reference/method/sh.status/#mongodb-method-sh.status
打印 sharding 配置和 chunks 信息,需要在 mongos 上执行。
在非 mongos 上执行时提示:
mongos> sh.status();
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("6520c2895f2a518b32c91c49")
}
shards:
{ "_id" : "mongodb-shard-0", "host" : "mongodb-shard-0/mongodb-shard0-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard0-data-2.mongodb-headless.default.svc.cluster.local:27017", "state" : 1 }
{ "_id" : "mongodb-shard-1", "host" : "mongodb-shard-1/mongodb-shard1-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard1-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard1-data-2.mongodb-headless.default.svc.cluster.local:27017", "state" : 1 }
{ "_id" : "mongodb-shard-2", "host" : "mongodb-shard-2/mongodb-shard2-data-0.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard2-data-1.mongodb-headless.default.svc.cluster.local:27017,mongodb-shard2-data-2.mongodb-headless.default.svc.cluster.local:27017", "state" : 1 }
active mongoses:
"4.4.17-r4" : 2
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
377 : Success
138 : Failed with error 'aborted', from mongodb-shard-0 to mongodb-shard-2
235 : Failed with error 'aborted', from mongodb-shard-1 to mongodb-shard-2
184 : Failed with error 'aborted', from mongodb-shard-2 to mongodb-shard-1
259 : Failed with error 'aborted', from mongodb-shard-2 to mongodb-shard-0
159 : Failed with error 'aborted', from mongodb-shard-0 to mongodb-shard-1
162 : Failed with error 'aborted', from mongodb-shard-1 to mongodb-shard-0
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
mongodb-shard-0 342
mongodb-shard-1 341
mongodb-shard-2 341
too many chunks to print, use verbose if you want to force print
{ "_id" : "image-storage", "primary" : "mongodb-shard-0", "partitioned" : true, "version" : { "uuid" : UUID("de0830a3-0de5-4bdd-8edb-8f0830f3efd3"), "lastMod" : 1 } }
image-storage.20230927.chunks
shard key: { "files_id" : "hashed" }
unique: false
balancing: true
chunks:
mongodb-shard-0 2
mongodb-shard-1 2
mongodb-shard-2 2
{ "files_id" : { "$minKey" : 1 } } -->> { "files_id" : NumberLong("-6148914691236517204") } on : mongodb-shard-0 Timestamp(1, 0)
{ "files_id" : NumberLong("-6148914691236517204") } -->> { "files_id" : NumberLong("-3074457345618258602") } on : mongodb-shard-0 Timestamp(1, 1)
{ "files_id" : NumberLong("-3074457345618258602") } -->> { "files_id" : NumberLong(0) } on : mongodb-shard-1 Timestamp(1, 2)
{ "files_id" : NumberLong(0) } -->> { "files_id" : NumberLong("3074457345618258602") } on : mongodb-shard-1 Timestamp(1, 3)
{ "files_id" : NumberLong("3074457345618258602") } -->> { "files_id" : NumberLong("6148914691236517204") } on : mongodb-shard-2 Timestamp(1, 4)
{ "files_id" : NumberLong("6148914691236517204") } -->> { "files_id" : { "$maxKey" : 1 } } on : mongodb-shard-2 Timestamp(1, 5)
MongoDB 时间少8小时
现象:
通过 Spring Boot Data MongoDB 保存到 mongo 中的时间,在 mongo shell db.col.find(); 查看时少 8 个小时,但 Java 代码中保存日志和查询出来的时间都是正常的。
原因:
MongoDB 自带的 Date 是 UTC/GMT 时间,中国是东八区(UTC+8)。
MongoDB 中的 Date 类型数据只保存绝对时间值,不保存时区信息,因此“显示的时间”取决于 MongoDB 的客户端设置。
解决:
MongoDB 服务端只能以 UTC/GMT 存储时间,不支持时区设置,只能在各个客户端修改时区。
如果使用可视化工具 Robomongo 的话,可以通过"Options" - “Display Dates in…” - "Local Timezone" 来设置显示本地时间。