面试准备03-Java线程和并发
面试准备笔记之Java多线程和并发 java.util.concurrent (J.U.C)
随笔分类 - Java并发编程 - 海 子 http://www.cnblogs.com/dolphin0520/category/602384.html
随笔分类 - Java多线程 http://www.cnblogs.com/xiaoxi/category/961349.html
方腾飞 - 聊聊并发 http://www.infoq.com/cn/profile/方腾飞
专栏-Java并发编程系列 http://blog.csdn.net/column/details/concurrency.html
线程与线程池
高性能无锁队列
被广泛认可的两个高性能无锁队列:
- Disruptor 环形队列
- JCTools MSPC 队列
Java 内置队列在高并发时的问题
队列的底层一般分成三种:数组、链表和堆(优先队列):
- 基于数组线程安全的队列,比较典型的是 ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全,有锁结构,高并发下有性能问题
- 基于链表的线程安全队列分成 LinkedBlockingQueue 和 ConcurrentLinkedQueue 两大类:
- LinkedBlockingQueue 也通过加锁的方式来实现线程安全,有锁结构,高并发下有性能问题
- ConcurrentLinkedQueue 是无锁结构,通过原子变量 CAS 无锁方式来实现,高并发下链表会有大量的节点创建/GC回收的压力,这会导致STW的产生,容易出现业务卡顿
JCTools 无锁队列
JCTools / JCTools https://github.com/JCTools/JCTools Java Concurrency Tools(JCTools) Java 并发工具,主要提供了 高性能无锁队列,即 基于数组 + CAS 操作实现的无锁安全队列。
JCTools 提供如下几个高性能无锁队列:
- SPSC - Single Producer Single Consumer (Wait Free, bounded and unbounded) 单生产者单消费者
- MPSC - Multi Producer Single Consumer (Lock less, bounded and unbounded) 多生产者单消费者
- SPMC - Single Producer Multi Consumer (Lock less, bounded) 单生产者多消费者
- MPMC - Multi Producer Multi Consumer (Lock less, bounded) 多生产者多消费者
Netty 中直接引入了 JCTools 的 Mpsc Queue,Caffeine 中引入了 JCTools 的 Mpsc Queue
JCTools 的无锁队列实现原理和 Disruptor 类似,都是基于环形数组(RingBuffer)和序列号(Sequence)来控制事件的生产和消费。每个生产者和消费者都有自己的序列号,通过比较序列号的大小来判断是否有新的事件可以生产或消费。
JCTools 的无锁队列之所以快,主要有以下几个原因: 1、高效的数据结构:JCTools 的无锁队列使用环形数组,这种数据结构可以减少内存分配和释放的开销,提高数据访问效率。 2、无锁设计:JCTools 的无锁队列完全避免了锁的使用,通过 CAS 操作和内存屏障来实现线程间的同步。 3、缓存行填充:为了避免伪共享问题,JCTools 的无锁队列使用了缓存行填充的技术,使得每个元素都占用一个缓存行。 4、优化的内存访问模式:JCTools 的无锁队列在访问内存时,采用了一种称为“机械交换”的模式,这种模式可以避免不必要的内存屏障,进一步提高性能。
Disruptor 无锁队列
LMAX-Exchange / disruptor https://github.com/LMAX-Exchange/disruptor
Disruptor 采用 CAS 算法,同时内部通过环形队列实现有界队列。
1、采用环形数组结构,数组元素不会被回收,避免频繁的GC 2、每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。 整个过程通过原子变量CAS,保证操作的线程安全。
Disruptor 的实现原理主要是通过一个环形的数组(RingBuffer)和一系列的序列号(Squence)来控制事件的生产和消费。生产者和消费者都有各自的序列号,生产者在生产事件时,将事件放到环形数组的下一个位置,然后更新自己的序列号。消费者在消费事件时,会先比较自己的序列号和生产者的序列号,如果生产者的序列号大于消费者的序列号,说明有新的事件可以消费,消费者就更新自己的序列号并消费事件。这样,通过序列号的比较和更新,实现了生产者和消费者的同步。
Disruptor 的性能之所以高,主要有以下几点原因: 1、缓存行填充:在现代CPU中,缓存行的大小通常是64字节,为了避免伪共享,Disruptor 使用了 RingBuffer 这个环形的数据结构,并且用64字节进行填充,从而使得每个元素占用一个缓存行,消除了伪共享问题。 2、无锁设计:Disruptor 完全避免了使用锁,它的生产者和消费者之间通过CAS操作和内存屏障来同步状态,避免了锁的开销。 3、批处理:Disruptor 的消费者可以一次性获取一批事件进行处理,这样可以有效减少线程切换的开销。 4、避免休眠:Disruptor 使用一种叫做 Busy Spin 的策略,消费者在没有事件可消费时会忙等待,而不是进入休眠状态,这样可以避免线程从休眠状态唤醒带来的延迟。 5、高效的数据结构:Disruptor 使用了环形数组的数据结构,环形数组的优点是可以进行循环使用,避免了频繁的内存分配和释放。
并发集合
ConcurrentHashMap
ConcurrentHashMap 是一个线程安全的 Hash Table,它的主要功能是提供了一组和HashTable功能相同但是线程安全的方法。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap在jdk1.7中是采用Segment + HashEntry + ReentrantLock的方式进行实现的,而1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现。
ConcurrentHashMap内部实现(jdk1.7)
ConcurrentHashMap是使用了锁分段技术技术来保证线程安全的,锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
相对 HashMap 和 Hashtable, ConcurrentHashMap 增加了Segment 层,每个Segment 原理上等同于一个 Hashtable, ConcurrentHashMap 为 Segment 的数组。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
向 ConcurrentHashMap 中插入数据或者读取数据,首先都要将相应的 Key 映射到对应的 Segment,因此不用锁定整个类, 只要对单个的 Segment 操作进行上锁操作就可以了。理论上如果有 n 个 Segment,那么最多可以同时支持 n 个线程的并发访问,从而大大提高了并发访问的效率。另外 rehash() 操作也是对单个的 Segment 进行的,所以由 Map 中的数据量增加导致的 rehash 的成本也是比较低的。
ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
单个 Segment 的进行数据操作的源码如下:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
…… // 代码省略,具体请查看源码
} finally {
unlock();
}
}
V replace(K key, int hash, V newValue) {
lock();
try {
HashEntry<K,V> e = getFirst(hash);
…… // 代码省略,具体请查看源码
} finally {
unlock();
}
}
可见对 单个的 Segment 进行的数据更新操作都是 加锁的,从而能够保证线程的安全性。
ConcurrentHashMap的应用场景是高并发,但是并不能保证线程安全,而同步的HashMap和HashMap的是锁住整个容器,而加锁之后ConcurrentHashMap不需要锁住整个容器,只需要锁住对应的Segment就好了,所以可以保证高并发同步访问,提升了效率。
Java - 线程安全的 HashMap 实现方法及原理 http://liqianglv2005.iteye.com/blog/2025016
Java并发编程之ConcurrentHashMap http://www.iteye.com/topic/1103980
put和remove操作(只能链表头部插入)
jdk1.7中的HashEntry结构:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。
注:jdk1.8中使用Node结构
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
transient volatile Node<K,V>[] table; //存储键值对的Node数组(桶),默认长度16
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
}
ConcurrentHashMap的get为什么可以不加锁?
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
jdk1.7之前的get方法:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile // ①
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null) // ② 注意这里
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读,我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢? 原因是它的get方法里将要使用的共享变量都定义成volatile,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
jdk 1.8 及以后的get
其中的 tabAt(tab, (n - 1) & h) 是通过 Unsafe 类获取 table[] 数组的 第 (n-1)&h 个元素的 volatile 类型 Node
//会发现源码中没有一处加了锁
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //计算hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {//读取首节点的Node元素, volatile 的
if ((eh = e.hash) == h) { //如果该节点就是首节点就返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来
//eh=-1,说明该节点是一个ForwardingNode,正在迁移,此时调用ForwardingNode的find方法去nextTable里找。
//eh=-2,说明该节点是一个TreeBin,此时调用TreeBin的find方法遍历红黑树,由于红黑树有可能正在旋转变色,所以find里会有读写锁。
//eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//既不是首节点也不是ForwardingNode,那就往下遍历
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
//可以看到这些都用了volatile修饰
volatile V val;
volatile Node<K,V> next;
}
为什么ConcurrentHashMap的读操作不需要加锁? https://www.cnblogs.com/keeya/p/9632958.html
为什么读取到的结点value有可能是空的?
理论上结点的值不可能为空,这是因为put的时候就进行了判断,如果为空就要抛NullPointerException。 如果另一个线程刚好new 这个对象时,当前线程来get它。因为没有同步,就可能会出现当前线程得到的newEntry对象是一个没有完全构造好的对象引用。没有锁同步的话,new 一个对象对于多线程看到这个对象的状态是没有保障的,这里同样有可能一个线程new这个对象的时候还没有执行完构造函数就被另一个线程得到这个对象引用。 所以才需要判断一下:if (v != null) 如果确实是一个不完整的对象,则使用锁的方式再次get一次。
但是,get方法只能保证读取到几乎最新的数据,虽然可能不是最新的。要得到最新的数据,只有采用完全的同步。
聊聊并发(四)——深入分析ConcurrentHashMap(对为什么get方法不需要加锁解释的很简洁) http://www.infoq.com/cn/articles/ConcurrentHashMap
ConcurrentHashMap(详细讲了happens-before,解释为什么get可以不加锁,但太详细太繁琐了) http://www.cnblogs.com/yydcdut/p/3959815.html
Java并发编程之ConcurrentHashMap http://www.iteye.com/topic/1103980
ConcurrentHashMap之实现细节 http://www.iteye.com/topic/344876
ConcurrentHashMap不能保证完全线程安全
ConcurrentHashMap的线程安全指的是,它的每个方法单独调用(即原子操作)都是线程安全的,但是代码总体的互斥性并不受控制。
ConcurrentHashMap是线程安全的,那是在他们的内部操作,其外部操作还是需要自己来保证其同步的
ConcurrentHashMap、synchronized与线程安全 http://blog.csdn.net/sadfishsc/article/details/42394955
ConcurrentHashMap并不是绝对线程安全的 http://blog.51cto.com/laokaddk/1345191
java8对ConcurrentHashMap的改进
改进一:不再使用segments分段加锁(Segment虽保留,但已经简化属性,仅仅是为了兼容旧版本。),直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。 对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
java8中对ConcurrentHashMap的改进 http://blog.csdn.net/wangxiaotongfan/article/details/52074160
Unsafe与CAS
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
ConcurrentHashMap定义了三个原子操作,用于对指定位置的节点进行操作。正是这些原子操作保证了ConcurrentHashMap的线程安全。
//获得在i位置上的Node节点
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
//利用CAS算法设置i位置上的Node节点。之所以能实现并发是因为他指定了原来这个节点的值是多少
//在CAS算法中,会比较内存中的值与你指定的这个值是否相等,如果相等才接受你的修改,否则拒绝你的修改
//因此当前线程中的值并不是最新的值,这种修改可能会覆盖掉其他线程的修改结果 有点类似于SVN
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
//利用volatile方法设置节点位置的值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
ConcurrentHashMap总结 https://my.oschina.net/hosee/blog/675884
CopyOnWriteArrayList
CopyOnWriteArrayList 是 ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
Copy-On-Write 简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容 Copy 出去形成一个新的内容然后再改,这是一种延时懒惰策略。
从 JDK1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制实现的并发容器,它们是 CopyOnWriteArrayList 和 CopyOnWriteArraySet。CopyOnWrite 容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWriteArrayList 的 add 方法如下:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
CopyOnWriteArrayList 的整个 add 操作都是在锁的保护下进行的。这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
读的时候不需要加锁,如果读的时候有多个线程正在向 ArrayList 添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的ArrayList。
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景
使用 CopyOnWriteMap 需要注意两件事情:
- 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
- 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。
缺点: 1、内存占有问题:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存。 2、数据一致性:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器
聊聊并发-Java中的Copy-On-Write容器 http://ifeve.com/java-copy-on-write/
线程安全的CopyOnWriteArrayList介绍 http://blog.csdn.net/linsongbin1/article/details/54581787
CopyOnWriteArrayList与Collections.synchronizedList对比
CopyOnWriteArrayList为何物?ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。 该类产生的开销比较大,但是在两种情况下,它非常适合使用。 1:在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时。 2:当遍历操作的数量大大超过可变操作的数量时。遇到这两种情况使用CopyOnWriteArrayList来替代ArrayList再适合不过了。
- CopyOnWriteArrayList在线程对其进行变更操作的时候,会拷贝一个新的数组以存放新的字段,因此写操作性能很差;
- 而Collections.synchronizedList读操作采用了synchronized,因此读性能较差。
java8中对ConcurrentHashMap的改进 http://blog.csdn.net/wangxiaotongfan/article/details/52074160
ConcurrentHashSet
Java 中没有 ConcurrentHashSet 类
Java 中有 CopyOnWriteArraySet 它不适合大型线程安全集的应用程序,仅适用于数据量较小的且只读操作数量远远超过写入操作的集合。
那 Java 中想并发使用集合改如何做呢?
1 直接使用 ConcurrentHashMap, 只使用他的 key 域
2 使用 Java 8 中 ConcurrentHashMap 新加的静态方法 public static <K> KeySetView<K,Boolean> newKeySet(),该方法返回由给定类型的 ConcurrentHashMap 支持的 Set,其中值为 Boolean.TRUE
3 使用 Guava 的 Sets.newConcurrentHashSet()
线程安全队列
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是一个采用双向链表实现的无界并发非阻塞队列,它属于 LinkedQueue 的安全版本。 ConcurrentLinkedQueue 内部采用 CAS 操作保证线程安全。
ConcurrentLinkedDeque
ConcurrentLinkedDeque 也是一种采用双向链表结构的无界并发非阻塞队列。 与 ConcurrentLinkedQueue 不同的是,ConcurrentLinkedDeque 属于双端队列,它同时支持 FIFO 和 FILO 两种模式,可以从队列的头部插入和删除数据,也可以从队列尾部插入和删除数据,适用于多生产者和多消费者的场景。
ThreadLocal
ThreadLocal, 即线程本地变量,ThreadLocal 变量在每个线程中都有一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。
为什么要使用ThreadLocal变量?
在并发编程的时候,成员变量如果不做任何处理其实是线程不安全的,各个线程都在操作同一个变量,显然是不行的,并且我们也知道 volatile 这个关键字也是不能保证线程安全的。
那么在有一种情况之下,我们需要满足这样一个条件:变量是同一个,但是每个线程都使用同一个初始值,也就是使用同一个变量的一个新的副本。这种情况之下 ThreadLocal 就非常使用。
ThreadLocal的四个方法
ThreadLocal 类提供了 4 个操作数据的方法:
public T get();
public void set(T value);
public void remove();
protected T initialValue();
get() 方法是用来获取ThreadLocal在当前线程中保存的变量副本,
set() 用来设置当前线程中变量的副本,
remove() 将当前线程局部变量的值删除,目的是为了减少内存的占用,该方法是 JDK 5.0 新增的方法。需要指出的是,当线程结束后,对应该线程的局部变量将自动被垃圾回收,所以显式调用该方法清除线程的局部变量并不是必须的操作,但它可以加快内存回收的速度。
initialValue() 返回该线程局部变量的初始值,该方法是一个 protected 的方法,显然是为了让子类覆盖而设计的。这个方法是一个延迟调用方法,在线程第 1 次调用 get() 或 set(Object) 时才执行,并且仅执行 1 次,ThreadLocal 中的缺省实现直接返回一个 null。
ThreadLocal实现原理
1、每个 Thread 对象内部都维护了一个类型为 ThreadLocalMap 的变量,key为使用弱引用的ThreadLocal实例,value为线程变量的副本。也就是 ThreadLocal 的 Map,可以存放若干个 ThreadLocal。
public class Thread implements Runnable {
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
}
ThreadLocalMap 是 ThreadLocal 类内的一个静态内部类,类似于 Map,用键值对的形式存储每一个线程的变量副本,key 为当前 ThreadLocal 对象,value 对应线程的变量副本。
也就是说 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。
2、当我们在调用 get() 方法的时候,先获取当前线程,然后获取到当前线程的 ThreadLocalMap 对象 t.threadLocals;,如果非空,那么取出 ThreadLocalMap 中的 value(注意用的 key 是当前 ThreadLocal 对象,即 this),否则进行初始化,初始化就是将 initialValue 的值 set 到 ThreadLocal 中。
public T get() {
Thread t = Thread.currentThread(); //获取当前线程
ThreadLocalMap map = getMap(t); //获取到当前线程的ThreadLocalMap对象, t.threadLocals;
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); //取出ThreadLocal的value
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue(); //进行初始化,将initialValue的值set到ThreadLocal中
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
3、set() 方法如下,也是先获取当前线程,取出 ThreadLocalMap 对象,非空则 set 值,key 是当前 ThreadLocal 对象,value 是 T 类型变量;为空则创建 ThreadLocalMap 对象后 set 值
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
从本质来讲,就是每个线程都维护了一个 map,而这个 map 的 key 就是 ThreadLocal 对象(每个线程中可以有多个 threadLocal 变量,对应不同的 key),而值就是我们 set 的那个值,每次线程在 get 的时候,都从自己的变量中取值,既然从自己的变量中取值,那肯定就不存在线程安全问题。
ThreadLocal 的应用场景
总之就是各种需要线程隔离的场景,
线程隔离的Session
最常见的 ThreadLocal 使用场景为用来解决 数据库连接、Session管理等。 比如一个 web 后台服务,同时并发有好多 service 线程在处理请求,如果某些数据需要在线程间隔离开,就是需要用到 thread_local, 典型的比如 login_info 登录信息, session_id 会话ID等。
DAO 的 Connection
比如说 DAO 的数据库连接,我们知道 DAO 是单例的,那么他的属性 Connection 就不是一个线程安全的变量。而我们每个线程都需要使用他,并且各自使用各自的。这种情况,ThreadLocal 就比较好的解决了这个问题。 例如:
//使用匿名内部类,重写initialValue()方法
private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() {
public Connection initialValue() {
Class.forName("com.mysql.jdbc.Driver");
return DriverManager.getConnection("url", "userName", "password");
}
};
public static Connection getConnection() {
return connectionHolder.get();
}
各种线程隔离的Holder
还有个经典的使用场景就是各种 Holder, 一般都要求是线程隔离的, Spring 中可以找到一大堆,我们还可以定义自己的线程隔离的 holder 用来保存各种需要在同一线程的不同阶段共享的变量 例如,定义一个保存用户名的 holder
public class UserNameHolder {
private static final ThreadLocal<String> LOGIN_USER_CONTEXT =
new NamedThreadLocal<String>("Login user context");
public static void set(String userName) {
LOGIN_USER_CONTEXT.set(userName);
}
public static String get() {
return LOGIN_USER_CONTEXT.get();
}
}
日志系统的MDC
日志系统的 MDC 数据是存储在 ThreadLocal 中的,具体来说是一个 ThreadLocal<Map<String, String>> localMap, 即线程本地 Map,用来实现不同线程间的 MDC 隔离。
Java并发编程:深入剖析ThreadLocal - 海子 http://www.cnblogs.com/dolphin0520/p/3920407.html
ThreadLocal详解 https://www.cnblogs.com/dreamroute/p/5034726.html
一次ThreadLocal和线程池导致的数据错乱案例排查
背景 Spring Boot 后台服务, undertow 容器(类似Tomcat),200个工作线程。 提供用户信息增删查改的微服务,比如叫 user 服务,里面一个需求是用户信息有任何变动后通过一个 kafka 消息广播出去。
比如更新用户信息的方法如下:
public updateUser(request) {
userService.updateName();
addressService.updateAddress();
familyService.updateFamily();
... ...
kafkaProducer.sendProfileMessage();
}
由于用户的不同维度信息是存在不同表中的,更新也分布在不同的service中,为了最后汇总到一条 kafka 中发送, 设计了一个 线程隔离的 用户上下文信息 Holder ,其中 UserProfileContext 就是存放user信息的bean, 搞成了一个 ThreadLocal 变量
public class UserProfileContextHolder {
private static final ThreadLocal<UserProfileContext> USER_PROFILE_CONTEXT_THREAD_LOCAL = ThreadLocal
.withInitial(UserProfileContext::new);
public static void set(UserProfileContext context) {
USER_PROFILE_CONTEXT_THREAD_LOCAL.set(context);
}
public static UserProfileContext get() {
return USER_PROFILE_CONTEXT_THREAD_LOCAL.get();
}
public static void clean() {
USER_PROFILE_CONTEXT_THREAD_LOCAL.remove();
}
}
在每个 updateXxxx() 方法中用 UserProfileContext 记录用户信息的变更,最后 sendProfileMessage 中读取 UserProfileContext 中记录的变动信息发出 kafka 消息。
public void sendProfileMessage() {
UserProfileContext context = UserProfileContextHolder.get();
if (null == context || null == context.getUserId()) {
logger.info("User profile context is null or its userId is null.");
UserProfileContextHolder.clean();
return;
}
logger.info("Start to sendProfileMessage, context: {}", JSONUtils.writeValue(context));
// 组装并发送kafka
// 清理 context
UserProfileContextHolder.clean();
}
问题: 发出的kafka消息内容错乱,A用户的kafka消息中出现了B用户的属性
原因:
undertow 或 Tomcat 等容器会启动线程池并发的处理请求,线程池中的工作线程都是复用的,工作线程中上一个用户的上下文信息没有 clean,等下一个用户复用工作线程时读取到了上一个用户的信息。
如果没有抛异常的话,最后发送完消息会 clean 上下文,一切正常。
一旦clean之前抛了异常就出问题了,假如在 updateFamily() 更新家庭属性方法中抛了异常,没走到 clean 就结束方法,则此工作线程中的上下文信息就保留下来了。
解决: 1、controller 进入 service 之前先 clean 2、捕获整个方法的异常,finally 中 clean
ThreadLocal与内存泄露(Map的key是弱引用)
ThreadLocalMap 使用 ThreadLocal 的弱引用作为 key,如果一个 ThreadLocal 没有外部强引用来引用它,那么系统 GC 的时候,这个 ThreadLocal 势必会被回收,这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry,就没有办法访问这些 key 为 null 的 Entry 的 value,如果当前线程再迟迟不结束的话,这些 key 为 null 的 Entry 的 value 就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value 永远无法回收,造成内存泄漏。
其实,ThreadLocalMap 的设计中已经考虑到这种情况,也加上了一些防护措施:在 ThreadLocal 的 get(),set(),remove() 的时候都会通过 expungeStaleEntry() 方法清除线程 ThreadLocalMap 里所有 key 为 null 的 value。
但是这些被动的预防措施并不能保证不会内存泄漏: 使用 static 的 ThreadLocal,延长了 ThreadLocal 的生命周期,可能导致的内存泄漏(参考ThreadLocal 内存泄露的实例分析)。 分配使用了 ThreadLocal 又不再调用get(),set(),remove()方法,那么就会导致内存泄漏。
深入分析 ThreadLocal 内存泄漏问题 https://www.jianshu.com/p/1342a879f523
ThreadLocalMap里Entry为何声明为WeakReference?
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
To help deal with very large and long-lived usages, the hash table entries use WeakReferences for keys. 为了应对非常大和长时间的用途,哈希表使用弱引用的 key。
ThreadLocalMap 是使用 ThreadLocal 的弱引用作为 Key 的,弱引用的对象在 GC 时会被回收。
ThreadLocalMap里Entry为何声明为WeakReference? https://www.cnblogs.com/waterystone/p/6612202.html
在线程间传递 ThreadLocal
父子线程间传递 ThreadLocal
通过 InheritableThreadLocal 可以在父子线程之间传递 ThreadLocal ,父线程为当前线程,而子线程即为在当前线程中声明的线程。如果 ThreadLocal 为 InheritableThreadLocal ,子线程就可以拿到父线程在 ThreadLocal 中设置的值。
ThreadLocal 变量传入线程池
1、将 ThreadLocal 中需要的值取出,显式传递到任务中,显然这样是不优雅的,会让方法增加了一些与原本业务无关的参数。
2、使用 阿里巴巴 开源的 TransmittableThreadLocal
3、使用 Spring ThreadPoolTaskExecutor 线程池,重写 TaskDecorator 装饰器,执行前将上下文拷贝入线程中。
ThreadLocal 跨线程传递 https://my.oschina.net/bingzhong/blog/2990522
InheritableThreadLocal
InheritableThreadLocal 继承了 ThreadLocal,此类扩展了 ThreadLocal 以提供从父线程到子线程的值的继承: 当创建子线程时,子线程接收父线程具有的所有可继承线程局部变量的初始值。 子线程修改不影响父线程的变量 通常子线程的值与父线程的值是一致的。 但是,通过重写此类中的 childValue 方法,可以将子线程的值作为父线程的任意函数。
ThreadLocal 有一个问题,就是它只保证在同一个线程间共享变量,也就是说如果这个线程起了一个新线程,那么新线程是不会得到父线程的变量信息的。因此,为了保证子线程可以拥有父线程的某些变量视图,JDK 提供了一个数据结构 InheritableThreadLocal
package java.lang;
import java.lang.ref.*;
public class InheritableThreadLocal<T> extends ThreadLocal<T> {
protected T childValue(T parentValue) {
return parentValue;
}
ThreadLocalMap getMap(Thread t) {
return t.inheritableThreadLocals;
}
void createMap(Thread t, T firstValue) {
t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
}
}
InheritableThreadLocal 主要重写了 ThreadLocal 的 getMap() 和 creatMap() 方法,跟 ThreadLocal 中的差别在于把 ThreadLocal 中的 threadLocals 换成了 inheritableThreadLocals,这两个变量都是 ThreadLocalMap 类型,并且都是Thread类的属性。
InheritableThreadLocal 如何继承父线程的值?
为了支持 InheritableThreadLocal 的父子线程传递变量,JDK 在 Thread 中,定义了 ThreadLocal.ThreadLocalMap inheritableThreadLocals 属性。该属性变量在线程初始化的时候,如果父线程的该变量不为null,则会把其值复制到子线程的 inheritableThreadLocals
先看下线程的初始化方法,即 Thread 类的 init() 方法:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
... ...
Thread parent = currentThread();
... ...
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
... ...
}
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
从中可以知道当父线程的 inheritableThreadLocals 不为空时,当前线程的 inheritableThreadLocals 属性值会被直接创建,并被赋予跟父线程的 inheritableThreadLocals 属性一样的值,createInheritedMap() 方法的内容就是把入参的 map 拷贝到新生成的 ThreadLocalMap 中。
所以,当一个子线程创建的时候,会把父线程的 inheritableThreadLocals 属性的值继承到自己的 inheritableThreadLocals 属性。
Java并发:InheritableThreadLocal详解 https://blog.csdn.net/v123411739/article/details/79117430
InheritableThreadLocal 无法用于向线程池中传值
因为线程池中的线程是预先创建好的,所以在父线程中设置的 InheritableThreadLocal 值,线程池中的线程是无法获取的。
TransmittableThreadLocal(TTL)
alibaba / transmittable-thread-local https://github.com/alibaba/transmittable-thread-local/
使用 ttl 在线程池间传递 threadlocal 变量
实现原理
TTL 在使用时使用类 TransmittableThreadLocal 替代 ThreadLocal ,且需要将相关的 Runnable 或是 Callable 等类进行包装。
TransmittableThreadLocal 继承了 InheritableThreadLocal ,内部维护了一个静态的 InheritableThreadLocal 的 holder,存储的是而 TransmittableThreadLocal 作为 key 的 WeakHashMap 。
private static InheritableThreadLocal<Map<TransmittableThreadLocal<?>, ?>> holder =
new InheritableThreadLocal<Map<TransmittableThreadLocal<?>, ?>>() {
@Override
protected Map<TransmittableThreadLocal<?>, ?> initialValue() {
return new WeakHashMap<>();
}
@Override
protected Map<TransmittableThreadLocal<?>, ?> childValue(Map<TransmittableThreadLocal<?>, ?> parentValue) {
return new WeakHashMap<TransmittableThreadLocal<?>, Object>(parentValue);
}
};
holder 会将应用中用到的 TransmittableThreadLocal 作为 key 存储起来。
之后想要线程私有存储实现跨线程传递,需要将 Runnable 或 Callable 包装成 TtlRunnable 、TtlCallable 。
private TtlRunnable(@Nonnull Runnable runnable, boolean releaseTtlValueReferenceAfterRun) {
this.capturedRef = new AtomicReference<Object>(capture());
this.runnable = runnable;
this.releaseTtlValueReferenceAfterRun = releaseTtlValueReferenceAfterRun;
}
其中 capture 方法就是获取一份当前线程使用 TransmittableThreadLocal 存储起来的私有存储数据的拷贝。
@Nonnull
public static Object capture() {
Map<TransmittableThreadLocal<?>, Object> captured = new HashMap<TransmittableThreadLocal<?>, Object>();
for (TransmittableThreadLocal<?> threadLocal : holder.get().keySet()) {
captured.put(threadLocal, threadLocal.copyValue());
}
return captured;
}
而这份拷贝在实际的 Runnable 运行前,会设置到当前所使用的线程池的线程的存储空间中,在后续的执行过程中,可以通过相同的 TransmittableThreadLocal 实例获取到之前线程所存储的数据。 而且由于线程池的线程是会复用的,所以在设置之前线程的私有存储前,会将该线程池线程的私有存储备份,在任务执行完成后将会复原数据。
@Override
public void run() {
Object captured = capturedRef.get();
if (captured == null || releaseTtlValueReferenceAfterRun && !capturedRef.compareAndSet(captured, null)) {
throw new IllegalStateException("TTL value reference is released after run!");
}
Object backup = replay(captured);
try {
runnable.run();
} finally {
restore(backup);
}
}
ThreadLocal 跨线程传递 https://my.oschina.net/bingzhong/blog/2990522
TransmittableThreadLocal 的三种使用方式
修饰Runnable或Callable
1、使用 TtlRunnable 和 TtlCallable 来修饰传入线程池的 Runnable 和 Callable
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<String>();
context.set("value-set-in-parent");
Runnable task = new RunnableTask();
// 额外的处理,生成修饰了的对象ttlRunnable
Runnable ttlRunnable = TtlRunnable.get(task);
executorService.submit(ttlRunnable);
// =====================================================
// Task中可以读取,值是"value-set-in-parent"
String value = context.get();
修饰Executor和ExecutorService
2、通过工具类 com.alibaba.ttl.threadpool.TtlExecutors 完成,有下面的方法:
getTtlExecutor 修饰接口 Executor
getTtlExecutorService 修饰接口 ExecutorService
ExecutorService executorService = ...
// 额外的处理,生成修饰了的对象executorService
executorService = TtlExecutors.getTtlExecutorService(executorService);
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<String>();
context.set("value-set-in-parent");
Runnable task = new RunnableTask();
Callable call = new CallableTask();
executorService.submit(task);
executorService.submit(call);
// =====================================================
// Task或是Call中可以读取,值是"value-set-in-parent"
String value = context.get();
Java Agent无代码侵入方式
这种方式,实现线程池的传递是透明的,业务代码中没有修饰Runnable或是线程池的代码。即可以做到应用代码 无侵入。
NamedThreadLocal
org.springframework.core.NamedThreadLocal<T>
Spring 提供的一个命名的 ThreadLocal 实现。
package org.springframework.core;
import org.springframework.util.Assert;
public class NamedThreadLocal<T> extends ThreadLocal<T> {
private final String name;
public NamedThreadLocal(String name) {
Assert.hasText(name, "Name must not be empty");
this.name = name;
}
public String toString() {
return this.name;
}
}
并发编程辅助工具
1 CountDownLatch 和 CyclicBarrier 都能够实现线程之间的等待,只不过它们侧重点不同: CountDownLatch 一般用于某个线程 A 等待若干个其他线程执行完任务之后,它才执行; 而 CyclicBarrier 一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行; 另外,CountDownLatch 是不能够重用的,而 CyclicBarrier 是可以重用的。
2 Semaphore 其实和锁有点类似,它一般用于控制对某组资源的访问权限。
CountDownLatch 异步变同步的计数器
CountDownLatch 类位于 java.util.concurrent 包下,利用它可以实现类似计数器的功能。比如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。
构造方法: public CountDownLatch(int count) { }; //参数count为计数值
主要方法: public void await() throws InterruptedException { }; //调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行 public boolean await(long timeout, TimeUnit unit) throws InterruptedException { }; //和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public void countDown() { }; //将count值减1
CountDownLatch使用示例
使用示例,主线程和子线程共享 countDownLatch 计数器,每个子线程运行结束后计数器减1,主线程等计数器减为0再继续执行
@Test
public void testCountDownLatch() throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
int sleepMills = (int)(Math.random() * 10000);
System.out.println(Thread.currentThread() + " sleep " + sleepMills + "mills");
Thread.sleep(sleepMills);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 每个子线程运行结束后计数器减1
countDownLatch.countDown();
}).start();
}
// 主线程挂起,等待所有共享 countDownLatch 的线程运行结束再继续执行
countDownLatch.await();
System.out.println("所有线程运行结束");
}
Java并发编程:CountDownLatch、CyclicBarrier和Semaphore - 海子 http://www.cnblogs.com/dolphin0520/p/3920397.html
CountDownLatch实现原理(AQS)
CountDownLatch 和 ReentrantLock 一样,内部包装了一个继承 AbstractQueuedSynchronizer 抽象类的 Sync 类 。
构造函数传入的参数 count 用来设置 AQS 的 state
使用的是 AQS 的 tryAcquireShared ,获取的是共享状态
countDown() 就是把 state 减1
await() 就是等待计数值 state 减为0
public class CountDownLatch {
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
private final Sync sync;
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public boolean await(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}
public void countDown() {
sync.releaseShared(1);
}
}
CyclicBarrier 可循环屏障
CyclicBarrier 的字面意思是可循环(Cyclic)使用的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。线程进入屏障通过CyclicBarrier的await()方法。
CyclicBarrier字面意思回环栅栏,通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。
构造方法: public CyclicBarrier(int parties) 参数parties指让多少个线程或者任务等待至barrier状态 public CyclicBarrier(int parties, Runnable barrierAction) 参数barrierAction为当这些线程都达到barrier状态时会执行的内容。
主要方法: public int await() 用来挂起当前线程,直至所有线程都到达barrier状态再同时执行后续任务; public int await(long timeout, TimeUnit unit) 让这些线程等待至一定的时间,如果还有线程没有到达barrier状态就直接让到达barrier的线程执行后续任务。
使用示例,多个线程并发进行写操作,当所有线程写操作完成后,才继续执行后续任务
public class Test {
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(2,new Runnable() {
@Override
public void run() {
System.out.println("当前线程"+Thread.currentThread().getName());
}
});
//new thread.start,创建并启动一个线程,run()方法包括三部分:写操作,barrier.await(),后续任务
//new thread.start,创建并启动一个线程,run()方法包括三部分:写操作,barrier.await(),后续任务
}
}
启动的多个线程中,先执行完写操作的线程会等待所有线程执行完写操作,当所有线程执行完写操作后(达到barrier状态)后,由最后一个进入barrier的线程去执行barrier的Runnable任务。然后所有线程继续执行后续任务。
Java并发编程:CountDownLatch、CyclicBarrier和Semaphore - 海子 http://www.cnblogs.com/dolphin0520/p/3920397.html
CountDownLatch和CyclicBarrier区别(可重用)
CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;
而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
CyclicBarrier原理(Lock,计数器,Generation换代)
实现原理: 在 CyclicBarrier 的内部定义了一个 Lock 对象,每当一个线程调用 CyclicBarrier 的 await 方法时,将剩余拦截的线程数减1,然后判断剩余拦截数是否为0,如果不是,进入 Lock 对象的条件队列等待。如果是,执行 barrierAction 对象的 Runnable 方法,然后将锁的条件队列中的所有线程放入锁等待队列中,这些线程会依次的获取锁、释放锁,接着先从await方法返回,再从 CyclicBarrier 的 await 方法中返回。
Generation 是一代的意思,唯一记录了 barrier 是否 broken。看 CyclicBarrier 的名字也知道,它是可重复使用的,每次使用 CyclicBarrier,本次所有线程同属于一代,即同一个 Generation。当 parties 个线程到达 barrier 时,需要调用 nextGeneration 更新换代。
barrier 被 broken 后,调用 breakBarrier 方法,将 generation.broken 设置为 true,并使用 signalAll 通知所有等待的线程。
JUC回顾之-CyclicBarrier底层实现和原理 https://www.cnblogs.com/200911/p/6060195.html
Java并发包中CyclicBarrier的工作原理、使用示例 https://www.cnblogs.com/nullzx/p/5271964.html
分析同步工具Semaphore和CyclicBarrier的实现原理 https://www.jianshu.com/p/060761df128b
Semaphore 信号量
Semaphore 翻译成字面意思为 信号量,Semaphore 可以控同时访问的线程个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
public Semaphore(int permits) 参数 permits 表示许可数目,即同时可以允许多少线程进行访问
public Semaphore(int permits, boolean fair) 第二个参数 fair 表示是否公平,设为 true 时信号量会保证先 acquire() 的线程优先获得信号量。
通过Semaphore信号量限制最大并发数
通过信号量 Semaphore 限制多线程执行 process() 方法的最大并发数为 100
Semaphore semaphore = new Semaphore(100, true);
public void batchProcess(TaskDataVO taskDataVO) {
executor.execute(() -> {
try {
semaphore.acquire();
try {
process(taskDataVO);
} catch (Exception e) {
log.error("process error", e);
} finally {
semaphore.release();
}
} catch (InterruptedException e) {
logger.error("acquire semaphore err", e);
}
});
}
Java并发编程:CountDownLatch、CyclicBarrier和Semaphore - 海子 http://www.cnblogs.com/dolphin0520/p/3920397.html
阻塞队列
阻塞队列和普通队列的区别?
阻塞队列 BlockingQueue 接口继承自 Queue 接口,相比于 Queue 多了两个操作:
- 当生产者向队列添加元素但队列已满时,生产者会被阻塞;
- 当消费者从队列移除元素但队列为空时,消费者会被阻塞。
阻塞队列常用操作put()/take()
阻塞队列相对于普通的 Queue 接口多了插入和删除时 阻塞 和 超时退出 的操作方法:
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(E) | offer(E) | put(E) | offer(E, timeout, unit) |
| 移除方法 | remove() | poll() | take() | poll(timeout, unit) |
| 检查方法 | element() | peek() | N/A | N/A |
抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。 返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
聊聊并发(七)——Java中的阻塞队列 http://ifeve.com/java-blocking-queue/
drainTo()
将队列中的所有元素移动到另一个集合中。这个操作是原子的,即要么所有元素都被成功转移,要么都不被转移,不会出现只转移了部分元素的情况。
drainTo(Collection<? super E> c) 将队列中所有可用的元素移动到给定的集合中。此操作是原子的。返回值是成功转移的元素数量。
drainTo(Collection<? super E> c, int maxElements) 最多将给定数量的元素从队列移动到给定的集合中。此操作也是原子的。返回值是成功转移的元素数量。
常用阻塞队列
在 java.util.concurrent 包下提供了若干个阻塞队列
JDK 提供了 7 个阻塞队列。分别是:
ArrayBlockingQueue一个由数组结构组成的有界阻塞队列。LinkedBlockingQueue一个由链表结构组成的有界阻塞队列。PriorityBlockingQueue一个支持优先级排序的无界阻塞队列。DelayQueue一个使用优先级队列实现的无界阻塞队列。SynchronousQueue一个不存储元素的阻塞队列。LinkedTransferQueue一个由链表结构组成的无界阻塞队列。jdk7新增LinkedBlockingDeque一个由链表结构组成的双向阻塞队列。
聊聊并发(七)——Java中的阻塞队列 http://ifeve.com/java-blocking-queue/
Java并发编程:阻塞队列 - 海子 http://www.cnblogs.com/dolphin0520/p/3932906.html
ArrayBlockingQueue
ArrayBlockingQueue 是基于数组实现的一个有界阻塞队列,在创建 ArrayBlockingQueue 对象时必须制定容量大小。 ArrayBlockingQueue 可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的线程最优先能够访问队列。 ArrayBlockingQueue(1000, true); 创建公平队列,可以按照FIFO原则对等待的线程进行排序
内部是使用了一个重入锁 ReentrantLock,并搭配 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。 从队列读取数据时,如果队列为空,那么会阻塞等待,直到队列有数据了才会被唤醒。 写入数据时,如果队列已经满了,也同样会进入阻塞状态,直到队列有空闲才会被唤醒。
LinkedBlockingQueue
LinkedBlockingQueue 基于链表实现的一个阻塞队列,在创建 LinkedBlockingQueue 对象时如果不指定容量大小,则默认大小为 Integer.MAX_VALUE
LinkedBlockingQueue 内部使用了 takeLock、putLock 两个重入锁 ReentrantLock,以及 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。 采用读锁和写锁的好处是可以避免读写时相互竞争锁的现象,所以相比于 ArrayBlockingQueue,LinkedBlockingQueue 的性能要更好。
PriorityBlockingQueue
ArrayBlockingQueue 和 LinkedBlockingQueue 都是先进先出(FIFO)队列,而 PriorityBlockingQueue 却不是,它会按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都是优先级最高的元素。 PriorityBlockingQueue 是采用最小堆实现的优先级队列。
PriorityBlockingQueue 是无界阻塞队列,即容量没有上限(通过源码就可以知道,它没有容器满的信号标志 notFull),每次 put 都不会发生阻塞。 PriorityBlockingQueue 底层的最小堆是采用数组实现的,当元素个数大于等于最大容量时会触发扩容。在扩容时会先释放锁,保证其他元素可以正常出队,然后使用 CAS 操作确保只有一个线程可以执行扩容逻辑。
PriorityBlockingQueue 内部是使用了一个 ReentrantLock 以及一个条件变量 Condition notEmpty 来控制并发访问,
SynchronousQueue
SynchronousQueue 一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQueue
其中 put 和 take 操作都是阻塞的,每一个 put 操作都必须阻塞等待一个 take 操作,反之亦然。 SynchronousQueue 可以理解为生产者和消费者配对的场景,双方必须互相等待,直至配对成功。
线程池的静态工厂方法 Executors.newCachedThreadPool 使用了 SynchronousQueue,
DelayQueue 延时阻塞队列
DelayQueue 是一个支持延时获取元素的无界阻塞队列,常用于缓存、定时任务调度等场景。 DelayQueue 内部使用 PriorityQueue 来实现。 DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法。向队列中存放元素的时候必须指定延迟时间,只有延迟时间已满的元素才能从队列中取出。 DelayQueue 基于 PriorityQueue, 一种延时阻塞队列,DelayQueue 中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue 也是一个无界队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
LinkedBlockingDeque
LinkedBlockingDeque 是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。
相比其他的阻塞队列,LinkedBlockingDeque 多了addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast 等方法,以 First 单词结尾的方法,表示插入、获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入、获取或移除双端队列的最后一个元素。
LinkedTransferQueue(jdk1.7新增)
LinkedTransferQueue 是一个由链表结构组成的无界阻塞 TransferQueue 队列。相对于其他阻塞队列 LinkedTransferQueue 多了 tryTransfer 和 transfer 方法。 相对于其他阻塞队列,LinkedTransferQueue 更能保证数据的实时性,即消费者可以直接从生产者手中取走数据,无需将数据先放在队列中,再由消费者取走,整个过程是可以直接进行转换的。
transfer(E e) 方法。如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer 方法可以把生产者传入的元素立刻 transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer 方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。
tryTransfer(E e) 方法。如果存在等待接收的消费者线程,即可直接将元素e传递给消费者线程,否则直接返回false,不会将元素e插入队列。和 transfer 方法的区别是 tryTransfer 方法无论消费者是否接收,方法立即返回。而 transfer 方法是必须等到消费者消费了才返回。
tryTransfer(E e, long timeout, TimeUnit unit) 如果存在等待接收的消费者线程,即可直接将元素e传递给消费者线程,否则将该元素插入队列,并在插入或传递过程中,线程会进入WAITING状态,直到元素e被消费者线程接收,或者等待超时。
TransferQueue 移交队列接口
我们知道
阻塞队列 BlockingQueue 接口继承自 Queue 接口,相比于 Queue 多了两个操作:put() 当生产者向队列添加元素但队列已满时,生产者会被阻塞; take() 当消费者从队列移除元素但队列为空时,消费者会被阻塞。
而 TransferQueue 接口继承自 BlockingQueue 接口,比 BlockingQueue 更进一步,增加了几个同步性更高的操作方法,生产者会一直阻塞直到所添加到队列的元素被某一个消费者所消费(不仅仅是添加到队列里就完事)。新添加的 transfer() 方法用来实现这种约束。顾名思义,阻塞就是发生在元素从一个线程 transfer 到另一个线程的过程中,它有效地实现了元素在线程之间的传递。
TransferQueue 还包括了其他的一些方法:两个 tryTransfer 方法,一个是非阻塞的,另一个带有 timeout 参数设置超时时间的。还有两个辅助方法 hasWaitingConsumer() 和 getWaitingConsumerCount()
LinkedTransferQueue 链式移交队列
LinkedTransferQueue 实现了 TransferQueue 接口,是一个基于链表的 FIFO 无界阻塞队列,它出现在 JDK7 中。
Doug Lea 大神说 LinkedTransferQueue 是一个聪明的队列,它是 ConcurrentLinkedQueue、SynchronousQueue (公平模式下)、无界的 LinkedBlockingQueues 等的超集。
LinkedTransferQueue 采用一种预占模式。什么意思呢?有就直接拿走,没有就占着这个位置直到拿到或者超时或者中断。即消费者线程到队列中取元素时,如果发现队列为空,则会生成一个 null 节点,然后阻塞等待生产者。后面如果生产者线程入队时发现有一个 null 元素节点,这时生产者就不会入列了,直接将元素填充到该节点上,唤醒该节点的线程,被唤醒的消费者线程拿东西走人。
transfer() 移交元素
public void transfer(E e) throws InterruptedException
若当前存在一个正在等待获取数据的消费者线程(正阻塞在 take() 或带时间参数的 poll(long timeout, TimeUnit unit) 方法上),即立刻将数据 e 移交给该消费者;
否则,会插入当前元素 e 到队列尾部,并且等待进入阻塞状态,直到有消费者线程取走该元素
public void transfer(E e) throws InterruptedException {
if (xfer(e, true, SYNC, 0) != null) {
// 进入到此处, 说明调用线程被中断了
Thread.interrupted(); // 清除中断状态, 然后抛出中断异常
throw new InterruptedException();
}
}
tryTransfer()
public boolean tryTransfer(E e)
若当前存在一个正在等待获取数据的消费者线程(正阻塞在 take() 或带时间参数的 poll(long timeout, TimeUnit unit) 方法上),即立刻将数据 e 移交给该消费者;
若不存在,则返回false,元数 e 并且不进入队列。这是一个不阻塞的操作。
public boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException
若当前存在一个正在等待获取数据的消费者线程(正阻塞在 take() 或带时间参数的 poll(long timeout, TimeUnit unit) 方法上),即立刻将数据 e 移交给该消费者;
否则将插入元素 e 到队列尾部,并且等待被消费者线程获取消费掉;
若在指定的时间内元素 e 无法被消费者线程获取,则返回 false,同时该元素被移除。
hasWaitingConsumer()
public boolean hasWaitingConsumer()
如果当前至少存在一个正在等待获取数据的消费者线程(正阻塞在 take() 或带时间参数的 poll(long timeout, TimeUnit unit) 方法上)则返回 true
getWaitingConsumerCount()
public int getWaitingConsumerCount()
返回正在等待获取数据的消费者线程个数。
LinkedTransferQueue 实现原理
LinkedTransferQueue 是一种无界阻塞队列,底层基于单链表实现 LinkedTransferQueue 中的结点有两种类型:数据结点、请求结点; LinkedTransferQueue 基于无锁算法实现
Dual Queue双重队列数据结构
LinkedTransferQueue 使用了一个叫做 dual data structure 的数据结构,或者叫做 dual queue,译为双重数据结构或者双重队列。
双重队列是什么意思呢? 放取元素使用同一个队列,队列中的节点具有两种模式,一种是数据节点,一种是非数据节点。
放元素时先跟队列头节点对比,如果头节点是非数据节点,就让他们匹配,如果头节点是数据节点,就生成一个数据节点放在队列尾端(入队)。 取元素时也是先跟队列头节点对比,如果头节点是数据节点,就让他们匹配,如果头节点是非数据节点,就生成一个非数据节点放在队列尾端(入队)。 不管是放元素还是取元素,都先跟头节点对比,如果二者模式不一样就匹配它们,如果二者模式一样,就入队。
LinkedTransferQueue 中的链表结点结构 Node 如下:
static final class Node {
final boolean isData; // false if this is a request node
volatile Object item; // initially non-null if isData; CASed to match
volatile Node next;
volatile Thread waiter; // null until waiting
}
isData 是否是数据节点,true 表示数据结点,false 表示请求结点,只有不同类型的结点才能相互匹配,也就标识了是生产者还是消费者
item 元素的值,匹配前后值会发生变化
next 下个结点的指针
waiter 等待此结点的线程
可见
Node 结点有两种类型:数据结点、请求结点,通过字段 isData 区分,只有不同类型的结点才能相互匹配;
Node 结点的值保存在 item 字段,匹配前后值会发生变化;
对于数据节点 匹配前 isData = true; item = 数据结点值, 匹配后 isData = true; item = null 对于请求结点 匹配前 isData = false; item = null, 匹配后 isData = false; item = this
xfer()方法分析
LinkedTransferQueue 中的各种元素操作,最终都是通过 xfer() 方法实现的, xfer 有四个参数
e 表示元素值,对于 put, offer, add 等入队操作,e 非空是元素值;对于 take, poll, remove 等出队操作, e 是 null
haveData 表示是否是数据节点,对于 put, offer, add 等入队操作值为 true,对于 take, poll, remove 等出队操作值为 false
how 表示放取元素的方式,上面提到的四种,NOW、ASYNC、SYNC、TIMED;
nanos 表示超时时间;
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;;) { // restart on append race
for (Node h = head, p = h; p != null;) { // find & match first node
boolean isData = p.isData;
Object item = p.item;
if (item != p && (item != null) == isData) { // unmatched
if (isData == haveData) // can't match
break;
if (p.casItem(item, e)) { // match
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.<E>cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
if (how != NOW) { // No matches available
if (s == null)
s = new Node(e, haveData);
Node pred = tryAppend(s, haveData);
if (pred == null)
continue retry; // lost race vs opposite mode
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
死磕 java集合之LinkedTransferQueue源码分析 - xfer 方法解释的很清晰 https://zhuanlan.zhihu.com/p/64002492
Java多线程进阶(三八)—— J.U.C之collections框架:LinkedTransferQueue https://segmentfault.com/a/1190000016460411
LinkedTransferQueue的优点
LinkedTransferQueue 其实兼具了 SynchronousQueue 的特性以及无锁算法的性能,并且是一种无界队列: 和 SynchronousQueue 相比,LinkedTransferQueue 可以存储实际的数据; 和其它阻塞队列相比,LinkedTransferQueue 直接用无锁算法实现,性能有所提升。
LinkedTransferQueue使用示例
LinkedTransferQueue 的使用如下, 只要 transfer 的数据没有被 take() 或 poll() 取走,生产者线程就会一直阻塞
@Test
public void test() throws Exception {
LinkedTransferQueue<String> linkedTransferQueue = new LinkedTransferQueue<>();
Thread producerThread = new Thread(() -> {
try {
String data = "数据" + (int)(Math.random() * 100);
linkedTransferQueue.transfer(data);
// 只要 transfer 的数据没有被 take() 或 poll() 取走,生产者线程就会一直阻塞
System.out.println(Thread.currentThread() + "transfer 完成: " + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread consumerThread = new Thread(() -> {
try {
String data = linkedTransferQueue.take();
System.out.println(Thread.currentThread() + "取走: " + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
producerThread.start();
consumerThread.start();
// 主线程等待2个子线程执行完毕
producerThread.join();
consumerThread.join();
}
阻塞队列实现原理(Lock+Condition)
ArrayBlockingQueue 源码:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
final Object[] items; //存储元素的数组
int takeIndex; //队首元素指针,即下一次take,poll,peek,remove操作的元素索引
int putIndex; //队尾元素指针,即下一次put,offer,add操作的元素索引
int count; //队列中元素个数
final ReentrantLock lock;
private final Condition notEmpty; //不空条件,当队列为空时调用此条件的await方法等待此条件
private final Condition notFull; //不满条件,当队列满时调用此条件的await方法等待此条件
}
put() 方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
final E[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == items.length)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
insert(e);
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
从 put 方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用 notFull.await() 进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。 当数组不满或者当被其他线程唤醒时,通过 insert(e) 方法插入元素,插入成功后,通过 notEmpty 唤醒正在等待取元素的线程。
take()方法
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
E x = extract();
return x;
} finally {
lock.unlock();
}
}
private E extract() {
final E[] items = this.items;
E x = items[takeIndex];
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}
跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。
Java并发编程:阻塞队列 - 海子 http://www.cnblogs.com/dolphin0520/p/3932906.html
阻塞队列应用
生产者/消费者模式
使用阻塞队列实现的生产者-消费者模式,代码要简单得多,不需要再单独考虑同步和线程间通信的问题,这些阻塞队列都帮我们做了。 只要符合生产者-消费者模型的都可以使用阻塞队列。
public class ProducerConsumerBlockingQueue {
private BlockingQueue<String> blockingQueue;
private class Producer extends Thread {
@Override
public void run() {
while (true) {
try {
produce();
Thread.sleep((long)(Math.random() * 1000));
} catch (Exception e) {
e.printStackTrace();
}
}
}
void produce() throws Exception {
String element = "元素" + (int)(Math.random() * 100);
blockingQueue.put(element);
System.out.println("生产者放入 " + element + " [" + blockingQueue.size() + "]");
}
}
private class Consumer extends Thread {
@Override
public void run() {
while (true) {
try {
consume();
Thread.sleep((long)(Math.random() * 1000));
} catch (Exception e) {
e.printStackTrace();
}
}
}
void consume() throws Exception {
System.out.println("消费者取出 " + blockingQueue.take() + " [" + blockingQueue.size() + "]");
}
}
@Test
public void test() throws Exception {
blockingQueue = new LinkedBlockingDeque<>(10);
Producer producer = new Producer();
Consumer consumer = new Consumer();
producer.start();
consumer.start();
// 主线程等待生产者和消费组执行结束
producer.join();
consumer.join();
}
}
资源池commons-pool实现
资源池化相关内容参考笔记 Apache-Commons-Pool
ScheduledThreadPoolExecutor(定时任务)
ThreadPoolExecutor,它可另行安排在给定的延迟后运行命令,或者定期执行命令。
调度线程池主要用于定时器或者延迟一定时间再执行任务时候使用。内部使用优化的 DelayQueue 来实现,由于使用队列来实现定时器,有出入队调整堆等操作,所以定时并不是非常非常精确。
我们通过查看ScheduledThreadPoolExecutor的源代码,可以发现ScheduledThreadPoolExecutor的构造器都是调用父类的构造器,只是它使用的工作队列是java.util.concurrent.ScheduledThreadPoolExecutor.DelayedWorkQueue通过名字我们都可以猜到这个是一个延时工作队列.
因为ScheduledThreadPoolExecutor的最大线程是Integer.MAX_VALUE,而且根据源码可以看到execute和submit其实都是调用schedule这个方法,而且延时时间都是指定为0,所以调用execute和submit的任务都直接被执行.
用法示例
@Test
public void sssss() throws Exception {
new ScheduledThreadPoolExecutor(1, runnable -> {
Thread thread = new Thread(runnable, "current-time-millis");
thread.setDaemon(true);
return thread;
}).scheduleAtFixedRate(() -> {
System.out.println(Thread.currentThread().getName() + " " + System.currentTimeMillis());
}, 1, 1, TimeUnit.MILLISECONDS);
Thread.sleep(100000);
}
(二十)java多线程之ScheduledThreadPoolExecutor http://blog.csdn.net/tianshi_kco/article/details/53026196
Timer和TimerTask执行定时任务
Timer是java.util包下的一个类,在JDK1.3的时候被引入,Timer只是充当了一个调度者的角色,真正的任务逻辑是通过一个叫做TimerTask的抽象类完成的,TimerTask也是java.util包下面的类,它是一个实现了Runnable接口的抽象类,包含一个抽象方法run( )方法,需要我们自己去提供具体的业务实现。 Timer类对象是通过其schedule方法执行TimerTask对象中定义的业务逻辑,并且schedule方法拥有多个重载方法提供不同的延迟与周期性服务。
schedule(TimerTask task,long delay,long period) 安排指定的任务从指定的延迟后开始进行重复的固定延迟执行。以近似固定的时间间隔(由指定的周期分隔)进行后续执行。
ScheduledThreadPoolExecutor和Timer对比
单线程 Timer类是通过单线程来执行所有的TimerTask任务的,如果一个任务的执行过程非常耗时,将会导致其他任务的时效性出现问题。而ScheduledThreadPoolExecutor是基于线程池的多线程执行任务,不会存在这样的问题。
Timer线程不捕获异常 Timer类中是不捕获异常的,假如一个TimerTask中抛出未检查异常,Timer类将不会处理这个异常而产生无法预料的错误。这样一个任务抛出异常将会导致整个Timer中的任务都被取消,此时已安排但未执行的TimerTask也永远不会执行了,新的任务也不能被调度(所谓的“线程泄漏”现象)。
基于绝对时间 Timer类的调度是基于绝对的时间的,而不是相对的时间,因此Timer类对系统时钟的变化是敏感的,举个例子,加入你希望任务1每个10秒执行一次,某个时刻,你将系统时间提前了6秒,那么任务1就会在4秒后执行,而不是10秒后。在ScheduledThreadPoolExecutor,任务的调度是基于相对时间的,原因是它在任务的内部存储了该任务距离下次调度还需要的时间
基于以上3个弊端,在JDK1.5或以上版本中,我们几乎没有理由继续使用Timer类,ScheduledThreadPoolExecutor可以很好的去替代Timer类来完成延迟周期性任务。
Timer与ScheduledThreadPoolExecutor http://blog.csdn.net/diaorenxiang/article/details/38827409
深入理解Java线程池:ScheduledThreadPoolExecutor https://www.jianshu.com/p/925dba9f5969
Lock
从Java 5之后,在java.util.concurrent.locks包下提供了比synchronized关键字更优秀的线程间同步方式:Lock
不可不说的Java“锁”事 - 美团技术团队 https://tech.meituan.com/2018/11/15/java-lock.html
锁的相关概念
乐观锁/悲观锁
乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。
对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。 Java中,synchronized 关键字和 Lock 的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。 乐观锁在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。
可重入锁
可重入锁指的是在一个线程中可以多次获取同一把锁,比如: 一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法,而无需重新获得锁; 举个简单的例子,当一个线程执行到某个synchronized方法时,比如说method1,而在method1中会调用另外一个synchronized方法method2,此时线程不必重新去申请锁,而是可以直接执行方法method2。 synchronized和ReentrantLock都是可重入锁。
可中断锁
可中断锁:顾名思义,就是可以响应中断的锁。 在Java中,synchronized就不是可中断锁,而Lock是可中断锁。 如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。 lockInterruptibly()的用法时已经体现了Lock的可中断性。
公平锁
公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该所,这种就是公平锁。 非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。 在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。 而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。 ReentrantLock的构造方法有个参数ReentrantLock(boolean fair),如果参数为true表示为公平锁,为fasle为非公平锁。默认情况下,如果使用无参构造器,则是非公平锁。
读写锁
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。 正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突。 ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。 可以通过readLock()获取读锁,通过writeLock()获取写锁。
Java并发编程:Lock - 海子 https://www.cnblogs.com/dolphin0520/p/3923167.html
可重入锁和不可重入锁(自己设计可重入锁) https://www.cnblogs.com/dj3839/p/6580765.html
Lock接口提供的几种加锁方式
Java并发编程:Lock - 海子 https://www.cnblogs.com/dolphin0520/p/3923167.html
在Lock接口中声明了四个方法来获取锁:lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()。还有个unLock()方法是用来释放锁的。
lock()阻塞
lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已被其他线程获取,则进行等待。 通常使用Lock来进行同步的话,是以下面这种形式去使用的:
Lock lock = ...;
lock.lock();
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
tryLock()立即(或等待超时后)返回true/false
tryLock() 方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,也就说这个方法无论如何都会立即返回。在拿不到锁时不会一直在那等待。
tryLock(long time, TimeUnit unit) 方法和 tryLock() 方法是类似的,只不过区别在于这个方法在拿不到锁时会等待一定的时间,在时间期限之内如果还拿不到锁,就返回false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
所以,一般情况下通过tryLock来获取锁时要判断tryLock的返回值:
Lock lock = ...;
if(lock.tryLock()) {
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则直接做其他事情
}
lockInterruptibly()等待时可被中断
lockInterruptibly() 方法比较特殊,当通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程的等待状态。也就使说,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程。
注意,当一个线程获取了锁之后,是不会被interrupt()方法中断的。因为本身在前面的文章中讲过单独调用interrupt()方法不能中断正在运行过程中的线程,只能中断阻塞过程中的线程。
AbstractQueuedSynchronizer(AQS)队列同步器
AQS, AbstractQueuedSynchronizer,即队列同步器。它是构建锁或者其他同步组件的基础框架,如 ReentrantLock, ReentrantReadWriteLock, Semaphore, Conditon, CountDownLatch, BlockingQueue 实现原理是 ReentrantLock + Conditon 而这两者的实现原理都是 AQS
它是JUC并发包中的核心基础组件。
AbstractQueuedSynchronizer 是个抽象类,主要使用方式是继承,子类通过继承同步器并实现它的抽象方法来管理同步状态。
AQS的设计模式采用的 模板方法模式,子类通过继承的方式,实现它的抽象方法来管理同步状态,对于子类而言它并没有太多的活要做,AQS提供了大量的模板方法来实现同步,主要是分为三类:独占式获取和释放同步状态、共享式获取和释放同步状态、查询同步队列中的等待线程情况。
AQS模型如下图:
AQS模型
volatile int state同步状态
AQS使用一个int类型的成员变量state来表示同步状态
private volatile int state;
当 state > 0 时表示已经获取了锁,当 state = 0 时表示释放了锁。
它提供了三个方法 getState()、setState(int newState)、compareAndSetState(int expect, int update) 来对同步状态state进行操作,当然AQS可以确保对state的操作是安全的。
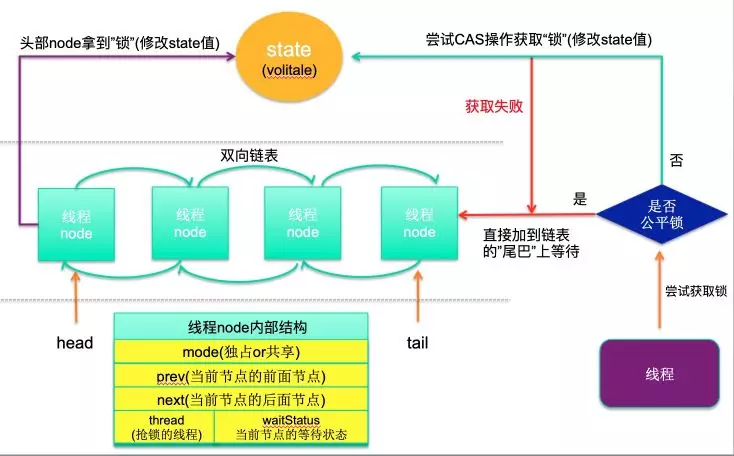
FIFO队列/CLH同步队列
AQS通过内置的FIFO同步队列来完成资源获取线程的排队工作,如果当前线程获取同步状态失败(锁)时,AQS则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
CLH同步队列是一个FIFO双向队列,AQS依赖它来完成同步状态的管理,当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
在CLH同步队列中,一个节点 Node 表示一个线程,它保存着线程的引用(thread)、状态(waitStatus)、前驱节点(prev)、后继节点(next),其定义如下:
Node 是 AbstractQueuedSynchronizer 的静态内部类
static final class Node {
//用于标识共享锁
static final Node SHARED = new Node();
//用于标识独占锁
static final Node EXCLUSIVE = null;
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
...
}
CLH同步队列结构图如下:
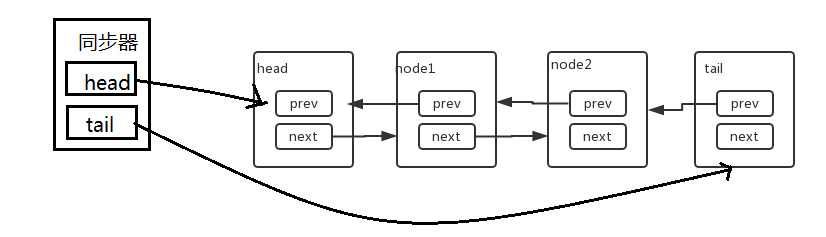
AQS中的FIFO队列
AQS常用方法
acquire(int arg)
独占式获取同步状态,如果当前线程获取同步状态成功,则由该方法返回,否则,将会进入同步队列等待,该方法将会调用可重写的 tryAcquire(int arg) 方法;
tryAcquire(int arg)
独占式获取同步状态,获取同步状态成功后,其他线程需要等待该线程释放同步状态才能获取同步状态
release(int arg)
独占式释放同步状态,该方法会在释放同步状态之后,将同步队列中第一个节点包含的线程唤醒;
acquireShared(int arg)
共享式获取同步状态,如果当前线程未获取到同步状态,将会进入同步队列等待,与独占式的主要区别是在同一时刻可以有多个线程获取到同步状态;
tryAcquireShared(int arg)
共享式获取同步状态,返回值大于等于0则表示获取成功,否则获取失败;
releaseShared(int arg)
共享式释放同步状态;
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state;
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
}
【死磕Java并发】—–J.U.C之AQS(一篇就够了) https://mp.weixin.qq.com/s/-swOI_4_cxP5BBSD9wd0lA
ReentrantLock
ReentrantLock 从字面可以看出是一把可重入锁,这点和 synchronized 一样,但实现原理也与 syncronized 有很大差别,它是基于经典的 AQS(AbstractQueueSyncronized) 实现的, AQS 是基于 volitale 和 CAS 实现的,其中 AQS 中维护一个 valitale 类型的变量 state 来做一个可重入锁的重入次数,加锁和释放锁也是围绕这个变量来进行的。 ReentrantLock 也提供了一些 synchronized 没有的特点,因此比 synchronized 好用。
ReentrantLock(重入锁)是jdk的concurrent包提供的一种独占锁的实现。它继承自Dong Lea的 AbstractQueuedSynchronizer 同步器,确切的说是ReentrantLock的一个内部类 Sync 继承了AbstractQueuedSynchronizer,ReentrantLock只不过是代理了该类的一些方法,可能有人会问为什么要使用内部类在包装一层? 我想是安全的关系,因为AbstractQueuedSynchronizer中有很多方法,还实现了共享锁,Condition(稍候再细说)等功能,如果直接使ReentrantLock继承它,则很容易出现AbstractQueuedSynchronizer中的API被吴用的情况。
ReentrantLock实现原理分析
ReentrantLock 中有个抽象类 Sync 继承自 AbstractQueuedSynchronizer AQS 队列同步器
又有两个 Sync 类的具体实现,一个是公平sync FairSync ,一个是非公平sync NonfairSync
提供两个构造方法,默认构造非公平锁,也可以指定构造公平锁,构造非公平锁时实例化的是 NonfairSync 类,构造公平锁时实例化的是 FairSync 类
阻塞加锁方法 lock() 是通过 AQS 的 acquire() 方法实现的,过程如下:
acquire 方法目的是为了独占式获取同步状态,源码如下,这是个模板方法,AQS本身并没有实现 tryAcquire 方法,需要子类自己取实现
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
如果 tryAcquire 成功返回 true,acquire 方法立即结束,加锁的线程可继续向下走。
如果 tryAcquire 失败返回 false,执行 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 也就是将当前线程加入等待此状态的同步队列尾部。
acquireQueued 中是一个死循环(也就是自旋),只有当前线程获取同步状态成功后才能返回,这就是为什么加锁线程会阻塞
selfInterrupt 的代码就一行 Thread.currentThread().interrupt(); 目的是为了当前线程获得锁后把自己唤醒。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
ReentrantLock 源码框架如下:
public class ReentrantLock implements Lock, java.io.Serializable {
private final Sync sync;
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
public void lock() {
sync.lock();
}
abstract static class Sync extends AbstractQueuedSynchronizer {
}
static final class NonfairSync extends Sync {
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
static final class FairSync extends Sync {
final void lock() {
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
}
ReentrantLock如何实现可重入?
lock 加锁过程中调用了 AQS 实现类的 tryAcquire(1) 方法,其中如果状态为已经被设置为 1 时,会先获取当前线程对象
Thread current = Thread.currentThread();
然后和当前持有同步状态的线程对象(通过 getExclusiveOwnerThread 方法获得)做比较
if (current == getExclusiveOwnerThread())
如果相同的话,直接返回加锁成功。
支持设置锁的超时时间
synchronized 关键字无法设置锁的超时时间,如果一个获得锁的线程内部发生死锁,那么其他线程就会一直进入阻塞状态,而 ReentrantLock 提供 tryLock 方法,允许设置线程获取锁的超时时间,如果超时,则跳过,不进行任何操作,避免死锁的发生。
支持公平/非公平锁
synchronized 关键字是一种非公平锁,先抢到锁的线程先执行。 而 ReentrantLock 的构造方法中允许设置 true/false 来实现公平、非公平锁,如果设置为 true ,则线程获取锁要遵循"先来后到"的规则,每次都会构造一个线程 Node ,然后到双向链表的"尾巴"后面排队,等待前面的 Node 释放锁资源。
ReentrantLock 的构造方法提供了一个 boolean 类型参数标识是否公平锁,默认是非公平锁
ReentrantLock unfairReentrantLock = new ReentrantLock(); // 默认是非公平锁
ReentrantLock fairReentrantLock = new ReentrantLock(true); // 公平锁
ReentrantLock如何实现公平/非公平?
ReentrantLock 中有个抽象类 Sync 继承自 AbstractQueuedSynchronizer AQS 队列同步器
又有两个 Sync 类的具体实现,一个是公平sync FairSync ,一个是非公平sync NonfairSync
比较下这两个 AQS 的实现类对 lock 方法的实现就知道了
NonfairSync 的 lock 方法如下,上来先直接 CAS 1 状态,也就是直接抢占获取锁,获取不到才排队获取。
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
FairSync 的 lock 方法如下,直接排队获取,没有抢占那一步
final void lock() {
acquire(1);
}
可中断锁
ReentrantLock 中的 lockInterruptibly() 方法使得线程可以在被阻塞时响应中断,比如一个线程 t1 通过 lockInterruptibly() 方法获取到一个可重入锁,并执行一个长时间的任务,另一个线程通过 interrupt() 方法就可以立刻打断 t1 线程的执行,来获取t1持有的那个可重入锁。而通过 ReentrantLock 的 lock() 方法或者 Synchronized 持有锁的线程是不会响应其他线程的 interrupt() 方法的,直到该方法主动释放锁之后才会响应 interrupt() 方法。
轻松学习java可重入锁(ReentrantLock)的实现原理 https://blog.csdn.net/yanyan19880509/article/details/52345422
ReadWriteLock
ReadWriteLock 维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
ReadWriteLock也是一个接口,在它里面只定义了两个方法: Lock readLock(); //获取读锁 Lock writeLock(); //获取写锁
不过要注意的是,如果有一个线程已经占用了读锁,则此时其他线程如果要申请写锁,则申请写锁的线程会一直等待释放读锁。 如果有一个线程已经占用了写锁,则此时其他线程如果申请写锁或者读锁,则申请的线程会一直等待释放写锁。 即只有无写锁时读锁间可以同时申请。
如果是排他锁(可重入锁)的话,一个线程加锁后(不论读还是写)另一个线程都不能再加锁(不论读还是写) 如果是读写锁(共享锁)的话,一个线程加读锁后其他线程可加读锁但不能加写锁,一个线程加写锁的话其他线程不能再加任何锁。即读读可并发,读写不可并发。
Java并发编程:Lock - 海子 https://www.cnblogs.com/dolphin0520/p/3923167.html
ReentrantReadWriteLock
ReadWriteLock接口的唯一实现类
Condition
Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition1的await()、signal()这种方式实现线程间协作更加安全和高效。因此通常来说比较推荐使用Condition,阻塞队列实际上是使用了Condition来模拟线程间协作。
Condition是个接口,基本的方法就是await()和signal()方法;
Condition依赖于Lock接口,生成一个Condition的基本代码是 lock.newCondition()
调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用
Conditon中的await()对应Object的wait();阻塞当前线程并释放锁。 Condition中的signal()对应Object的notify();唤醒一个等待线程。 Condition中的signalAll()对应Object的notifyAll()。唤醒所有等待线程。
package java.util.concurrent.locks;
public interface Condition {
void await() throws InterruptedException;
void awaitUninterruptibly();
long awaitNanos(long nanosTimeout) throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
}
Java并发编程:线程间协作的两种方式:wait、notify、notifyAll和Condition http://www.cnblogs.com/dolphin0520/p/3920385.html
怎么理解Condition http://www.importnew.com/9281.html
Condition实现原理(AQS同步队列)
ConditionObject 是同步器 AbstractQueuedSynchronizer 的内部类,因为 Condition 的操作需要获取相关联的锁,所以作为同步器的内部类也较为合理。每个 Condition 对象都包含着一个队列,该队列是Condition对象实现等待/通知功能的关键。
等待队列是一个FIFO的队列,在队列中的每个节点都包含了一个线程引用,该线程就是在Condition对象上等待的线程,如果一个线程调用了Condition.await()方法,那么该线程将会释放锁、构造成节点加入等待队列并进入等待状态
等待 调用Condition的await()方法(或者以await开头的方法),会使当前线程进入等待队列并释放锁,同时线程状态变为等待状态。当从await()方法返回时,当前线程一定获取了Condition相关联的锁。如果从队列(同步队列和等待队列)的角度看await()方法,当调用await()方法时,相当于同步队列的首节点(获取了锁的节点)移动到Condition的等待队列中
通知 调用Condition的signal()方法,将会唤醒在等待队列中等待时间最长的节点(首节点),在唤醒节点之前,会将节点移到同步队列中
创建 Condition 要现有 Lock 锁
ReentrantLock lock = new ReentrantLock(true);
Condition notEmpty = lock.newCondition();
Condition notFull = lock.newCondition();
Java多线程Condition接口原理详解 https://blog.csdn.net/fuyuwei2015/article/details/72602182
Condition和wait/notify区别
Condition它更强大的地方在于:能够更加精细的控制多线程的休眠与唤醒。 对于同一个锁,我们可以创建多个Condition,就是多个监视器的意思。在不同的情况下使用不同的Condition。
Object中的wait(),notify(),notifyAll()方法是和"同步锁"(synchronized关键字)捆绑使用的;而Condition是需要与"互斥锁"/"共享锁"捆绑使用的。
java的Condition 加强版的wait notify http://huangyunbin.iteye.com/blog/2181493
用Condition实现生产者消费者模式
官方jdk api文档Condition接口中给出的使用示例。
作为一个示例,假定有一个绑定的缓冲区,它支持 put 和 take 方法。如果试图在空的缓冲区上执行 take 操作,则在某一个项变得可用之前,线程将一直阻塞;如果试图在满的缓冲区上执行 put 操作,则在有空间变得可用之前,线程将一直阻塞。我们喜欢在单独的等待 set 中保存 put 线程和 take 线程,这样就可以在缓冲区中的项或空间变得可用时利用最佳规划,一次只通知一个线程。可以使用两个 Condition 实例来做到这一点。
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
Lock锁和synchronized关键字异同点
1)synchronized是Java语言的关键字,因此是内置特性。Lock是一个类,通过这个类可以实现同步访问; 2)Lock和synchronized有一点非常大的不同,采用synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。 synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁; 3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断; 4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。 5)Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
ReenTrantLock可重入锁(和synchronized的区别)总结 https://www.cnblogs.com/baizhanshi/p/7211802.html
Java并发编程:Lock - 海子 https://www.cnblogs.com/dolphin0520/p/3923167.html
CAS/Atomic/Unsafe
CAS(Compare And Swap)
CAS,Compare And Swap,比较并设置,或比较并交换。
CAS机制简介
CAS 操作中包含三个操作数:需要读写的内存地址V、旧的预期值A、拟写入的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。 如果内存位置V的值与预期原值A相等,那么处理器会自动将该位置值更新为新值B。否则处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值)。 CAS机制的意思是:我认为位置 V 应该是值A;如果确实是该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。
CAS用于在硬件层面上提供原子性操作。当前的处理器基本都支持CAS,只不过不同的厂家的实现不一样罢了。在 Intel 处理器中,比较并交换通过指令cmpxchg实现。比较是否和给定的数值一致,如果一致则修改,不一致则不修改。
CAS是一种乐观锁。
Java中的CAS(Java中对乐观锁的实现)
java.util.concurrent.atomic 包下的原子操作类都是基于CAS实现的,而CAS就是一种乐观锁。
CAS的底层实现(CPU的cmpxchg指令地址总线加锁)
JDK 中 CAS 的 API 都封装在 sun.misc.Unsafe 这个类中。接下来进入 openjdk 中对应的方法,
对应的源码文件是
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/prims/unsafe.cpp
UNSAFE_ENTRY(jint, Unsafe_CompareAndExchangeInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) {
oop p = JNIHandles::resolve(obj);
if (p == NULL) {
volatile jint* addr = (volatile jint*)index_oop_from_field_offset_long(p, offset);
return RawAccess<>::atomic_cmpxchg(addr, e, x);
} else {
assert_field_offset_sane(p, offset);
return HeapAccess<>::atomic_cmpxchg_at(p, (ptrdiff_t)offset, e, x);
}
} UNSAFE_END
p 是取出的对象,addr 是 p 中 offset 处的地址,最后调用了 atomic_cmpxchg(addr, e, x), 其中 addr 是要操作的内存地址,x 是即将更新的值,参数 e 是原内存的值。
atomic_cmpxchg 有基于各个平台的实现,看看 x86 的实现
源码文件
https://github.com/openjdk/jdk/blob/master/src/hotspot/os_cpu/linux_x86/atomic_linux_x86.hpp
如果当前系统是多核系统,就给总线加锁,所以同一芯片上的其他处理器就暂时不能通过总线访问内存,保证了该指令在多处理器环境下的原子性。
最终,JDK 通过 CPU 的 cmpxchgl 指令的支持,实现 AtomicInteger 的 CAS 操作的原子性。
CAS缺点
CAS的缺点: 1、CPU开销较大 在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。 2、不能保证代码块的原子性 CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。 3.ABA问题 这是CAS机制最大的问题所在。
ABA问题
尽管CAS看起来很美,但显然这种操作无法涵盖互斥同步的所有使用场景,并且CAS从语义上来说并不是完美的,存在这样的一个逻辑漏洞:如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然为A值,那我们就能说它的值没有被其他线程改变过了吗?如果在这段期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。这个漏洞称为CAS操作的“ABA”问题。
ABA问题举例: 假设有一个遵循CAS原理的提款机,我现在有10元,打算取出来5元,取钱线程由于某种原因阻塞了,这时我妈给我打了5元,余额为15元,又有一个线程从我账户扣款5元,余额为10元。然后取钱线程继续执行,compare and set的时候一看原值是10元,就认为没问题,更新账户余额为5元。其实整个过程中我损失5元。
漫画:什么是CAS机制?(进阶篇) https://blog.csdn.net/bjweimengshu/article/details/79000506
漫画:什么是 CAS 机制? - 程序员小灰 https://blog.csdn.net/bjweimengshu/article/details/78949435
CAS与synchronized对比
从思想上来说,Synchronized属于悲观锁,悲观地认为程序中的并发情况严重,所以严防死守。CAS属于乐观锁,乐观地认为程序中的并发情况不那么严重,所以让线程不断去尝试更新。
CAS与Synchronized的使用情景: 1、对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。 2、对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
补充: synchronized在jdk1.6之后,已经改进优化。synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
Java并发问题--乐观锁与悲观锁以及乐观锁的一种实现方式-CAS https://www.cnblogs.com/qjjazry/p/6581568.html
Atomic 原子操作类
所谓原子操作类,指的是java.util.concurrent.atomic包下,一系列以Atomic开头的包装类。例如AtomicBoolean,AtomicInteger,AtomicLong。它们分别用于Boolean,Integer,Long类型的原子性操作。
AtomicInteger 增加到溢出后变为负值
AtomicInteger idx = new AtomicInteger(2147483647);
log.info("idx {}, idx % 10 {}", idx.get(), idx.getAndIncrement() % 10);
log.info("idx {}, idx % 10 {}", idx.get(), idx.getAndIncrement() % 10);
log.info("idx {}, idx % 10 {}", idx.get(), idx.getAndIncrement() % 10);
log.info("idx {}, idx % 10 {}", idx.get(), idx.getAndIncrement() % 10);
结果: idx 2147483647, idx % 10 7 idx -2147483648, idx % 10 -8 idx -2147483647, idx % 10 -7 idx -2147483646, idx % 10 -6
原子操作实现原理(Unsafe类提供的CAS)
以AtomicInteger为例,jdk8中源码如下:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();//获取Unsafe类
private static final long valueOffset; //value值的内存偏移(内存地址)
//静态初始化,获取value的内存偏移
static {
try {
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value; //存储int值的变量,volatile保证当前值是内存中的最新值(可见性)
public AtomicInteger(int initialValue) {
value = initialValue;
}
//以原子方式将当前值加,返回以前的值
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
//以原子方式将当前值加,返回更新的值
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
...
}
原子类内部使用了 Unsafe 类进行原子操作
什么是unsafe呢?Java语言不像C,C++那样可以直接访问底层操作系统,但是JVM为我们提供了一个后门,这个后门就是unsafe。unsafe为我们提供了硬件级别的原子操作。
至于valueOffset对象,是通过unsafe.objectFieldOffset方法得到,所代表的是AtomicInteger对象value成员变量在内存中的偏移量。我们可以简单地把valueOffset理解为value变量的内存地址。
Unsafe类的getAndAddInt()方法源码(jdk1.8): var1:当前AtomicInteger对象 var2:内存地址或内存偏移量valueOffset var4:要增加的值(自增1的话就是1)
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);//根据当前AtomicInteger对象和内存偏移量获取旧值,放到var5中
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));//CAS自旋(无限循环)不断尝试更新
return var5;
}
//native方法compareAndSwapInt()
//var1:当前对象,var2:内存地址,var4:预期的旧值,var5:拟更新的新值
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
可以看到Unsafe类的getAndAddInt()方法是一个无限循环,也就是CAS的自旋,循环体当中做了以下几件事: 1、根据当前AtomicInteger对象和内存偏移量valueOffset获取旧值 2、调用compareAndSwapInt()不断尝试更新为新值,如果成功则跳出循环,若失败则不断重复
其中Unsafe类的compareAndSwapInt()方法就是一个CAS原子操作, 内部利用JNI(Java Native Interface)来完成CPU指令的操作:
AtomicStampedReference(解决ABA问题,加版本号)
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
如果当前引用 == 预期引用,并且当前标志等于预期标志,则以原子方式将该引用和该标志的值设置为给定的更新值。
聊聊并发(五)原子操作的实现原理 - 方 腾飞 http://ifeve.com/atomic-operation/
LongAdder
在高并发的情况下,我们对一个 Integer 类型的整数直接进行 i++ 的时候,无法保证操作的原子性,会出现线程安全的问题。
为此我们会用 juc 包下的 AtomicInteger 它是一个提供原子操作的 Integer 类,内部也是通过 CAS 实现线程安全的。
但当大量线程同时去访问时,就会因为大量线程执行 CAS 操作失败而进行空旋转,导致 CPU 资源消耗过多,而且执行效率也不高。
Doug Lea 大神应该也不满意,于是在 JDK1.8 中对 CAS 进行了优化,提供了 LongAdder 它是基于了 CAS 分段锁的思想实现的。
在高并发的情况下,多个线程同时对一个整数进行累加操作,如果使用 AtomicLong 类,虽然 AtomicLong 的自增操作是原子的,但是在高并发的情况下,多个线程同时进行累加操作,会因为CAS操作导致大量的自旋重试,从而影响性能。
LongAdder 类的设计主要是为了解决这个问题,它内部使用一个或多个变量来维护当前的总和,当多个线程进行累加操作时,这些操作会被分散到不同的变量上,从而减少线程之间的争用,提高并发性能。当需要获取总和时,再将这些变量的值累加起来。
LongAdder 提供了如下主要方法:
add(long x) 将给定值累加到总和上。
increment() 将总和增加1,等同于add(1)
decrement() 将总和减少1,等同于add(-1)
sum() 返回当前的总和
reset() 将总和重置为0
sumThenReset() 返回当前的总和,然后将总和重置为0
从 LongAdder 中窥见并发组件的设计思路 https://xilidou.com/2018/11/27/LongAdder/
LockSupport
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。和 CAS 一样,LockSupport 底层使用 Unsafe 实现。
LockSupport 中最重要的就是 park() 和 unpark() 方法,park() 阻塞当前线程,unpark() 唤醒被阻塞的线程。
LockSupport 和每个使用它的线程都与一个许可(permit)关联。permit 相当于 1,0 的开关,默认是 0, 调用一次 unpark 就加 1 变成 1, 调用一次 park 会消费 permit 也就是将 1 变成 0, 同时 park 立即返回。permit 变为 0 后,再次调用 park 会阻塞当前线程,直到 permit 变为 1. 注意是每个线程都有一个自己的 permit, permit 最多只有一个,重复调用 unpark 也不会积累。
park 阻塞当前线程
public static void park() {
UNSAFE.park(false, 0L);
}
public static void parkNanos(long nanos) {
if (nanos > 0)
UNSAFE.park(false, nanos);
}
park() 阻塞当前线程。
parkNanos(long nanos) 阻塞当前线程,最长不超过 nanos 纳秒。
如果 permit 可用(即值为 1),消耗掉此 permit 并立即返回。否则当前线程被阻塞,直到下面三种情况发生:
1、其他线程调用 unpark() 方法唤醒当前线程,也就是用当前线程作为入参。
2、其他线程 interrupt() 中断当前线程。
3、park() 方法毫无理由的返回
注意 park() 方法不会报告是上述哪个原因引起方法返回的,调用方需要自己检查。
unpark 唤醒目标线程
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
}
unpark() 唤醒被阻塞的线程。
unpark() 使目标线程的 permit 变为 1. 如果此时目标线程处于阻塞状态则会被唤醒,如果此时目标线程非阻塞状态,可保证目标线程下次调用 park() 方法时可立即返回而不被阻塞。
blocker
从 java6 开始 park 系列方法新增加了入参 Object blocker 用于标识阻塞对象,该对象主要用于问题排查和系统监控。 当 dump 导出线程时,有 blocker 的可以传递给开发人员更多的现场信息,可以查看到当前线程的阻塞对象,方便定位问题。
浅谈Java并发编程系列(八)—— LockSupport原理剖析 https://segmentfault.com/a/1190000008420938
synchronized 关键字
聊聊 Java 的几把 JVM 级锁 - 阿里巴巴中间件公众号 https://mp.weixin.qq.com/s/h3VIUyH9L0v14MrQJiiDbw
不可不说的Java“锁”事 - 美团技术团队 https://tech.meituan.com/2018/11/15/java-lock.html
synchronized是Java中的关键字,是一种同步锁。 在加了 syncronized 关键字的方法、代码块中,一次只允许一个线程进入特定代码段,从而避免多线程同时修改同一数据。
它修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
- 修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
- 修饰一个类,其作用范围是 synchronized 后面括号括起来的部分,作用的对象是这个类的所有对象。
1)当一个线程正在访问一个对象的synchronized方法,那么其他线程不能访问该对象的其他synchronized方法。这个原因很简单,因为一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程无法获取该对象的锁,所以无法访问该对象的其他synchronized方法。
2)当一个线程正在访问一个对象的synchronized方法,那么其他线程能访问该对象的非synchronized方法。这个原因很简单,访问非synchronized方法不需要获得该对象的锁,假如一个方法没用synchronized关键字修饰,说明它不会使用到临界资源,那么其他线程是可以访问这个方法的,
3)如果一个线程A需要访问对象object1的synchronized方法fun1,另外一个线程B需要访问对象object2的synchronized方法fun1,即使object1和object2是同一类型),也不会产生线程安全问题,因为他们访问的是不同的对象,所以不存在互斥问题。
synchronized 锁是加在对象上的
synchronized 非静态方法:当前调用此方法的实例对象
所有的非静态同步方法用的都是同一把锁——当前调用此方法的实例对象本身,也就是说如果一个实例对象的非静态同步方法获取锁后,该实例对象的其他非静态同步方法必须等待获取锁的方法释放锁后才能获取锁,可是别的实例对象的非静态同步方法因为跟该实例对象的非静态同步方法用的是不同的锁,所以毋须等待该实例对象已获取锁的非静态同步方法释放锁就可以获取他们自己的锁。
即
synchronized void method{} 功能上,等效于
void method{
synchronized(this) {
...
}
}
Java中每个对象都有一个内置锁 当程序运行到非静态的synchronized同步方法上时,自动获得与正在执行代码类的当前实例(this实例)有关的锁。获得一个对象的锁也称为获取锁、锁定对象、在对象上锁定或在对象上同步。 当程序运行到synchronized同步方法或代码块时才该对象锁才起作用。 一个对象只有一个锁。所以,如果一个线程获得该锁,就没有其他线程可以获得锁,直到第一个线程释放(或返回)锁。这也意味着任何其他线程都不能进入该对象上的synchronized方法或代码块,直到该锁被释放。
synchronized 静态方法的锁:当前类对象
而所有的静态同步方法用的也是同一把锁——方法所在的类对象本身(Class对象),这两把锁(之实例对象和类对象)是两个不同的对象,所以静态同步方法与非静态同步方法之间是不会有竞态条件的。但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁,而不管是同一个实例对象的静态同步方法之间,还是不同的实例对象的静态同步方法之间,只要它们同一个类的实例对象!
即:
synchronized static void method() 等效于
static void method{
synchronized(Obj.class)
}
}
静态同步方法和非静态同步方法将永远不会彼此阻塞,因为静态方法锁定在Class对象上,非静态方法锁定在该类的对象上。
synchronized 代码块的锁:括号中的对象
而对于同步块,由于其锁是可以选择的,所以只有使用同一把锁的同步块之间才有着竞态条件,这就得具体情况具体分析了。
对于同步代码块,要看清楚什么对象已经用于锁定(synchronized后面括号的内容)。在同一个对象上进行同步的线程将彼此阻塞,在不同对象上锁定的线程将永远不会彼此阻塞。
所以,如果synchronized代码块和synchronized方法的锁是同一个,他们之间也会互斥: synchronized(非this对象x)格式的写法是将x对象本身作为对象监视器,有三个结论得出: 1、当多个线程同时执行synchronized(x){}同步代码块时呈同步效果 2、当其他线程执行x对象中的synchronized同步方法时呈同步效果 3、当其他线程执行x对象方法中的synchronized(this)代码块时也呈同步效果 因为他们申请的锁都是对象x这个实例
java 多线程9 : synchronized锁机制 之 代码块锁 synchronized同步代码块 https://www.cnblogs.com/signheart/p/0a8548258725cb8812768d2b3e1a2aef.html
synchronized常见面试题(分析申请的锁是什么)
1、问:一个类中两个方法上分别有synchronized,两个线程分别调用这两个方法,会阻塞吗? 答:普通方法的锁是实例对象,那这个问题得先确认下是不是通过同一个对象调用的,如果通过同一个对象调用,会阻塞;如果通过不同对象调用,不会阻塞。 比如一个自定义Runnable对象,里面有两个synchronized方法,把同一个Runnable对象分别传给两个Thread,两个线程中分别调用这两个方法,则他们之间会有竞争关系,因为申请的锁是同一个。但如果把两个不同的Runnable实例分别传给两个thread,则不会有竞争。
2、问:类中有个synchronized静态方法和一个synchronized非静态方法,两个线程同时访问,会存在竞争问题吗? 答:不会,占用的锁不同(这种题就首先分析他需要获取什么锁) 如果一个线程执行一个对象的非static synchronized方法,另外一个线程需要执行这个对象所属类的static synchronized方法,此时不会发生互斥现象,因为访问static synchronized方法占用的是类锁,而访问非static synchronized方法占用的是对象锁,所以不存在互斥现象。
3、问:类中有个synchronized静态方法,在两个线程中分别通过两个不同的对象调用此静态方法,会阻塞吗? 答:会,因为占用的锁是同一个锁,都是类对象本身。
4、问:使用如下两个对象 integer1 和 integer2 对同一个方法加锁,会有竞争吗? 如果使用 integer3 和 integer4 呢? 如果使用 integer1 和 integer3 呢?
Integer integer1 = new Integer(3);
Integer integer2 = new Integer(3);
Integer integer3 = 3;
Integer integer4 = 3;
答:
1、锁对象为 integer1 和 integer2 时没有竞争,是两个不同的对象。Integer 对 -128 到 127 之间整数的缓存只适用于自动装箱或者说 valueOf(int) 方法,通过构造方法构造的还是每次新创建实例。
2、锁对象为 integer3 和 integer4 时有竞争,Integer 对 -128 到 127 之间的整数在自动装箱时会直接从缓存实例池中取,所以是同一个对象。
3、锁对象为 integer1 和 integer3 时没有竞争,integer1 是新建对象, integer3 是从缓存池中取的对象,肯定是两个不同的实例。
同步块内部修改了同步对象 Synchronized块同步变量的误区 https://blog.csdn.net/magister_feng/article/details/6627523
使用synchronized需要注意的一个问题 https://blog.csdn.net/jimmylincole/article/details/17194337
Java并发编程:synchronized - 海子 http://www.cnblogs.com/dolphin0520/p/3923737.html
java synchronized静态同步方法与非静态同步方法,同步语句块 https://www.cnblogs.com/csniper/p/5478572.html
synchronized与Lock的区别
1、synchronized是关键字,Lock是一组类和接口 2、synchronized无法判断锁状态,会阻塞线程。Lock可判断锁状态,提供tryLock方法尝试获取锁 3、synchronized不需要手动释放锁。Lock需要释放锁。 4、synchronized在线程异常时会被系统自动释放掉,不会死锁。Lock必须在finally中手动释放锁,否则可能死锁。 5、synchronized和Lock都是可重入锁。 6、synchronized是非公平锁。Lock默认非公平,可设置为公平锁。 7、synchronized无法被中断。Lock提供可被中断的加锁方法。
详解synchronized与Lock的区别与使用 http://blog.csdn.net/u012403290/article/details/64910926?locationNum=11&fps=1
synchronized实现原理(监视器monitor)
synchronized 是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在 Java 对象头里的。
Java对象内存布局
Java 对象内存布局如下:
Java 对象内存布局
在创建一个对象后,在 JVM 虚拟机( HotSpot )中,Java 对象在内存中的存储布局可分为三块: 对象头、实例数据区域、对齐填充区域。
对象头
们以 Hotspot 虚拟机为例,Hotspot 的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。 1、Mark Word(标记字段): 默认存储对象的 HashCode,gc分代年龄、锁类型标记、偏向锁线程 ID 、 CAS 锁指向线程 LockRecord 的指针等。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。 synchronized 锁的机制与这个部分( markwork )密切相关,用 markword 中最低的三位代表锁的状态,其中一位是偏向锁位,另外两位是普通锁位。
2、Klass Point(类型指针): 对象指向它的类元数据的指针,虚拟机就是通过这个指针来确定这个对象是哪个类的实例。
实例数据区域
此处存储的是对象真正有效的信息,比如对象中所有字段的内容
对齐填充区域
JVM 的实现 HostSpot 规定对象的起始地址必须是 8 字节的整数倍,换句话来说,现在 64 位的 OS 往外读取数据的时候一次性读取 64bit 整数倍的数据,也就是 8 个字节,所以 HotSpot 为了高效读取对象,就做了"对齐",如果一个对象实际占的内存大小不是 8byte 的整数倍时,就"补位"到 8byte 的整数倍。所以对齐填充区域的大小不是固定的。
synchronized锁就是锁对象头里的标志位
synchronized使用的锁对象是存储在Java对象头里的,或者说,synchronized锁就是对象头里的标志位。
重量级锁也就是通常说synchronized的对象锁,锁标识位为10,其中指针指向的是monitor对象(也称为管程或监视器锁)的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如monitor可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。
锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。在32位虚拟机中,一字宽等于四字节,即32bit。
Java对象头里的Mark Word里默认存储对象的HashCode,分代年龄和锁标记位。
聊聊并发(二)Java SE1.6中的Synchronized http://ifeve.com/java-synchronized/
监视器monitor
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。
Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
现在话题回到synchronized,synchronized通过Monitor来实现线程同步,Monitor是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的线程同步。
如同我们在自旋锁中提到的“阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长”。这种方式就是synchronized最初实现同步的方式,这就是JDK 6之前synchronized效率低的原因。这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”,JDK 6中为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”。
在Java中,最基本的互斥同步手段就是synchronized关键字,synchronized关键字经过编译之后,会在同步块的前后分别形成 monitorenter和 monitorexit 这两个字节码指令,这两个字节码都需要一个reference类型的参数来指明要锁定和解锁的对象。如果Java程序中的synchronized明确指定了对象参数,那就是这个对象的reference;如果没有明确指定,那就根据synchronized修饰的是实例方法还是类方法,去取对应的对象实例或Class对象来作为锁对象。
从反编译获得的字节码可以看出,synchronized代码块实际上多了monitorenter和monitorexit两条指令。monitorenter指令执行时会让对象的锁计数加1,而monitorexit指令执行时会让对象的锁计数减1,其实这个与操作系统里面的PV操作很像,操作系统里面的PV操作就是用来控制多个线程对临界资源的访问。对于synchronized方法,执行中的线程识别该方法的 method_info 结构是否有 ACC_SYNCHRONIZED 标记设置,然后它自动获取对象的锁,调用方法,最后释放锁。如果有异常发生,线程自动释放锁。
java6对synchronized的优化
在 JDK1.6 之前, syncronized 是一把重量级的锁,不过随着 JDK 的升级,也在对它进行不断的优化,如今它变得不那么重了,甚至在某些场景下,它的性能反而优于轻量级锁。
JDK1.6提供了大量的锁优化技术,其中包括适应性自旋(Adaptive Spinning)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)和偏向锁(Biased Locking)等。通过使用这些方法对Synchronized进行了虚拟机级别的锁优化,从而提高了Synchronized的使用效率。
自旋锁和自适应自旋(盲等代替阻塞)
在进行互斥和同步时,互斥同步对性能最大的影响是阻塞的的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统的并发性能带来了很大的压力。自旋锁意味着,当存在两个或者两个以上的线程同时并行执行,让后面请求锁的线程“稍等下”,但是不放弃处理器执行时间,看看持有锁的线程是否很快的释放锁,此时我们让等待锁的线程执行一个忙循环(自旋)进行等待。这种让线程使用忙循环或者自旋的形式等待线程锁的技术就成为自旋锁。
自旋锁的理论基础在于,共享数据的锁定状态只会持续很短一段时间,故不需要为了这段时间去挂起和恢复线程。不过自旋等待虽然避免了线程切换的开销,但是它还是会占用处理器的时间,所以自旋的时间或者次数是有限的。
适应性自旋(Adaptive Spinning) 自适应自旋的自旋时间是不固定的,而是通过前一次在同一个锁上的自旋时间及锁得持有者的状态决定的。如果在同一个锁对象上,自旋等待刚刚成功获取过锁,且持有锁的线程正在运行,那么认为这次也成功获取锁的概率非常大,那么就允许自旋等待更长的时间来获取这个锁。如果对于某个锁,自旋很少成功,那么以后对于这个锁就省略掉自旋过程。
锁消除(单线程锁优化)
锁消除(Lock Elimination) 是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享竞争的锁进行消除。例如我们在单线程中使用Hashtable或者StringBuffer进行编程(它们中的大部分方法都是synchronized的),因为不存在锁竞争,所以这些同步方法上的同步就可以被自动消除。
锁粗化(防止频繁加解锁)
锁粗化(Lock Coarsening) 原则上我们写代码会尽量将同步块的作用范围限制在最小(只对共享数据进行同步)。但是如果一系列连续操作都对同一个对象反复加锁和解锁(类似于在循环体中使用synchronized),即使没有竞争,也会导致性能损失。那么将锁的范围扩展(粗化)到整个操作之外(类似于将synchronized放在循环体之外),这样就只需要一次加锁了。
锁升级(偏向->轻量->重量)
Java6中的锁一共有四种状态:无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它们会随着竞争情况逐渐升级,但是不能够降级。 锁升级的过程大概是这样的,刚开始处于无锁状态,当线程第一次申请时,会先进入偏向锁状态,然后如果出现锁竞争,就会升级为轻量级锁(这升级过程中可能会牵扯自旋锁),如果轻量级锁还是解决不了问题,则会进入重量级锁状态,从而彻底解决并发的问题。
当线程进入到 synchronized 处尝试获取该锁时, synchronized 锁升级流程如下:
synchronized 锁升级流程
锁升级过程中对象头 Mark Word 中的内容如下表格
| 锁状态 | 存储内容 | 存储内容 |
|---|---|---|
| 无锁 | 对象的hashCode、对象分代年龄、是否是偏向锁(0) | 01 |
| 偏向锁 | 偏向线程ID、偏向时间戳、对象分代年龄、是否是偏向锁(1) | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 10 |
偏向锁(无竞争时加锁后就不解锁)
偏向锁的目的是为了消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。偏向锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他线程获取,则持有偏向锁的线程永远不需要再进行同步。 更具体的过程是:当锁对象第一次被线程获取的时候,虚拟将将会把对象头中的标志位设置为“01”,即偏向模式,然后使用CAS操作将这个锁的线程ID记录在对象的Mark Word中,如果操作成功,则持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作。当另外一个线程尝试获取这个锁时,偏向锁模式宣告结束。根据对象当前是否处于锁定状态,将会进一步撤销偏向恢复未锁定状态(标志为“01”)或者进入轻量级锁定(状态为“00”)状态。 当只有一个线程即不存在竞争时,偏向锁用CAS操作把锁分配给线程后,就不再解锁,即使退出synchronized代码块也不解锁,直到有其他线程要获取此对象锁时才解锁并退出偏向锁模式
轻量级锁(CAS自旋)
当下一个线程参与到偏向锁竞争时,会先判断 markword 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。 每个线程在自己的线程栈中生成一个 LockRecord ( LR ),然后每个线程通过 CAS (自旋) 的操作将锁对象头中的 markwork 设置为指向自己的 LR 的指针,哪个线程设置成功,就意味着获得锁。
轻量级锁是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
轻量级锁加锁过程: 在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称这份拷贝为Displaced Mark Word,然后拷贝对象头中的Mark Word复制到锁记录中。 拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。 如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。 如果轻量级锁的更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明多个线程竞争锁。 若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
轻量级锁的解锁过程: (1)通过CAS操作尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word。 (2)如果替换成功,整个同步过程就完成了。 (3)如果替换失败,说明有其他线程尝试过获取该锁(此时锁已膨胀),那就要在释放锁的同时,唤醒被挂起的线程。
当只有一个线程即不存在竞争时,轻量级锁还是要加锁解锁的,只不过用CAS操作代替了锁,进入synchronized代码块的时候加锁,退出synchronized代码块的时候解锁
轻量级锁查cas自旋次数是多少?
适应性自旋(Adaptive Spinning) 从轻量级锁获取的流程中我们知道,当线程在获取轻量级锁的过程中执行CAS操作失败时,是要通过自旋来获取重量级锁的。问题在于,自旋是需要消耗CPU的,如果一直获取不到锁的话,那该线程就一直处在自旋状态,白白浪费CPU资源。解决这个问题最简单的办法就是指定自旋的次数,例如让其循环10次,如果还没获取到锁就进入阻塞状态。 但是JDK采用了更聪明的方式——适应性自旋,简单来说就是线程如果自旋成功了,则下次自旋的次数会更多,如果自旋失败了,则自旋的次数就会减少。
重量级锁(用户态/内核态切换)
如果锁竞争加剧(如线程自旋次数或者自旋的线程数超过某阈值, JDK1.6 之后,由 JVM 自己控制该规则),就会升级为重量级锁。 此时就会向操作系统申请资源,线程挂起,进入到操作系统内核态的等待队列中,等待操作系统调度,然后映射回用户态。在重量级锁中,由于需要做内核态到用户态的转换,而这个过程中需要消耗较多时间,也就是"重"的原因之一。
通俗理解 偏向锁 -> 轻量级锁 -> 重量级锁 升级过程? JVM 如何应对对象锁的各种场景? 重量级锁是最为基础、最为低效的对象锁实现。JVM 会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程。我们用等红灯作类比。Java 线程进入阻塞状态相当于熄火停车,再次点火启动必然耗费时间。JVM 会在进入阻塞状态之前进行自旋,也就是怠速停车。如果目标锁能够在短时间内被释放出来,该线程便能够不进入阻塞状态,直接获取该锁。
重量级锁针对的是多个线程同时竞争同一把锁的场景。在现实中,多个线程可能在不同时间段持有同一把锁。为了应对这种没有锁竞争的情况,JVM 采用了轻量级锁机制。在加锁时,JVM 将在锁对象处做标记,指向当前线程的栈上;在解锁时,上述标记会被清除。如果某线程在请求锁时,发现该锁为轻量级锁,并且指向另一线程所对应的栈,那么它会将该锁膨胀为重量级锁。
偏向锁所应对的场景则更为乐观:至始至终只有一个线程请求某把锁。JVM 采取的做法是在第一次加锁时为锁对象做标记,使其指向当前线程的地址;在解锁时则不做任何操作。如果下一次请求该锁的仍是同一线程,便直接跳过标记过程;否则,JVM 会将该锁膨胀为轻量级锁。
Java6中与Synchronized相关的锁机制 http://blog.csdn.net/teaandnoodle/article/details/52229258
聊聊并发(二)Java SE1.6中的Synchronized http://ifeve.com/java-synchronized/
synchronized实现原理 https://www.cnblogs.com/pureEve/p/6421273.html
volatile关键字
对于可见性,Java 提供了 volatile 关键字来保证可见性、有序性。但不保证原子性。 普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。 volatile 作用: 1、volatile 关键字对于基本类型的修改可以在随后对多个线程的读保持一致,但是对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性。。 2、禁止进行指令重排序。
关键字 volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制。一个变量被定义为 volatile 后,它将具备两种特性: 1、保证此变量对所有线程的"可见性",所谓"可见性"是指当一条线程修改了这个变量的值,新值对于其它线程来说都是可以立即得知的,而普通变量不能做到这一点,普通变量的值在在线程间传递均需要通过主内存来完成。 2、使用volatile变量的第二个语义是禁止指令重排序优化(访问volatile变量的语句不会被指令重排),普通变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。这点参见单例模式中的双重检测实现方式。
//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
3、volatile修饰的变量符合happens before原则,即对这个变量的写操作发生于读操作之前
总结一下Java内存模型对volatile变量定义的特殊规则: 1、在工作内存中,每次使用某个变量的时候都必须线从主内存刷新最新的值,用于保证能看见其他线程对该变量所做的修改之后的值。 2、在工作内存中,每次修改完某个变量后都必须立刻同步回主内存中,用于保证其他线程能够看见自己对该变量所做的修改。 3、volatile修饰的变量不会被指令重排序优化,保证代码的执行顺序与程序顺序相同。
volatile 关键字可以保证变量会直接从主存读取,而对变量的更新也会直接写到主存
Java并发编程:volatile关键字解析 - 海子 http://www.cnblogs.com/dolphin0520/p/3920373.html
volatile实现原理(内存屏障,缓存)
访问volatile变量的汇编指令前会多出一个lock前缀指令,
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能: 1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成; 2)它会强制将对缓存的修改操作立即写入主存; 3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
Java并发编程:volatile关键字解析 - 海子 http://www.cnblogs.com/dolphin0520/p/3920373.html
聊聊并发(一)深入分析Volatile的实现原理 http://ifeve.com/volatile/
理解 JMM:编写正确的并发 Java 程序(可见性, 重排序, happens-before) http://tech.nioint.com/Java-Memory-Model/
volatile保证可见性但不保证原子性
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
意思就是说,如果一个变量加了volatile关键字,就会告诉编译器和JVM的内存模型:这个变量是对所有线程共享的、可见的,每次jvm都会读取最新写入的值并使其最新值在所有CPU可见。volatile似乎是有时候可以代替简单的锁,似乎加了volatile关键字就省掉了锁。但又说volatile不能保证原子性(java程序员很熟悉这句话:volatile仅仅用来保证该变量对所有线程的可见性,但不保证原子性)。这不是互相矛盾吗?
1.Volatile不具有原子性 2.告诉jvm该变量为所有线程共享的,Cpu执行时不进行线程间上下文环境切换,提高效率 3.不要将volatile用在getAndOperate场合,仅仅set或者get的场景是适合volatile的
经典的多线程i++问题
例如:volatile int i=0; 有10个线程同时做i++操作,最终结果是几? 答:小于等于10 原因:自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。volatile只能保证可见性,不能保证对其操作的原子性。 比如有两个线程A和B对volatile修饰的i进行i++操作,i的初始值是0,A线程执行i++时刚读取了i的值0,就切换到B线程了,B线程(从内存中)读取i的值也为0,然后就切换到A线程继续执行i++操作,完成后i就为1了,接着切换到B线程,因为之前已经读取过了,所以继续执行i++操作,最后的结果i就为1了。同理可以解释为什么每次运行结果都是小于10的数字。
再来一遍解释: 线程1先读取了变量i的原始值,然后线程1被阻塞了;线程2也去读取变量i的原始值,然后进行加1操作,并把+1后的值写入工作内存,最后写入主存,然后线程1接着进行加1操作,由于已经读取了i的值,此时在线程1的工作内存中i的值仍然是之前的值,所以线程1对i进行加1操作后的值和刚才一样,然后将这个值写入工作内存,最后写入主存。这样就出现了两个线程自增完后其实只加了一次。究其原因是因为volatile不能保证原子性。
jvm中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。
线程工作内存和主内存
read and load 从主存复制变量到当前工作内存 use and assign 执行代码,改变共享变量值 store and write 用工作内存数据刷新主存相关内容 其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的 例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值 在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6 线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6 导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
如何解决?
加synchronized锁(阻塞,性能低)
使用synchronized对i++操作加锁,就能保证同一时刻只有一个线程获取锁然后执行同步代码。运行结果必然是10。 加了同步锁之后,count自增的操作变成了原子性操作,所以最终的输出一定是count=10,代码实现了线程安全。 但使用synchronized锁有性能问题 Synchronized关键字会让没有得到锁资源的线程进入BLOCKED状态,而后在争夺到锁资源后恢复为RUNNABLE状态,这个过程中涉及到操作系统用户模式和内核模式的转换,代价比较高。 尽管Java1.6为Synchronized做了优化,增加了从偏向锁到轻量级锁再到重量级锁的过度,但是在最终转变为重量级锁之后,性能仍然较低。
使用AtomicInteger原子操作类(CAS机制,乐观锁)
所谓原子操作类,指的是java.util.concurrent.atomic包下,一系列以Atomic开头的包装类。例如AtomicBoolean,AtomicInteger,AtomicLong。它们分别用于Boolean,Integer,Long类型的原子性操作。
public static AtomicInteger count = new AtomicInteger(0); count.incrementAndGet();//原子自增
从思想上来说,Synchronized属于悲观锁,悲观地认为程序中的并发情况严重,所以严防死守。CAS属于乐观锁,乐观地认为程序中的并发情况不那么严重,所以让线程不断去尝试更新。
漫画:什么是 CAS 机制? - 程序员小灰 https://blog.csdn.net/bjweimengshu/article/details/78949435
【多线程系列】Volatile总结之同步问题 http://blog.csdn.net/gooooooal/article/details/50014341
Java并发——线程同步Volatile与Synchronized详解 http://blog.csdn.net/seu_calvin/article/details/52370068
JAVA并发编程4_线程同步之volatile关键字 https://www.cnblogs.com/qhyuan1992/p/5385309.html
volatile应用场景
做while循环的状态标记量
比如做while循环是否继续的标记量
private volatile boolean flag= true;
protected void stopTask() {
flag = false;
}
@Override
public void run() {
while (flag) {
// 执行任务…
}
}
配合双重检查实现单例模式
Double-Check单例模式中,为了避免同步代码块外的if (singleton == null)判断可能看到初始化不完成整的实例(不是null但未初始化完成),必须将singleton变量定义为volatile的,以避免jvm指令重排。
public class Singleton {
private static volatile Singleton singleton=null;
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
单例模式与双重检测 http://www.iteye.com/topic/652440
volatile和synchronized的区别
volatile和synchronized的区别 http://blog.csdn.net/suifeng3051/article/details/52611233
锁提供了两种主要特性:互斥(mutual exclusion) 和可见性(visibility)。 Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。
首先需要理解线程安全的两个方面:执行控制和内存可见。
- 执行控制的目的是控制代码执行(顺序)及是否可以并发执行。
- 内存可见控制的是线程执行结果在内存中对其它线程的可见性。根据Java内存模型的实现,线程在具体执行时,会先拷贝主存数据到线程本地(CPU缓存),操作完成后再把结果从线程本地刷到主存。
synchronized关键字解决的是执行控制的问题,它会阻止其它线程获取当前对象的监控锁,这样就使得当前对象中被synchronized关键字保护的代码块无法被其它线程访问,也就无法并发执行。更重要的是,synchronized还会创建一个内存屏障,内存屏障指令保证了所有CPU操作结果都会直接刷到主存中,从而保证了操作的内存可见性,同时也使得先获得这个锁的线程的所有操作,都happens-before于随后获得这个锁的线程的操作。
volatile关键字解决的是内存可见性的问题,会使得所有对volatile变量的读写都会直接刷到主存,即保证了变量的可见性。这样就能满足一些对变量可见性有要求而对读取顺序没有要求的需求。
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。 volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的 volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性 volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。 volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
正确使用 Volatile 变量 https://www.ibm.com/developerworks/cn/java/j-jtp06197.html
happens-before保证可见性
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
happens-before原则定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
下面是happens-before原则规则: 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作; 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作; volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作; 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C; 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作; 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生; 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行; 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
【死磕Java并发】-----Java内存模型之happens-before https://www.cnblogs.com/chenssy/p/6393321.html
Fork/Join框架
Fork/Join框架是Java7提供的一个用于并行执行任务的框架,作者是并发大神Doug Lea,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join框架要完成两件事情:
- 第一步分割任务。 首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
- 第二步执行任务并合并结果。 分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都放在另外一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:RecursiveAction用于没有返回结果的任务。RecursiveTask用于有返回结果的任务。
- ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
Fork/Join的典型用法如下:
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
Fork/Join实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
ForkJoinTask的fork方法实现原理: 当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步的执行这个任务,pushTask方法把当前任务存放在ForkJoinTask 数组queue里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。
ForkJoinTask的join方法实现原理: Join方法的主要作用是阻塞当前线程并等待获取结果。 首先,它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有四种:已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL)。 如果任务状态是已完成,则直接返回任务结果。 如果任务状态是被取消,则直接抛出CancellationException。 如果任务状态是抛出异常,则直接抛出对应的异常。 在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完了,如果执行完了,则直接返回任务状态,如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成了,则设置任务状态为NORMAL,如果出现异常,则纪录异常,并将任务状态设置为EXCEPTIONAL。
聊聊并发(八)——Fork/Join框架介绍 http://ifeve.com/talk-concurrency-forkjoin/
工作窃取(work stealing)
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢? 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
聊聊并发(八)——Fork/Join框架介绍 http://ifeve.com/talk-concurrency-forkjoin/
Fork/Join使用示例(继承RecursiveTask)
我们通过一个简单的例子来介绍一下Fork/Join框架的使用。需求是求1+2+3+4的结果 使用Fork/Join框架首先要考虑到的是如何分割任务,如果希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是4个数字相加,所以Fork/Join框架会把这个任务fork成两个子任务,子任务一负责计算1+2,子任务二负责计算3+4,然后再join两个子任务的结果。因为是有结果的任务,所以必须继承RecursiveTask,实现代码如下:
package concurrent_test;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class ForkJoinCountTask extends RecursiveTask<Integer> {
private static final int THREAD_HOLD = 2; //任务分割阈值
private int start;
private int end;
public ForkJoinCountTask(int start,int end){
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
System.out.println(Thread.currentThread());
int sum = 0;
//如果任务足够小就计算
boolean canCompute = (end - start) <= THREAD_HOLD;
if(canCompute){
for(int i=start;i<=end;i++){
sum += i;
}
}else{
//如果任务大于阀值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoinCountTask left = new ForkJoinCountTask(start,middle);
ForkJoinCountTask right = new ForkJoinCountTask(middle+1,end);
//执行子任务
/* 注意!下面这种两个子任务分别fork的执行方法是低效的,相当于当前线程不干活,把任务拆分后都分给新开的两个线程了
left.fork();
right.fork();
正确的写法是:invokeAll(left, right);
*/
invokeAll(left,right);
//获取子任务结果
int lResult = left.join();
int rResult = right.join();
//合并子任务结果
sum = lResult + rResult;
}
return sum;
}
public static void main(String[] args){
ForkJoinPool pool = new ForkJoinPool();
//生成一个计算任务,负责计算1+2+3+4
ForkJoinCountTask task = new ForkJoinCountTask(1,4);
//执行一个任务
Future<Integer> result = pool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
通过这个例子让我们再来进一步了解ForkJoinTask,ForkJoinTask与一般的任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
Fork/Join框架详解 https://www.cnblogs.com/senlinyang/p/7885964.html
使用invokeAll()代替每个子任务fork()
新手在编写Fork/Join任务时,往往用搜索引擎搜到一个例子,然后就照着例子写出了下面的代码:
protected Long compute() {
if (任务足够小?) {
return computeDirect();
}
// 任务太大,一分为二:
SumTask subtask1 = new SumTask(...);
SumTask subtask2 = new SumTask(...);
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
// 合并结果:
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
return subresult1 + subresult2;
}
这种写法是低效的(也不能说错误,只不过多开了不必要的线程)。 这是因为执行compute()方法的线程本身也是一个Worker线程,当对两个子任务调用fork()时,这个Worker线程就会把任务分配给另外两个Worker,但是它自己却停下来等待不干活了!这样就白白浪费了Fork/Join线程池中的一个Worker线程。
其实,我们查看JDK的invokeAll()方法的源码就可以发现,invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。
ForkJoinTask中两个参数的invokeAll的源码:
public static void invokeAll(ForkJoinTask<?> t1, ForkJoinTask<?> t2) {
int s1, s2;
t2.fork();
if ((s1 = t1.doInvoke() & DONE_MASK) != NORMAL)
t1.reportException(s1);
if ((s2 = t2.doJoin() & DONE_MASK) != NORMAL)
t2.reportException(s2);
}
Java的Fork/Join任务,你写对了吗? - 廖雪峰 https://www.liaoxuefeng.com/article/001493522711597674607c7f4f346628a76145477e2ff82000
Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally()) {
System.out.println(task.getException());
}
getException()方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
ForkJoinTask中getException()方法源码如下:
public final Throwable getException() {
int s = status & DONE_MASK;
return ((s >= NORMAL) ? null :
(s == CANCELLED) ? new CancellationException() :
getThrowableException());
}
Fork/Join框架详解 https://www.cnblogs.com/senlinyang/p/7885964.html
ForkJoinPool
ForkJoinPool 是 java7 中随着 fork/join 框架引入的一个线程池,核心思想和 fork/join 相同,将大的任务拆分成多个小任务(即fork),然后在将多个小任务处理汇总到一个结果上(即join),类似 MapReduce
同时,它提供基本的线程池功能,支持设置最大并发线程数,支持任务排队,支持线程池停止,支持线程池使用情况监控,也是 AbstractExecutorService 的子类,主要引入了“工作窃取”机制,在多CPU计算机上处理性能更佳。
work-stealing(工作窃取),ForkJoinPool 提供了一个更有效的利用线程的机制,当 ThreadPoolExecutor 还在用单个队列存放任务时,ForkJoinPool 已经分配了与线程数相等的队列,当有任务加入线程池时,会被平均分配到对应的队列上,各线程进行正常工作,当有线程提前完成时,会从队列的末端“窃取”其他线程未执行完的任务,当任务量特别大时,CPU多的计算机会表现出更好的性能。
ForkJoinPool 的使用以及原理 https://my.oschina.net/xinxingegeya/blog/3007257
自定义ForkJoinPool线程数
ForkJoinPool 中有个静态的 common 线程池,线程池大小可以通过 system 参数 java.util.concurrent.ForkJoinPool.common.parallelism 配置,如果不配置默认是 Runtime.getRuntime().availableProcessors() - 1 即机器cpu核数-1
public class ForkJoinPool extends AbstractExecutorService {
static final ForkJoinPool common;
static {
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction<ForkJoinPool>() {
public ForkJoinPool run() { return makeCommonPool(); }});
}
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
}