Redis
Redis 相关笔记
redis官方命令手册
https://redis.io/commands
redis官方文档
https://redis.io/documentation
Redis 命令参考
http://doc.redisfans.com/index.html
《Redis 设计与实现》(第一版)
https://redisbook.readthedocs.io/en/latest/index.html
Redis中文官网 - redis文档中心
http://www.redis.cn/documentation.html
redis中文网 - redis教程
http://www.redis.net.cn/tutorial/3501.html
《今天面试了吗》-Redis
https://juejin.im/post/5dccf260f265da0bf66b626d
常用redis命令
Connection 连接
SELECT index 选择数据库
切换到指定的数据库,数据库索引号 index 用数字值指定,以 0 作为起始索引值。
默认使用 0 号数据库。
Server 服务器
info 查看全部服务器信息
INFO [section] 返回 Redis 服务器的各种信息和统计数值。
通过给定可选的参数 section ,可以让命令只返回某一部分的信息,例如 info server 只返回 server section 信息
各 section 主要内容
- server : 一般 Redis 服务器信息
- redis_version : Redis 服务器版本
- os : Redis 服务器的宿主操作系统
- multiplexing_api : Redis 所使用的事件处理机制
- clients : 已连接客户端信息
- connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端)
- memory : 内存信息
- used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
- used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
- used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
- persistence : RDB 和 AOF 的相关信息
- stats : 一般统计信息
- keyspace_hits: 命中次数
- keyspace_misses: miss 次数
- replication : 主/从复制信息
- role: 当前节点的角色 master/slave
- cpu : CPU 计算量统计信息
- commandstats : Redis 命令统计信息
- cluster : Redis 集群信息
- keyspace : 数据库相关的统计信息
> info
# Server
redis_version:3.2.10
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:7be5ac88fa8b3573
redis_mode:cluster
os:Linux 4.14.0_1-0-0-15 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.5
process_id:51244
run_id:027f765ddca6f9b6ad6f74ba0470ffbf7d847e99
tcp_port:8479
uptime_in_seconds:1695642
uptime_in_days:19
hz:10
lru_clock:4402423
executable:/home/aicu-tob/software/redis-cluster-new/./bin/redis-server
config_file:/home/aicu-tob/software/redis-cluster-new/./conf/8479/redis.conf
# Clients
connected_clients:1
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:1312392
used_memory_human:1.25M
used_memory_rss:4808704
used_memory_rss_human:4.59M
used_memory_peak:1403184
used_memory_peak_human:1.34M
total_system_memory:201150214144
total_system_memory_human:187.34G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:3.66
mem_allocator:jemalloc-4.0.3
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1597824601
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_current_size:165818
aof_base_size:0
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
# Stats
total_connections_received:3031
total_commands_processed:6116
instantaneous_ops_per_sec:0
total_net_input_bytes:318050
total_net_output_bytes:7752048
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:169
evicted_keys:0
keyspace_hits:1440
keyspace_misses:266
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:350
migrate_cached_sockets:0
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# CPU
used_cpu_sys:715.56
used_cpu_user:381.94
used_cpu_sys_children:0.22
used_cpu_user_children:0.04
# Cluster
cluster_enabled:1
# Keyspace
db0:keys=2,expires=0,avg_ttl=0
info memory 查看内存信息
127.0.0.1:6379> info memory
# Memory
used_memory:7770256
used_memory_human:7.41M
used_memory_rss:16969728
used_memory_rss_human:16.18M
used_memory_peak:13477064
used_memory_peak_human:12.85M
used_memory_peak_perc:57.66%
used_memory_overhead:6647776
used_memory_startup:1470528
used_memory_dataset:1122480
used_memory_dataset_perc:17.82%
allocator_allocated:7858200
allocator_active:9142272
allocator_resident:15388672
total_system_memory:270359752704
total_system_memory_human:251.79G
used_memory_lua:41984
used_memory_lua_human:41.00K
used_memory_scripts:2024
used_memory_scripts_human:1.98K
number_of_cached_scripts:6
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.16
allocator_frag_bytes:1284072
allocator_rss_ratio:1.68
allocator_rss_bytes:6246400
rss_overhead_ratio:1.10
rss_overhead_bytes:1581056
mem_fragmentation_ratio:2.20
mem_fragmentation_bytes:9240496
mem_not_counted_for_evict:0
mem_replication_backlog:1048576
mem_clients_slaves:20512
mem_clients_normal:4099928
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
lazyfreed_objects:0
查看redis缓存lua脚本个数及内存占用
used_memory_scripts_human Redis缓存Lua脚本所占用的内存number_of_cached_scripts 缓存脚本个数
Redis 支持两种方式调用Lua脚本, 一种是通过 EVAL script numkeys key [key ...] arg [arg ...] 在命令中直接将Lua脚本当做参数专递给Redis执行
但是由于考虑到Lua脚本本身可能体积较大, 如果每次调用同一个Lua脚本都要重新将该脚本原封不动的传递给Redis一次, 不仅给网络带宽带来了一定的开销, 也会影响Redis的性能, Redis支持另外一种使用Lua的方法, 先调用 SCRIPT LOAD script 将Lua脚本加载到Redis服务内部, 并且会返回给客户端一个跟该Lua向关联的Sha1码, 下次调用该Lua脚本的时候, 只需通过 EVALSHA sha1 numkeys key [key ...] arg [arg ...] 命令, 将Sha1码当做参数进行传递即可.
使用 EVALSHA 命令直接通过sha1调用相应Lua脚本的前提是我们必须将Lua脚本缓存在Redis服务内部, Redis使用 f-sha1 作为键, Lua脚本作为值, 将其存放在 server.lua_scripts 字典内部, 方便客户直接使用sha1进行查找。
可以触发缓存 Lua 脚本的 EVAL 命令和 SCRIPT LOAD 命令 使用的内存并不受 maxmemory 限制,如果用户滥用Lua脚本, 可能会造成Redis的内存无法限制的问题。
滥用Lua导致Redis内存无法被限制
https://axlgrep.github.io/tech/redis-memory-control.html
Key键
keys pattern 模糊查找key
KEYS pattern
redis中允许模糊查询的有3个通配符,分别是:*, ?, []*:通配任意多个字符?:通配单个字符[]:通配括号内的某一个字符
查找所有符合给定模式 pattern 的 key 。KEYS * 匹配数据库中所有 key 。KEYS h?llo 匹配 hello , hallo 和 hxllo 等。KEYS h*llo 匹配 hllo 和 heeeeello 等。KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 。
模糊查找keys并打印到一行
利用 xargs 命令处理 keys 命令结果:
redis-cli -h host keys "uds-af-*" | xargs
注意要在远程连接redis的linux命令行中执行,不要登录到redis命令行执行。
模糊匹配1号数据库的keys
redis-cli -h host -n 1 keys "uds-af-*"redis-cli -h host -p 8379 -a 123 -n 1 keys "*" 列出 1 号数据库的全部keyredis-cli -h host -p 8379 -a 123 -n 1 keys "*"|xargs redis-cli -h host -p 8379 -a 123 -n 1 del 列出1号数据库的全部key并都删除
统计模糊匹配keys的个数
利用 wc 命令统计 keys 命令结果的行数:
redis-cli -h host keys "uds-af-*" | wc -l
注意要在远程连接redis的linux命令行中执行,不要登录到redis命令行执行。
模糊匹配keys并get值
String类型:
redis-cli -h redis-host keys "uds-af-*" | xargs redis-cli -h redis-host mget
批量删除模糊匹配的keys
在可远程连接redis的跳板机或本地机器上执行:
redis-cli -h redis-host keys "uds-af-*" | xargs redis-cli -h redis-host del
先通过redis客户端执行keys命令,模糊搜索出匹配的key,通过xargs命令,将结果整理为空格分隔,作为后面redis的del命令的输入。
注意要在远程连接redis的linux命令行中执行,不要登录到redis命令行执行。
生产系统禁止使用keys命令
Redis是单线程的!!!
单线程意味着任何一条命令的执行都是串行的,也就是按顺序一条一条的执行。
那么当你执行的命令耗时就会导致后续的Redis访问都会阻塞。
使用scan代替keys
SCAN cursor [MATCH pattern] [COUNT count]
scan 命令用来分批次扫描Redis记录,保证Redis不会因为耗时导致服务不可用。
scan 第一个参数是游标,表示从游标开始
例如
从下标 0 开始 匹配 user-pre 开头的 key,每次返回10个。
scan 0 match user-pre* count 10
scan 851968 match uds-a* count 10
294912
uds-a-336853226
scan 第一个参数是游标,表示从游标开始
返回的第一行是游标,第二行是匹配到的数据,
如果第一行返回0,表示没有更多数据,否则下次使用scan时,就要用第一行返回的值作为scan的游标
每次返回的,并不一定是 count 个,但只要命令返回的游标不是 0 , 应用程序就不应该将迭代视作结束。
SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
del key key1 key2 删除一个或多个key
DEL key [key …]
删除给定的一个或多个 key。
不存在的 key 会被忽略。
返回值: 被删除 key 的数量。
expire key seconds 设置key的过期时间为seconds秒
expire key seconds 设置key的有效时间 单位为秒
pexpire key milliseconds 设置毫秒过期时间
这个命令和 EXPIRE 命令的作用类似,但是它以毫秒为单位设置 key 的生存时间,而不像 EXPIRE 命令那样,以秒为单位。
ttl key 返回key的生存时间(秒)
TTL key
以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
返回值:
当 key 不存在时,返回 -2 。
当 key 存在但没有设置剩余生存时间时,返回 -1 。
否则,以秒为单位,返回 key 的剩余生存时间。
persist key 将key设置为永久有效
PERSIST key
移除给定 key 的生存时间,将这个 key 从『易失的』(带生存时间 key )转换成『持久的』(一个不带生存时间、永不过期的 key )。
设置有时效性的key为持久key
type key 查看key的类型
TYPE key
返回 key 所储存的值的类型。
可用版本:>= 1.0.0
时间复杂度:O(1)
返回值:
none (key不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
String 字符串
get key
返回 key 所关联的字符串值。
如果 key 不存在那么返回特殊值 nil 。
假如 key 储存的值不是字符串类型,返回一个错误,因为 GET 只能用于处理字符串值。
mget key [key ...]
返回所有(一个或多个)给定 key 的值。
如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。因此,该命令永不失败。
set key value [EX seconds] [PX mills] [NX|XX]
set key value [EX seconds] [PX milliseconds] [NX|XX]
将字符串值 value 关联到 key 。
如果 key 已经持有其他值, SET 就覆写旧值,无视类型。
对于某个原本带有生存时间(TTL)的键来说, 当 SET 命令成功在这个键上执行时, 这个键原有的 TTL 将被清除。
可选参数:
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:EX second 设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。PX millisecond 设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。NX 只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。XX 只在键已经存在时,才对键进行设置操作。
因为 SET 命令可以通过参数来实现和 SETNX, SETEX, PSETEX 三个命令同等的效果,所以将来的 Redis 版本可能会废弃并最终移除这三个命令。
KEEPTTL 保留 key 原来的过期时间
GET 若key已存在返回旧值,否则返回 nilEXAT timestamp-seconds 在指定的时间戳(秒)过期PXAT timestamp-milliseconds 在指定的时间戳(毫秒)过期
返回值:
在 Redis 2.6.12 版本以前, SET 命令总是返回 OK 。
从 Redis 2.6.12 版本开始, SET 在设置操作成功完成时,才返回 OK 。
如果设置了 NX 或者 XX ,但因为条件没达到而造成设置操作未执行,那么命令返回空批量回复(NULL Bulk Reply)。
版本历史:
2.6.12 开始,增加 EX, PX, NX, XX 选项
6.0 开始,增加 KEEPTTL 选项
6.2 开始,增加 GET, EXAT, PXAT 选项
setex key seconds value
将值 value 关联到 key ,并将 key 的生存时间设为 seconds (以秒为单位)。
如果 key 已经存在, SETEX 命令将覆写旧值。
这个命令类似于以下两个命令:
SET key value
EXPIRE key seconds # 设置生存时间
不同之处是, SETEX 是一个原子性(atomic)操作,关联值和设置生存时间两个动作会在同一时间内完成,该命令在 Redis 用作缓存时,非常实用。
返回值:
设置成功时返回 OK 。
当 seconds 参数不合法时,返回一个错误。
setnx key value
SETNX key value
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
返回值:
设置成功,返回 1 。
设置失败,返回 0 。
mset key value [key value ...]
同时设置一个或多个 key-value 对。
如果某个给定 key 已经存在,那么 MSET 会用新值覆盖原来的旧值,如果这不是你所希望的效果,请考虑使用 MSETNX 命令:它只会在所有给定 key 都不存在的情况下进行设置操作。
MSET 是一个原子性(atomic)操作,所有给定 key 都会在同一时间内被设置,某些给定 key 被更新而另一些给定 key 没有改变的情况,不可能发生。
incr key 增加1
将 key 中储存的数字值增一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
本操作的值限制在 64 位(bit)有符号数字表示之内。
这是一个针对字符串的操作,因为 Redis 没有专用的整数类型,所以 key 内储存的字符串被解释为十进制 64 位有符号整数来执行 INCR 操作。
可用版本:>= 1.0.0
时间复杂度: O(1)
返回值: 执行 INCR 命令之后 key 的值。
http://doc.redisfans.com/string/incr.html
Redis原子计数器incr,防止并发请求
https://blog.csdn.net/Roy_70/article/details/78260826
incr/decr key是原子的
Redis所有单个命令的执行都是原子性的,这与它的单线程机制有关;
Redis命令的原子性使得我们不用考虑并发问题,可以方便的利用原子性自增操作INCR实现简单计数器功能;
即使服务是多机器多进程的,incr/decr 也能保证每次返回的结果不会出现相同的值.
incrby key n 增加n
incrby key increment
将 key 所储存的值加上增量 increment 。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCRBY 命令。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
本操作的值限制在 64 位(bit)有符号数字表示之内。
可用版本:>= 1.0.0
时间复杂度:O(1)
返回值:加上 increment 之后, key 的值。
decr key
将 key 中储存的数字值减一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 DECR 操作。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
本操作的值限制在 64 位(bit)有符号数字表示之内。
setbit key offset value 设置指定偏移量的bit
SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
位的设置或清除取决于 value 参数,可以是 0 也可以是 1 。
当 key 不存在时,自动生成一个新的字符串值。
字符串会进行伸展(grown)以确保它可以将 value 保存在指定的偏移量上。当字符串值进行伸展时,空白位置以 0 填充。
offset 参数必须大于或等于 0 ,小于 2^32 (bit 映射被限制在 512 MB 之内)。
对使用大的 offset 的 SETBIT 操作来说,内存分配可能造成 Redis 服务器被阻塞。具体参考 SETRANGE 命令,warning(警告)部分。
可用版本:>= 2.2.0
时间复杂度: O(1)
返回值:指定偏移量原来储存的位。
getbit key offset 获取指定偏移量的bit
对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
当 offset 比字符串值的长度大,或者 key 不存在时,返回 0 。
bitmap的空间占用
Redis 其实只支持 5 种数据类型,并没有 BitMap 这种类型,BitMap 底层是基于 Redis 的字符串类型实现的。
假如 BitMap 偏移量的最大值是 OFFSET_MAX, 那么它底层占用的空间就是:
(OFFSET_MAX/8)+1 = 占用字节数
因为字符串内存只能以字节分配,所以上面的单位是字节。
但是需要注意,Redis 中字符串的最大长度是 512M,所以 BitMap 的 offset 值也是有上限的,其最大值是:
8 * 1024 * 1024 * 512 = 2^32
由于 C语言中字符串的末尾都要存储一位分隔符,所以实际上 BitMap 的 offset 值上限是:
(8 * 1024 * 1024 * 512) -1 = 2^32 - 1
Redis中bitmap的妙用
Redis中bitmap的妙用
https://segmentfault.com/a/1190000008188655
strlen
STRLEN key
返回 key 所储存的字符串值的长度。
当 key 储存的不是字符串值时,返回一个错误。
可用版本:>= 2.2.0
复杂度:O(1)
返回值:字符串值的长度。
当 key 不存在时,返回 0 。
APPEND key value
如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
可用版本: >= 2.0.0
时间复杂度: 平摊O(1)
返回值: 追加 value 之后, key 中字符串的长度。
hash 哈希表
hget key field 返回哈希表key中的field字段值
HGET key field
返回哈希表 key 中给定域 field 的值。
hset key field value 设置哈希表key中的field值
将哈希表 key 中的域 field 的值设为 value 。
如果 key 不存在,一个新的哈希表被创建并进行 HSET 操作。
如果域 field 已经存在于哈希表中,旧值将被覆盖。
hmget key field field2 返回哈希表key中多个字段值
HMGET key field [field …]
返回哈希表 key 中,一个或多个给定域的值。
如果给定的域不存在于哈希表,那么返回一个 nil 值。
因为不存在的 key 被当作一个空哈希表来处理,所以对一个不存在的 key 进行 HMGET 操作将返回一个只带有 nil 值的表。
hgetall key 返回哈希表key的所有字段和值
HGETALL key
返回哈希表 key 中,所有的域和值。
在返回值里,紧跟每个域名(field name)之后是域的值(value),所以返回值的长度是哈希表大小的两倍。
list列表
lrange key start stop 返回列表key指定区间内的元素
LRANGE key start stop
返回列表 key 中指定区间内的元素,偏移量 start 和 stop 指定的区间是闭区间,前后都包含。
下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。
你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
注意LRANGE命令和编程语言区间函数的区别
假如你有一个包含一百个元素的列表,对该列表执行 LRANGE list 0 10 ,结果是一个包含11个元素的列表,这表明 stop 下标也在 LRANGE 命令的取值范围之内(闭区间),这和某些语言的区间函数可能不一致,比如Ruby的 Range.new 、 Array#slice 和Python的 range() 函数。
超出范围的下标
超出范围的下标值不会引起错误。
如果 start 下标比列表的最大下标 end ( LLEN list 减去 1 )还要大,那么 LRANGE 返回一个空列表。
如果 stop 下标比 end 下标还要大,Redis将 stop 的值设置为 end 。
1、lrange 查询 list 全部数据
10.233.1.123:6379> lrange key1 0 -1
1) "value1"
2) "value2"
3) "value3"
2、集群方式执行时,报错不识别参数 -1
redis-cli --cluster call localhost:6379 lrange key1 0 -1
Unrecognized option or bad number of args for: '-1'
Redis应用
lua+redis令牌桶限流算法
Redis与Lua脚本
Redis分布式锁
set k v nx px实现普通Redis分布式锁(单redis实例分布式锁)
通过redis命令 set key value px milliseconds nx 实现简单的单机分布式锁
核心命令:
- 获取锁(unique_value可以是UUID等)
SET resource_name unique_value NX PX 30000
- 释放锁(lua脚本中,一定要比较value,防止误解锁)
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这种实现方式有3大要点(也是面试概率非常高的地方):
1、set 命令要用 set key value px milliseconds nx 保证原子性
2、value 要具有唯一性,可以取 host+threadId
3、释放锁时要验证value值,不能误解锁;
事实上这类琐最大的缺点就是它加锁时只作用在一个Redis节点上,即使Redis通过sentinel保证高可用,如果这个master节点由于某些原因发生了主从切换,那么就会出现锁丢失的情况:
1、在Redis的master节点上拿到了锁;
2、但是这个加锁的key还没有同步到slave节点;
3、master故障,发生故障转移,slave节点升级为master节点;
4、导致锁丢失。
redis官方文档里最后也给出了使用 set 做分布式锁的使用建议
https://redis.io/commands/set
redis分布式锁实例(Java)
@Service
@Slf4j
public class ReentrantRedisLock {
private static final String LOCK_PREFIX = "dlock";
private static final String LOCK_SUFFIX = "app-name";
@Value("${spring.profiles.active}")
private String env;
@Autowired
private StringRedisTemplate redisTemplate;
// 加锁
public boolean tryLock(String key, final long timeout, final TimeUnit unit) {
String sLockKey = getLockKey(key);
return tryAcquire(sLockKey, timeout, unit);
}
// 解锁
public void unlock(String key) {
String sLockValue = redisTemplate.opsForValue().get(getLockKey(key));
// 解锁时必须比较锁内容
if (sLockValue != null && getLockValue().equalsIgnoreCase(sLockValue)) {
redisTemplate.delete(getLockKey(key));
}
}
private boolean tryAcquire(String sLockKey, final long timeout, final TimeUnit unit) {
String result = redisTemplate.execute((RedisCallback<String>) connection -> {
JedisCommands commands = (JedisCommands) connection.getNativeConnection();
SetParams setParams = new SetParams();
setParams.nx();
// 加锁一定要带有效期
setParams.px(TimeoutUtils.toMillis(timeout, unit));
return commands.set(sLockKey, getLockValue(), setParams);
});
if (StringUtils.isNotEmpty(result)) {
log.info("Get lock for key: {},timeout:{}s", sLockKey, TimeoutUtils.toSeconds(timeout, unit));
return true;
}
return false;
}
// 锁key
private String getLockKey(String key) {
return LOCK_PREFIX + "_" + this.env + "_" + LOCK_SUFFIX + "_" + key;
}
// 锁的内容是加锁线程的标识,host+线程id
private String getLockValue() {
return resolveHostName() + "_" + Thread.currentThread().getId();
}
private String resolveHostName() {
try {
return InetAddress.getLocalHost().getHostName();
} catch (Exception e) {
return LocalIpAddressUtil.resolveLocalIp();
}
}
}
Redlock 跨redis实例分布式锁
在Redis的分布式环境中,我们假设有N个Redis master。这些节点完全互相独立,或者说有N个互相隔离的reids单例/redis集群(注意不是一个redis集群里有N个结点),不存在主从复制或者其他集群协调机制。
我们确保将在N个实例上使用与在Redis单实例下相同方法获取和释放锁。现在我们假设有5个Redis master节点,同时我们需要在5台服务器上面运行这些Redis实例,这样保证他们不会同时都宕掉。
为了取到锁,客户端应该执行以下操作:
1、获取当前Unix时间,以毫秒为单位。
2、依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁。当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
3、客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
4、如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
5、如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
Redlock:Redis分布式锁最牛逼的实现
https://www.jianshu.com/p/7e47a4503b87
Distributed locks with Redis
https://redis.io/topics/distlock
基于 Redis 的分布式锁 Redlock
https://zhuanlan.zhihu.com/p/40915772
服务器出现时钟回拨时会有什么问题?
redis分布式锁对比zookeeper分布式锁
没有绝对的好坏,只有更适合自己的业务。
就性能而言,redis很明显优于zookeeper;
就分布式锁实现的健壮性而言,zookeeper很明显优于redis。
如何选择,取决于你的业务!
分布式锁key设计错误导致没锁住案例排查
有个关系表,比如
create table student_school_table
(
student_id bigint null,
school_id bigint null
);
业务要求是一个学生只能有唯一的一所学校,即 student_school_table 表中 每个 student_id 最多对应一个 school_id,但表上忘了给 student_id 加唯一索引。
后端代码中,更新 student_school_table 表时,redis 分布式锁的key设计为 keyprefix-student_id-school_id, 这么设计是不对的。
出错案例如下:
并发有两个更新 student_id=1 的学校的请求同时打到2台服务器server1, server2上,server1上的请求是把 学生1的学校id更新为100, server2上的请求是把 学生1的学校id更新为200。
两台服务器上会分别请求加分布式锁,server1请求加锁 keyprefix-1-100, server2请求加锁 keyprefix-1-200, 都能加锁成功,从而往表中写入 student_id=1 的两条学校记录。
解决方案:
分布式key设计为 keyprefix-student_id 即可,即对同一个学生的学校修改要改为串行的。
Redisson
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。
充分的利用了Redis键值数据库提供的一系列优势,基于Java实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
Redisson项目介绍
https://github.com/redisson/redisson/wiki
redisson/redisson
https://github.com/redisson/redisson
Redisson实现redis分布式锁
Redisson实现Redis分布式锁的N种姿势
https://www.jianshu.com/p/f302aa345ca8
Jedis
Jedis模糊匹配keys
Jedis Redis 模糊匹配 取得 key 列表
往Redis中初始化几条测试数据:
china:beijing
china:shandong:heze
china:shandong:jinan
Jedis jedis = new Jedis("10.110.20.152", 6379);
Set<String> set = jedis.keys("china:shandong*");
for (String key : set) {
System.out.println(key);
}
* 0到任意多个字符? 1个字符
Lettuce
ConnectionWatchdog Reconnecting, last destination was
spring boot 2.x 使用 lettuce 客户端连接 redis 集群,启动后一致打下面的日志
io.lettuce.core.protocol.ConnectionWatchdog - Reconnecting, last destination was ***
这是 lettuce 客户端的重连机制,一段时间没有使用 redis 的话会断开连接,然后 lettuce 会自动重连。不是错误。
why lettuce client keep reconnecting #861
https://github.com/lettuce-io/lettuce-core/issues/861
jedis/lettuce/redisson 对比
Jedis
老牌的Java实现客户端,提供了比较全面的Redis命令的支持,
使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Redisson
实现了分布式和可扩展的Java数据结构。
促使使用者对Redis的关注分离,提供很多分布式相关操作服务,例如分布式锁,分布式集合,可通过Redis支持延迟队列
基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作
Lettuce
高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。
主要在一些分布式缓存框架上使用比较多
基于Netty框架的事件驱动的通信层,其方法调用是异步的。Lettuce的API是线程安全的,所以可以操作单个Lettuce连接来完成各种操作
redis管道(pipeline)
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现。
Pipeline在某些场景下非常有用,比如有多个command需要被“及时的”提交,而且他们对相应结果没有互相依赖,对结果响应也无需立即获得,那么pipeline就可以充当这种“批处理”的工具;而且在一定程度上,可以较大的提升性能,性能提升的原因主要是TCP连接中减少了“交互往返”的时间。
不过在编码时请注意,pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。
管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline通过减少客户端与redis的通信次数来实现降低往返延时时间,而且Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说arges中累加到53条数据时会把数据提交。
需要注意到是用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
适用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进redis了,那这种场景就不适合。
还有的系统,可能是批量的将数据写入redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入redis,可能失败了2条无所谓,后期有补偿机制就行了
分布式缓存Redis之Pipeline(管道)
https://blog.csdn.net/u011489043/article/details/78769428
直接通过Jedis使用管道
不集成 spring,直接利用 jedis 客户端直接操作
public void test3Pipelined() {
Jedis jedis = new Jedis("localhost");
Pipeline pipeline = jedis.pipelined();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
pipeline.set("p" + i, "p" + i);
}
List<Object> results = pipeline.syncAndReturnAll();
long end = System.currentTimeMillis();
System.out.println("Pipelined SET: " + ((end - start)/1000.0) + " seconds");
jedis.disconnect();
}
Redis的Java客户端Jedis的八种调用方式(事务、管道、分布式…)介绍
http://www.blogways.net/blog/2013/06/02/jedis-demo.html
通过 Spring RedisTemplate 使用管道
List<Object> results = this.getRedisTemplate().executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
RedisSerializer<String> keySerializer=new StringRedisSerializer();
for (String key : keys) {
connection.get(keySerializer.serialize(key));
}
return null;
}
});
在doInRedis方法中实现需要的redis操作
doInRedis中的redis操作不会立刻执行
所有redis操作会在connection.closePipeline()之后一并提交到redis并执行,这是pipeline方式的优势
所有操作的执行结果为executePipelined()的返回值
redis pipeline简介
https://www.jianshu.com/p/a8e33e058518
我们的封装方式:
// 封装stringRedisTemplate的管道方法
public List<Object> executePipelined(RedisCallback<?> action){
return stringRedisTemplate.executePipelined(action);
}
// 使用管道实现带过期时间的mset
public void multiSet(Map<String, String> map, long milliSeconds) {
checkState(map != null, "Required not-null param 'map'");
checkState(milliSeconds > 0, "Required param 'seconds' must > 0");
executePipelined(redisConnection -> {
RedisSerializer<String> serializer = new StringRedisSerializer();
map.forEach((k, v) -> {
redisConnection.set(serializer.serialize(k), serializer.serialize(v));
redisConnection.pExpire(serializer.serialize(k), milliSeconds);
});
return null;
});
}
redis集群模式下使用pipeline
为什么RedisCluster无法使用pipeline?
Redis 集群的键空间被分割为 16384 个槽(slot),集群的最大节点数量也是 16384 个。每个主节点都负责处理 16384 个哈希槽的其中一部分。
具体的redis命令,会根据key计算出一个槽位(slot),然后根据槽位去特定的节点redis上执行操作。
一次 pipeline 会批量执行多个命令,那么每个命令都需要根据“key”运算一个槽位(JedisClusterCRC16.getSlot(key)),然后根据槽位去特定的机器执行命令,也就是说一次 pipeline 操作会使用多个节点的 redis 连接,而目前 JedisCluster 是无法支持的。
基于JedisCluster扩展pipeline?
设计思路
1、首先要根据 key 计算出此次 pipeline 会使用到的节点对应的连接(也就是 jedis 对象,通常每个节点对应一个Pool)。
2、相同槽位的 key ,使用同一个 jedis.pipeline 去执行命令。
3、合并此次 pipeline 所有的 response 返回。
4、连接释放返回到池中。
也就是将一个 JedisCluster 下的 pipeline 分解为每个单节点下独立的 jedisPipeline 操作,最后合并 response 返回。具体实现就是通过 JedisClusterCRC16.getSlot(key) 计算 key 的 slot 值,通过每个节点的 slot 分布,就知道了哪些 key 应该在哪些节点上。再获取这个节点的 JedisPool 就可以使用 pipeline 进行读写了。
一种简单实现Redis集群Pipeline功能的方法及性能测试
https://www.cnblogs.com/xiaodf/p/11002184.html
redis集群客户端JedisCluster优化 - 管道(pipeline)模式支持
https://blog.csdn.net/youaremoon/article/details/51751991
redis-cluster集群模式下使用pipeline,mget,mset批量操作
https://my.oschina.net/u/1266221/blog/894308
redis-cluster官方集群模式下使用pipeline批量操作
https://blog.csdn.net/kevin_pso/article/details/53945053
redis pipeline不保证原子性
pipeline 只是批量操作,但不保证多个操作的原子性
redis pipeline与lua脚本对比
pipeline 只是批量操作,但不保证多个操作的原子性
lua 脚本能保证多个操作的原子性
Redis和数据库不一致问题
如果要“保证”数据的安全性,那么会带来开销的进一步提升,以至于使用redis带来的性能优势都会丧失。正确的做法是区分不同的业务,使得并不需要“保证”数据一致性的场合,可以使用redis优化。而敏感的场合依然使用mysql。
数据库和缓存之间一般不需要强一致性。
一般缓存是这样的:
读的顺序是先读缓存,后读数据库
写的顺序是先写数据库,然后写缓存
每次更新了相关的数据,都要把该缓存清理掉
为了避免极端条件下造成的缓存与数据库之间的数据不一致,缓存需要设置一个失效时间。时间到了,缓存自动被清理,达到缓存和数据库数据的“最终一致性”
为保证redis和数据库的数据一致性,写入策略应该是:
先使redis key失效(删除key),再写入数据库,等redis查询时自动去数据库更新。也就是缓存只做失效,不做更新。
数据库与缓存双写情况下导致数据不一致问题
场景一
当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
场景一解决方案
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
场景二
在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
场景二解决方案
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
redis系列之数据库与缓存数据一致性解决方案
http://blog.csdn.net/simba_1986/article/details/77823309
mysql binlog
Mysql的binlog日志作用是用来记录mysql内部增删改查等对mysql数据库有更新的内容的记录(对数据库的改动),对数据库的查询select或show等不会被binlog日志记录;主要用于数据库的主从复制以及增量恢复。
使用阿里的同步工具canal,canal实现方式是模拟mysql slave和master的同步机制,监控DB bitlog的日志更新来触发缓存的更新,此种方法可以解放程序员双手,减少工作量,但在使用时有些局限性。
Redis数据类型
redisObject
Redis 对外提供了5种value数据类型, String(字符串)、list(链表)、set(集合)、zset(有序集合)和hash(哈希)
这些类型每个都对应一个或多个内部数据类型,Redis 通过 redisObject 对象将外部类型和内部类型映射起来。
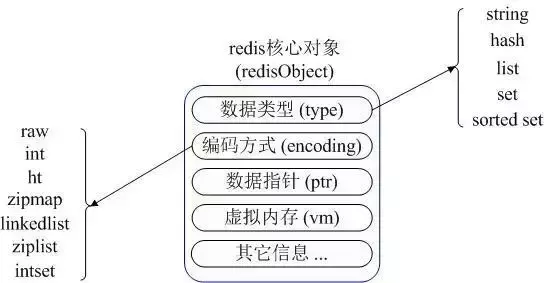
Redis数据类型映射
redis内部使用一个redisObject对象来表示所有的key和value
redisObject最主要的信息如上图所示:
type 表示一个value对象具体是何种数据类型
encoding是不同数据类型在redis内部的存储方式。比如:type=string表示value存储的是一个普通字符串,那么encoding可以是raw或者int。如果是 int 则代表实际 redis 内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:”123” “456”这样的字符串。
列表list(双向链表,有序)
列表(list)类型是用来存储多个字符串,元素从左到右组成一个有序的集合.列表中的每个字符串被称为元素(element),一个列表最多可以存储(2的32次方)-1个元素.
在redis中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定所有下标的元素等.
列表类型有两个特点:
1、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表.
2、列表中的元素可以是重复的.
操作命令
插入
从右边插入元素. rpush key value [value…]
从左边插入元素. lpush key value [value….] 使用方法与rpush一样,从左侧插入.
查询
(1) 查询指定范围内的元素列表 lrange key start end
lrange操作会获取列表指定索引范围所有的元素.索引下标有两个特点:第一,索引下标从左到右分别是0到N-1,但是从右到左分别是-1到-N.第二,lrange中的end选项包含了自身.
(2) 获取列表指定索引下的元素 lindex key index
(3) 获取列表长度 llen key
删除
(1) 从列表左侧或右侧弹出元素. lpop key rpop key 将列表最左侧与右侧的元素弹出来.
(2) 删除指定元素 lrem key count value
lrem命令会从列表中找到等于value的元素进行删除,根据count的不同分为三种:
count>0,从列表中删除指定数量(count)的元素.
count<0,从列表中删除count绝对值数量的元素.
count=0,删除所有.
(3) 按照索引范围修剪列表 ltrim key start end
修改
修改指定索引下标的元素: lset key index value
阻塞操作
阻塞式弹出: blpop key [key…] timeout brpop key [key…] timeout
blpop与brpop命令是lpop和rpop命令的阻塞版本,他除了弹出方向不同,使用方法基本相同,所以下面以brpop命令进行说明,
brpop命令包含两个参数:
1)列表为空:如果timeout等于3,那么客户端等到三秒后返回,如果timeout=0,那么客户端将一直阻塞,直到弹出成功.
2)列表不为空:客户端会立刻返回.
在使用阻塞弹出命令时,有两点需要注意.
第一点:如果是多个键,那么会从左到右遍历键,一旦有一个键能弹出元素客户端就会立刻返回.
第二点:如果多个客户端同时对一个键进行操作,那么最先执行命令的客户端可以获取到值.
内部数据结构(压缩列表,链表)
列表类型的内部编码有两种
1、ziplist(压缩列表):当列表的元素个数大于 list-max-ziplist-entries 配置(默认为512个),同时列表中每个元素的长度小于 list-max-ziplist-value 配置(默认为64字节).
2、linkedlist(链表):当列表的长度或值得大小不满足ziplist的要求,redis会采用linkedlist为列表的内部实现编码.
使用场景(阻塞队列)
1、消息队列:redis的lpush-brpop命令组合即可实现阻塞队列,生产者客户端使用lpush命令向列表插入元素.消费者客户端使用brpop命令阻塞式的”抢”列表中的尾部元素.多个客户端保证消息的负载均衡与可用性.
2、文章列表:每个用户都有属于自己的文章列表.此时可以考虑使用列表,因为列表不但是有序的,同时支持使用lrange按照索引范围获取多个元素.
3、开发提示:列表的使用场景有很多如: lpush+lpop=Stack(栈)、lpush+rpop=queue(队列)、lpush+brpop=message queue、lpush+ltrim=Capped Collection(有限集合)
4、twitter的关注列表,粉丝列表都可以用list结构来实现。
redis有序集合性能 列表、集合、有序集合
https://blog.csdn.net/ttomqq/article/details/78548489
集合set(无序,不可重复)
集合(set)类型也是用来保存多个的字符串元素,但和列表不同的是:它的元素是无序且不可重复的,不能通过索引获取元素
操作命令
集合内操作
(1) 添加元素 sadd key value [value…] 返回结果为添加成功的元素数量.
(2) 删除元素 srem key value [value…] 返回结果为删除成功的元素数量.
(3) 获取元素个数 scard key
(4) 判断元素是否在集合中 sismember key value
(5) 随机从集合中返回指定个数元素 srandmember key [count] [count]是可选参数,如果不写默认为:1.
(6) 从集合中随机弹出元素 spop key spop操作可以从集合中随机弹出一个元素.
(7) 获取集合的所有元素 smembers key 获取集合所有元素,且返回结果是无序的.
集合间操作
(1) 求多个集合的交集 sinter key [key…]
(2) 求多个集合的并集 sunion key [key…]
(3) 求多个集合的差集 sdiff key [key…]
(4) 将交集、并集、差集的结果保存.
sinterstore storeKey key [key…]
sunionstore storeKey key [key…]
sdiffstore storeKey key [key…]
集合间的运算在元素比较多的情况下会比较耗时,所以redis提供了上面三个命令(原命令+store)将集合间交集、并集、差集的结果保存到storeKey中,例如将user:1:follows和user:2:follows两个集合之间的交集结果保存到user:1_2:follows中
内部数据结构(哈希表,整数集合)
集合类型的内部编码有两种:
1、intset(整数集合)
当集合中的元素全是整数,且长度不超过 set-max-intset-entries (默认为512个)时,redis会选用intset作为内部编码.
2、hashtable(哈希表)
当集合无法满足intset的条件时,redis会使用hashtable作为内部编码.
使用场景(用户标签)
集合类型比较典型的使用场景是标签(tag).例如一个用户可能对音乐感兴趣,另一个用户对新闻感兴趣,这些想去点就是标签.有了这些数据就可以获得喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验来说比较重要.
redis有序集合性能 列表、集合、有序集合
https://blog.csdn.net/ttomqq/article/details/78548489
有序集合zset(按分值score排序)
有序集合相对于哈希、列表、集合来说会有一点陌生,但既然叫有序集合.那么它和集合必然是有着联系,它保留了集合不能重复元素的特性.但不同的是,有序集合是可排序的.但是他和列表使用索引下标进行排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据
集合内操作命令
添加成员zadd key score mem(logn复杂度)
(1) 添加成员 zadd key score member [score member …]
有关zadd命令有两点需要注意: Redis 3.2为zadd命令添加了nx、xx、ch、incr四个选项:
nx:member必须不存在,才可以设置成功,用于添加.
xx:member必须存在,才可以设置成功,用于添加.
ch:返回此次操作后,有序集合元素和分数发生变化的个数.
incr: 对score进行添加操作,相当于后面介绍的zincrby.
有序集合相比集合提供了排序字段,但是也产生了代价,zadd的时间复杂度是O(log(n)),sadd的时间复杂度为O(1).
(2) 获取成员个数 zcard key
获取成员分数zscore key mem
(3) 获取某个成员的分数 zscore key member
获取成员排名zrank key mem
(4) 获取成员排名 zrank key member zrevrank key member
(5) 删除成员 zrem key member [member…]
(6) 增加成员分数 zincrby key score member
获取指定范围元素 zrange key start end
(7) 获取指定范围的元素 zrange key start end [withscores] zrevrange key start end [withscores]
有序集合是按照分值排名的,zrange是由低到高返回,zrevrange反之,查询全部:zrange user:ranking 0 -1,加上withscores参数显示分数.
获取指定分值范围元素 zrangebyscore key min max
(8) 返回指定分数范围的成员 zrangebyscore key min max [withscores] [limit offset count] zrevrangebyscore key min max [withscores] [limit offset count]
(9) 返回指定分数范围成员个数 zcount key min max
(10) 删除指定排名内的升序元素 zremrangebyrank key start end
(11) 删除指定分数范围的成员 zremrangebyscore key min max
集合间的操作命令
(1) 交集
zinterstore storeKey keyNum key [key …] [weights weight [weight…]] [aggregate sum|min|max]
参数说明:
storeKey:交集计算结果保存到这个键下.
keyNum:需要做交集的键的个数.
key[key …]:需要做交集的键.
weights weight [weight…]:每个键的权重,在做交集计算时,每个键中的每个member的分值会和这个权重相乘,每个键的权重默认为1.
aggregate sum|min|sum:计算成员交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做汇总.默认值为sum.
(2) 并集
zunionstore storeKey keyNum key [key…] [weights weight [weight…]] [aggregate sum|min|max]
该命令的所有参数和zinterstore是一致的,只不过做的是并集计算
内部数据结构(跳跃表,压缩列表)
1、ziplist(压缩列表)
当有序集合的元素小于 zset-max-ziplist-entries 配置(默认是128个),同时每个元素的值都小于 zset-max-ziplist-value (默认是64字节)时,Redis会用ziplist来作为有序集合的内部编码实现,ziplist可以有效的减少内存的使用
2、skiplist(跳跃表)
当ziplist的条件不满足时,有序集合将使用skiplist作为内部编码的实现,来解决此时ziplist造成的读写效率下降的问题.
redis有序集合性能 列表、集合、有序集合
https://blog.csdn.net/ttomqq/article/details/78548489
redis各数据类型的使用场景
string
计数器应用
list
取最新n个数据的操作
消息队列
删除与过滤
实时分析正在发生的情况,用于数据统计与防垃圾邮件
set
unique操作,获取某段时间说有数据的排重值
实时系统,反垃圾系统
共同好友,二度好友
利用唯一性,可以统计访问法网站的所有独立IP
好友推荐的时候,根据tag求交集,大于某个threshold就可推荐
hash
存储、读取、修改用户属性
sorted set
排行榜应用,取top n操作
需要精准设定过期时间的应用(时间戳作为score)
带有权重的元素,比如一个游戏的用户得分排行榜
过期项目处理,按照时间排序
redis有序集合性能 列表、集合、有序集合
https://blog.csdn.net/ttomqq/article/details/78548489
redis中哪些操作是O(n)复杂度的?
1、List: lindex、lset、linsert
LINDEX key index 返回列表 key 中,下标为 index 的元素。 O(N)
LSET key index value 将列表 key 下标为 index 的元素的值设置为 value O(N)
LINSERT key BEFORE|AFTER pivot value 将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。 O(N)
2、Hash: hgetall、hkeys、hvals
HGETALL key 返回哈希表 key 中,所有的域和值。 O(N)
HKEYS key 返回哈希表 key 中的所有域。 O(N)
HVALS key 返回哈希表 key 中所有域的值。 O(N)
3、Set: smembers、sunion、sunionstore、sinter、sinterstore、sdiff、sdiffstore
SMEMBERS key 返回集合 key 中的所有成员。 O(N), N 为集合的基数。
SUNION key [key …] 返回一个集合的全部成员,该集合是所有给定集合的并集。 O(N), N 是所有给定集合的成员数量之和。
SUNIONSTORE destination key [key …] 这个命令类似于 SUNION 命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。
SINTER key [key …] 返回一个集合的全部成员,该集合是所有给定集合的交集。O(MN),N 为给定集合当中基数最小的集合, M 为给定集合的个数
SINTERSTORE destination key [key …] 这个命令类似于 SINTER 命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。O(MN),N 为给定集合当中基数最小的集合, M 为给定集合的个数
SDIFF key [key …] 返回一个集合的全部成员,该集合是所有给定集合之间的差集。O(N) sdiff set1 set2 的结果是在 set1 中但不在 set2 中的value
4、Sorted Set: zrange、zrevrange、zrangebyscore、zrevrangebyscore、zremrangebyrank、zremrangebyscore
ZRANGE key start stop [WITHSCORES] 返回有序集 key 中,指定区间内的成员。 其中成员的位置按 score 值递增(从小到大)来排序。 O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数。
ZREVRANGE key start stop [WITHSCORES] 返回有序集 key 中,指定区间内的成员。 其中成员的位置按 score 值递减(从大到小)来排列。 O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 O(log(N)+M), N 为有序集的基数, M 为被结果集的基数。
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] 返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成员。有序集成员按 score 值递减(从大到小)的次序排列。 O(log(N)+M), N 为有序集的基数, M 为结果集的基数。
ZREMRANGEBYRANK key start stop 移除有序集 key 中,指定排名(rank)区间内的所有成员。 O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量。
ZREMRANGEBYSCORE key min max 移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。 O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量。
reids中哪些操作是O(1)复杂度的?
Redis内部数据结构
Redis 作为一个基于key/value的内存数据库,使用ANSI C语言实现,以其高性能和支持丰富的数据结构闻名于世,而其数据结构也是其高性能的基础。
在Redis内部,有非常多的数据结构:sds(简单动态字符串),list,intset(整数集合),hash(字典),zskiplist(跳跃表),ziplist(压缩表)等。
以redis3.2的正式版源码分析
sds简单动态字符串
Redis采用动态字符串的形式,用len记录长度,这样可以在 O(1) 的复杂度内获取字符串长度;根据不同的类型和字符串的长短,分别用不同类型的sdshdr,可以节约不少空间;将alloc和len分离,可以在一定的范围内节省分配内存所用的时间;在Redis中,运用了大量的指针移动技巧来获取void*对象,也提高了程序的运行效率。
c中char * 字符串的问题
char * 字符串以 \0 作为结尾,并不能高效地支持长度计算和追加(append)这两种操作:
1、每次计算字符串长度 strlen(s) 的复杂度为 O(n)
2、对字符串进行 N 次追加,必定需要对字符串进行 N 次内存重分配(realloc)。
sdshdr数据结构
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
类型 sds 是 char * 的别名(alias),而结构 sdshdr 则保存了 len 、 free 和 buf 三个属性。
sds对append操作的优化
当调用 SET 命令创建 sdshdr 时, sdshdr 的 free 属性为 0 , Redis 也没有为 buf 创建额外的空间。
但是,在执行 APPEND 之后, Redis 为 buf 创建了多于所需空间一倍的大小。
这样一来, 如果将来再次对同一个 sdshdr 进行追加操作, 只要追加内容的长度不超过 free 属性的值, 那么就不需要对 buf 进行内存重分配。
简单动态字符串 - Redis 设计与实现
https://redisbook.readthedocs.io/en/latest/internal-datastruct/sds.html
list双向链表
Redis中,list的实现是一个双端链表,这样可以方便的获取其前后的节点值,方便之后对节点的查找
链表结点:
typedef struct listNode { /*节点*/
struct listNode *prev;
struct listNode *next;
void *value; /*value用函数指针类型,决定了value可以是sds,list,set,dict等类型*/
} listNode;
链表结构:
typedef struct list { /*链表结构*/
listNode *head; /*头节点*/
listNode *tail; /*尾节点*/
void *(*dup)(void *ptr); /*复制节点*/
void (*free)(void *ptr); //释放节点
int (*match)(void *ptr, void *key); // 匹配节点,返回key值的index
unsigned long len; /*记录链表的长度*/
} list;
intset整数集合
当一个集合元素只有整数并且数量元素不多的时候,可以选择用整数集合来作为其底层实现。
typedef struct intset { /*整数集合的数据结构*/
uint32_t encoding; //编码方式
uint32_t length;
int8_t contents[];
} intset;
contents数组,它存储集合中的内容,并且以从小到大的顺序排列,并保证其没有重复的元素。
Redis内部数据结构的实现
https://blog.csdn.net/a6833916180/article/details/51596013
dict字典(哈希表)
字典结构是整个Redis的核心数据结构,基本上是其内部结构的缩影。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
dictEntry是最核心的字典结构的节点结构,它保存了key和value的内容;另外,next指针是为了解决hash冲突,字典结构的hash冲突解决方法是拉链法,对于hashcode重复的节点以链表的形式存储。
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask; /*hash表的掩码,总是size-1,用于计算hash表的索引值*/
unsigned long used;
} dictht;
dictht是节点dictEntry的持有者,将dictEntry结构串起来,table就是hash表,其实dictEntry *table[]这样的书写方式更容易理解些,size就是table数组的长度,used标志已有节点的数目。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
dict是最外层的字典结构的接口形式,type标志类型,privdata标志其私有数据,dict持有两个dictht结构,一个用来存储数据,一个用来在rehash时使用,rehashidx标志是否正在rehash(因为Redis中rehash是一个渐近的过程,正在rehash的时候rehashidx记录rehash的阶段,否则为-1)。
注:rehash是一个为了让负载因子(load_factor=used/size)控制在一个合理的范围内而重新分配内存和扩展结构的过程。
iterators是一个迭代器,用于记录当前迭代的数目。
Redis内部数据结构的实现
https://blog.csdn.net/a6833916180/article/details/51596013
zskiplist跳跃表
跳表是一种实现起来很简单,单层多指针的链表,它查找效率很高,堪比优化过的二叉平衡树,且比平衡树的实现,简单的多的多。
跳表在Redis中仅仅作为zset(有序集合)的底层实现出现
zadd的时间复杂度是O(log(n))
ziplist压缩表
ziplist是一个编码后的列表,是由一系列特殊编码的连续内存块组成的顺序型数据结构,特殊的设计使得内存操作非常有效率,此列表可以同时存放字符串和整数类型,列表可以在头尾各边支持推加和弹出操作在O(1)常量时间,但是,因为每次操作涉及到内存的重新分配释放,所以加大了操作的复杂性 。
typedef struct zlentry {
//prevrawlen为上一个数据结点的长度,prevrawlensize为记录该长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
//len为当前数据结点的长度,lensize表示表示当前长度表示所需的字节数
unsigned int lensize, len;
//数据结点的头部信息长度的字节数
unsigned int headersize;
//编码的方式
unsigned char encoding;
//数据结点的数据(已包含头部等信息),以字符串形式保存
unsigned char *p;
} zlentry;
压缩表之所以成为压缩表,是因为它起到了一定的压缩功能,对于其他的数据结构为了快速定位,使用了大量的指针结构,这样对于长度较大的数据优势明显,但是对于长度非常小的数据,比如说一个表里的每一个数据长度都很短,但是数据量并不小,这样的话,就会出现大量的指针结构,造成内存浪费,而压缩表则分配了一块连续内存来存储,就避免了大量的指针结构,节省了内存。另外,ziplist也使用了动态分配内存的方法,也一定程度上避免了内存的浪费。
Redis内部数据结构的实现
https://blog.csdn.net/a6833916180/article/details/51596013
Redis部署
Redis单例、主从模式、sentinel以及集群的配置方式及优缺点对比
https://mp.weixin.qq.com/s/jg4wzsiBGkm0B9SWYDGVbw
单点
master/slave主从模式
主从复制
Redis 支持简单且易用的主从复制(master-slave replication)功能, 该功能可以让从服务器(slave server)成为主服务器(master server)的精确复制品。
一个主服务器可以有多个从服务器。
不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个图状结构。
复制功能不会阻塞主服务器: 即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
slave启动时全量复制
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
即使有多个从服务器同时向主服务器发送 SYNC , 主服务器也只需执行一次 BGSAVE 命令, 就可以处理所有这些从服务器的同步请求。
slave运行中增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从复制原理
https://www.cnblogs.com/hepingqingfeng/p/7263782.html
部分重同步(2.8之后,psync)
从服务器可以在主从服务器之间的连接断开时进行自动重连, 在 Redis 2.8 版本之前, 断线之后重连的从服务器总要执行一次完整重同步(full resynchronization)操作, 但是从 Redis 2.8 版本开始, 从服务器可以根据主服务器的情况来选择执行完整重同步还是部分重同步(partial resynchronization)。
从 Redis 2.8 开始, 在网络连接短暂性失效之后, 主从服务器可以尝试继续执行原有的复制进程(process), 而不一定要执行完整重同步操作。
这个特性需要主服务器为被发送的复制流创建一个内存缓冲区(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个 复制偏移量(replication offset) 和一个 **主服务器 ID(master run id)**, 当出现网络连接断开时, 从服务器会重新连接, 并且向主服务器请求继续执行原来的复制进程:
- 如果从服务器记录的主服务器 ID 和当前要连接的主服务器的 ID 相同, 并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面, 那么主服务器会向从服务器发送断线时缺失的那部分数据, 然后复制工作可以继续执行。
- 否则的话, 从服务器就要执行完整重同步操作。
Redis 2.8 的这个部分重同步特性会用到一个新增的 PSYNC 内部命令, 而 Redis 2.8 以前的旧版本只有 SYNC 命令, 不过, 只要从服务器是 Redis 2.8 或以上的版本, 它就会根据主服务器的版本来决定到底是使用 PSYNC 还是 SYNC :
如果主服务器是 Redis 2.8 或以上版本,那么从服务器使用 PSYNC 命令来进行同步。
如果主服务器是 Redis 2.8 之前的版本,那么从服务器使用 SYNC 命令来进行同步。
复制(Replication)
http://doc.redisfans.com/topic/replication.html
redis不保证主从的强一致性
Redis采用了乐观复制(optimistic replication)的复制策略,容忍在一定时间内主从库的内容是不同的,但是两者的数据会最终同步。
具体来说,Redis在主从库之间复制数据的过程本身是异步的,这意味着,主库执行完客户端请求的命令后会立即将命令在主库的执行结果返回给客户端,并异步地将命令同步给从库,而不会等待从库接收到该命令后再返回给客户端。
这一特性保证了启用复制后主库的性能不会受到影响,但另一方面也会产生一个主从库数据不一致的时间窗口,当主库执行了一条写命令后,主库的数据已经发生的变动,然而在主库将该命令传送给从库之前,如果两个数据库之间的网络连接断开了,此时二者之间的数据就会是不一致的。
从这个角度来看,主库是无法得知某个命令最终同步给了多少个从库的,不过 Redis 提供了两个配置选项,来限制只有当数据至少同步给指定数量的从库时,主库才是可写的:
min-slaves-to-write 3
min-slaves-max-lag 10
min-slaves-to-write 表示只有当3个(或以上)的从库连接到主库时,主库才是可写的,否则会返回错误:
min-slaves-max-lag 表示允许从库最长失去连接的时间,如果从库最后与主库联系(即发送“replconf ack”命令)的时间小于这个值,则认为从库还在保持与主库的连接。
举个例子,按上面的配置,假设主库与3个从库相连,其中一个从库上一次与主库联系是 9 秒前,这时主库可以正常接受写入,一旦1秒过后这台从库依旧没有活动,则主库则认为目前连接的从库只有2个,从而拒绝写入。这一特性默认是关闭的,在分布式系统中,打开并合理配置该选项后可以降低主从架构中因为网络分区导致的数据不一致的问题。
07Redis入门指南笔记(主从复制、哨兵)
https://blog.csdn.net/gqtcgq/article/details/50273431
sentinel哨兵模式
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
启动sentinel
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统:
redis-sentinel /path/to/sentinel.conf
对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器:
redis-server /path/to/sentinel.conf –sentinel
两种方法都可以启动一个 Sentinel 实例。
启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。
如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
sentinel 选举与故障恢复过程
主观下线
Sentinel集群的每一个Sentinel节点会定时对redis集群的所有节点发心跳包检测节点是否正常。如果一个节点在 down-after-milliseconds 时间内没有回复Sentinel节点的心跳包,则该redis节点被该Sentinel节点主观下线。
如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为 主观下线(subjectively down,简称 SDOWN )。
sentinel down-after-milliseconds mymaster 60000
down-after-milliseconds 参数指定了 Sentinel 认为服务器已经断线所需的毫秒数。
客观下线
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为 客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。
将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
当节点被一个Sentinel节点记为主观下线时,并不意味着该节点肯定故障了,还需要Sentinel集群的其他Sentinel节点共同判断为主观下线才行。
该Sentinel节点会询问其他Sentinel节点,如果Sentinel集群中超过quorum数量的Sentinel节点认为该redis节点主观下线,则该redis客观下线。
如果客观下线的redis节点是从节点或者是Sentinel节点,则操作到此为止,没有后续的操作了;如果客观下线的redis节点为主节点,则开始故障转移,从从节点中选举一个节点升级为主节点。
Sentinel集群选举Leader
如果需要从redis集群选举一个节点为主节点,首先需要从Sentinel集群中选举一个Sentinel节点作为Leader。
每一个Sentinel节点都可以成为Leader,当一个Sentinel节点确认redis集群的主节点主观下线后,会请求其他Sentinel节点要求将自己选举为Leader。被请求的Sentinel节点如果没有同意过其他Sentinel节点的选举请求,则同意该请求(选举票数+1),否则不同意。
如果一个Sentinel节点获得的选举票数达到Leader最低票数(quorum和Sentinel节点数/2+1的最大值),则该Sentinel节点选举为Leader;否则重新进行选举。
sentinel leader 选举过程如下图:
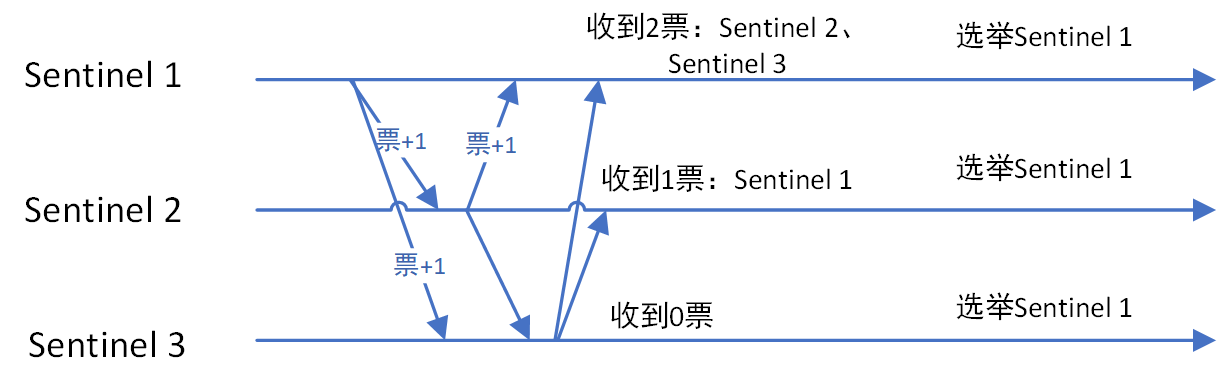
Sentinel Leader决定新主节点
当Sentinel集群选举出Sentinel Leader后,由Sentinel Leader从redis从节点中选择一个redis节点作为主节点:
1、过滤故障的节点
2、选择优先级 slave-priority 最大的从节点作为主节点,如不存在则继续
3、选择 复制偏移量(数据写入量的字节,记录写了多少数据。主服务器会把偏移量同步给从服务器,当主从的偏移量一致,则数据是完全同步)最大的从节点作为主节点,如不存在则继续
4、选择runid(redis每次启动的时候生成随机的runid作为redis的标识)最小的从节点作为主节点
sentinel选举是一种raft近似算法
Sentinel集群正常运行的时候每个节点epoch相同,当需要故障转移的时候会在集群中选出Leader执行故障转移操作。Sentinel采用了Raft协议实现了Sentinel间选举Leader的算法,不过也不完全跟论文描述的步骤一致。Sentinel集群运行过程中故障转移完成,所有Sentinel又会恢复平等。Leader仅仅是故障转移操作出现的角色。
选举流程
1、某个Sentinel认定master客观下线的节点后,该Sentinel会先看看自己有没有投过票,如果自己已经投过票给其他Sentinel了,在2倍故障转移的超时时间自己就不会成为Leader。相当于它是一个Follower。
2、如果该Sentinel还没投过票,那么它就成为Candidate。
3、和Raft协议描述的一样,成为Candidate,Sentinel需要完成几件事情
1)更新故障转移状态为start
2)当前epoch加1,相当于进入一个新term,在Sentinel中epoch就是Raft协议中的term。
3)更新自己的超时时间为当前时间随机加上一段时间,随机时间为1s内的随机毫秒数。
4)向其他节点发送is-master-down-by-addr命令请求投票。命令会带上自己的epoch。
5)给自己投一票,在Sentinel中,投票的方式是把自己master结构体里的leader和leader_epoch改成投给的Sentinel和它的epoch。
4、其他Sentinel会收到Candidate的is-master-down-by-addr命令。如果Sentinel当前epoch和Candidate传给他的epoch一样,说明他已经把自己master结构体里的leader和leader_epoch改成其他Candidate,相当于把票投给了其他Candidate。投过票给别的Sentinel后,在当前epoch内自己就只能成为Follower。
5、Candidate会不断的统计自己的票数,直到他发现认同他成为Leader的票数超过一半而且超过它配置的quorum(quorum可以参考《redis sentinel设计与实现》)。Sentinel比Raft协议增加了quorum,这样一个Sentinel能否当选Leader还取决于它配置的quorum。
6、如果在一个选举时间内,Candidate没有获得超过一半且超过它配置的quorum的票数,自己的这次选举就失败了。
7、如果在一个epoch内,没有一个Candidate获得更多的票数。那么等待超过2倍故障转移的超时时间后,Candidate增加epoch重新投票。
8、如果某个Candidate获得超过一半且超过它配置的quorum的票数,那么它就成为了Leader。
9、与Raft协议不同,Leader并不会把自己成为Leader的消息发给其他Sentinel。其他Sentinel等待Leader从slave选出master后,检测到新的master正常工作后,就会去掉客观下线的标识,从而不需要进入故障转移流程。
主从切换后如何知道master的ip?
主从切换后,master ip变了,如何知道往哪个里面写入?
java后台使用jedis来操作redis,配置一个JedisSentinelPool,传入sentinel哨兵集群中每个节点的地址,JedisSentinelPool初始化时会与所有sentinel沟通,确定当前sentinel集群所监视的master是哪一个。主从切换后通过sentinel集群还能读出新的master的地址,所以写入不会出错。
sentinel如何知道其他sentinel的存在?(发布订阅)
一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。
你无须为运行的每个 Sentinel 分别设置其他 Sentinel 的地址, 因为 Sentinel 可以通过发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。
与此类似, 你也不必手动列出主服务器属下的所有从服务器, 因为 Sentinel 可以通过询问主服务器来获得所有从服务器的信息。
- 每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的 sentinel:hello 频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。
- 每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的 sentinel:hello 频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。 当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。
- Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
- 在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
cluster集群模式(3.0之后)
redis 集群分为服务端集群和客户端分片,redis3.0 以上版本实现了集群机制,即服务端集群,3.0 以下使用客户端分片(Sharding)。
Redis Cluster 是一种服务器 Sharding 技术,3.0 版本开始正式提供。
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现
Redis Cluster 中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类 pre sharding 思路。对于每个进入 Redis 的键值对,根据 key 进行散列,分配到这 16384 个slot 中的某一个中。使用的 hash 算法也比较简单,就是 CRC16 后 16384 取模。
HASH_SLOT = CRC16(key) mod 16384
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个 slot 都对应一个 node 负责处理。
集群中的每个节点负责处理一部分哈希槽。 举个例子,一个集群可以有三个结点, 其中:
节点 A 负责处理 0 号至 5500 号哈希槽。
节点 B 负责处理 5501 号至 11000 号哈希槽。
节点 C 负责处理 11001 号至 16384 号哈希槽。
redis集群增减结点的操作步骤
当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入:
1、如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
2、与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
Redis 集群中的主从复制
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。
这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000 号的哈希槽。
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis 集群的一致性保证
Redis 集群不保证数据的强一致性(strong consistency): 在特定条件下, Redis 集群可能会丢失已经被执行过的写命令。
使用异步复制(asynchronous replication)是 Redis 集群可能会丢失写命令的其中一个原因。 考虑以下这个写命令的例子:
客户端向主节点 B 发送一条写命令。
主节点 B 执行写命令,并向客户端返回命令回复。
主节点 B 将刚刚执行的写命令复制给它的从节点 B1 、 B2 和 B3 。
如你所见, 主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。
如果真的有必要的话, Redis 集群可能会在将来提供同步地(synchronou)执行写命令的方法。
网络分裂
Redis 集群另外一种可能会丢失命令的情况是, 集群出现网络分裂(network partition), 并且一个客户端与至少包括一个主节点在内的少数(minority)实例被孤立。
举个例子, 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, 而 A1 、B1 、C1 分别为三个主节点的从节点, 另外还有一个客户端 Z1 。
假设集群中发生网络分裂, 那么集群可能会分裂为两方, 大多数(majority)的一方包含节点 A 、C 、A1 、B1 和 C1 , 而少数(minority)的一方则包含节点 B 和客户端 Z1 。
在网络分裂期间, 主节点 B 仍然会接受 Z1 发送的写命令:
如果网络分裂出现的时间很短, 那么集群会继续正常运行;
但是, 如果网络分裂出现的时间足够长, 使得大多数一方将从节点 B1 设置为新的主节点, 并使用 B1 来代替原来的主节点 B , 那么 Z1 发送给主节点 B 的写命令将丢失。
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
对于大多数一方来说, 如果一个主节点未能在节点超时时间所设定的时限内重新联系上集群, 那么集群会将这个主节点视为下线, 并使用从节点来代替这个主节点继续工作。
对于少数一方, 如果一个主节点未能在节点超时时间所设定的时限内重新联系上集群, 那么它将停止处理写命令, 并向客户端报告错误。
cluster集群的问题
存在如下限制:
- key批量操作支持有限。只支持具有相同slot值的key执行批量操作。
- 事务操作支持有限。只支持同一个节点上的多个key的事务操作。
- key是数据分区的最小粒度,因为不能讲一个大的键值对象,如hash,list等映射到不同的节点上。
- 不支持多数据库,单机下的Redis可以支持16个数据库,但集群之只能使用一个数据库空间,即db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
Failover的流程
一、主观下线
集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。
二、客观下线
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时,触发客观下线流程。
集群中的节点每次接收到其他节点的pfail状态,都会尝试触发客观下线,流程说明:
- 首先统计有效的下线报告数量,如果小于集群内持有槽的主节点总数的一半则退出。
- 当下线报告大于槽主节点数量一半时,标记对应故障节点为客观下线状态。
- 向集群广播一条fail消息,通知所有的节点将故障节点标记为客观下线,fail消息的消息体只包含故障节点的ID。
广播fail消息是客观下线的最后一步,它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效。
- 通知故障节点的从节点触发故障转移流程。
三、故障切换
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障切换流程。
1.资格检查
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过cluster-node-time*cluster-slave-validity-factor,则当前从节点不具备故障转移资格。参数cluster-slavevalidity-factor用于从节点的有效因子,默认为10。
2.准备选举时间
当从节点符合故障切换资格后,更新触发切换选举的时间,只有到达该时间后才能执行后续流程。
这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
3.发起选举
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
1> 更新配置纪元 epoch(相当于term加1)
2> 广播选举消息
在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。
4.选举投票
只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),因为每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复FAILOVER_AUTH_ACK消息作为投票,之后相同配置纪元内其他从节点的选举消息将忽略。
Redis集群没有直接使用从节点进行领导者选举,主要因为从节点数必须大于等于3个才能保证凑够N/2+1个节点,将导致从节点资源浪费。使用集群内所有持有槽的主节点进行领导者选举,即使只有一个从节点也可以完成选举过程。
5.替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
1> 当前从节点取消复制变为主节点。
2> 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己。
3> 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
故障切换时间
在介绍完故障发现和恢复的流程后,我们估算下故障切换时间:
1> 主观下线(pfail)识别时间=cluster-node-timeout。
2> 主观下线状态消息传播时间<=cluster-node-timeout/2。消息通信机制对超过cluster-node-timeout/2未通信节点会发起ping消息,消息体在选择包含哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数以上主节点的pfail报告从而完成故障发现。
3> 从节点转移时间<=1000毫秒。由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟1秒发起选举。通常第一次选举就会成功,所以从节点执行转移时间在1秒以内。
根据以上分析可以预估出故障转移时间,如下:
failover-time(毫秒) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000
因此,故障转移时间跟cluster-node-timeout参数息息相关,默认15秒。
Redis Cluster的相关参数
cluster-enabled <yes/no>:是否开启集群模式。
cluster-config-file
cluster-node-timeout
cluster-slave-validity-factor
cluster-migration-barrier
cluster-require-full-coverage <yes/no>:默认情况下当集群中16384个槽,有任何一个没有指派到节点时,整个集群是不可用的。对应在线上,如果某个主节点宕机,而又没有从节点的话,是不允许对外提供服务的。建议将该参数设置为no,避免某个主节点的故障导致其它主节点不可用。
深入理解Redis Cluster
https://www.cnblogs.com/ivictor/p/9762394.html
Redis集群方案应该怎么做?
https://www.zhihu.com/question/21419897
集群教程(redis3.0官方集群方案)
http://doc.redisfans.com/topic/cluster-tutorial.html
集群模式中哪些命令不能用?(集群模式如何兼容multi key操作)
Redis 集群是在多个 Redis 节点之间进行数据共享,它 不支持跨结点的 multi-key 操作(即执行的命令需要在多个Redis节点之间移动数据,比如Set类型的并集、交集等(除非这些key属于同一个node),即Cluster不能进行跨Nodes操作。
Redis为了兼容 multi-key 操作,提供了“hash tags”操作,每个key可以包含自定义的“tags”,在存储的时候根据tags计算此key应该映射到哪个node上。通过“hash tags”可以强制某些keys被保存到同一个节点上,便于进行“multi key”操作。
集群模式下无法使用 select 选库
集群模式下 keys * 命令只能匹配本机上的键
集群模式下如何使用pipeline
redis-trib.rb
Redis 3.0 及其之后的版本提供了 redis-cluster 集群支持,用于在多个redis节点间共享数据,以提高服务的可用性。
构建 redis-cluster 集群可以通过 redis-trib.rb 工具来完成。redis-trib.rb 是redis官方提供的一个集群管理工具,集成在redis安装包的 src 目录下。redis-trib.rb 封装了redis提供的集群命令,使用简单、便捷。
因为 redis-trib.rb 是由ruby语言编写的,所以使用该工具需要ruby语言环境的支持。
create 创建集群
check 检查集群
info 查看集群信息
fix 修复集群
reshard 在线迁移slot
rebalance 平衡集群节点slot数量
add-node 添加新节点
del-node 删除节点
set-timeout 设置节点的超时时间
call 在集群所有节点上执行命令
import 将外部redis数据导入集群
redis-trib.rb create 创建集群
redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
--replicas 参数指定集群中每个主节点配备几个从节点
redis-cluster集群至少需要3个可用节点。
主从节点选择及槽分配算法
主从节点选择及槽分配算法如下:
1> 把节点按照host分类,这样保证master节点能分配到更多的主机中。
2> 遍历host列表,从每个host列表中弹出一个节点,放入interleaved数组。直到所有的节点都弹出为止。
3> 将interleaved数组中前master个数量的节点保存到masters数组中。
4> 计算每个master节点负责的slot数量,16384除以master数量取整,这里记为N。
5> 遍历masters数组,每个master分配N个slot,最后一个master,分配剩下的slot。
6> 接下来为master分配slave,分配算法会尽量保证master和slave节点不在同一台主机上。对于分配完指定slave数量的节点,还有多余的节点,也会为这些节点寻找master。分配算法会遍历两次masters数组。
7> 第一次遍历master数组,在余下的节点列表找到replicas数量个slave。每个slave为第一个和master节点host不一样的节点,如果没有不一样的节点,则直接取出余下列表的第一个节点。
8> 第二次遍历是分配节点数除以replicas不为整数而多出的一部分节点。
redis-trib.rb check 检查集群状态
redis-trib.rb check 127.0.0.1:6379
指定任意一个节点即可。
redis-trib.rb info 查看集群信息
redis-trib.rb info 127.0.0.1:6383
./redis-trib.rb info 127.0.0.1:6383
127.0.0.1:6380 (3b27d00d...) -> 0 keys | 5462 slots | 1 slaves.
127.0.0.1:6381 (d874f003...) -> 1 keys | 5461 slots | 1 slaves.
127.0.0.1:6379 (bc775f9c...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
redis-trib.rb reshard 在线迁移slot
redis-trib.rb reshard 127.0.0.1:6379 指定任意一个节点即可。
这是一个交互命令
1、它首先会提示需要迁移多个槽
How many slots do you want to move (from 1 to 16384)? 200
输入200。
2、接着它会提示需要将槽迁移到哪个节点
What is the receiving node ID? 3b27d00d13706a032a92ff6b0a914af272dcaaf2
这里必须写节点ID。
3、紧跟着它会提示槽从哪些节点中迁出。
Please enter all the source node IDs.
Type ‘all’ to use all the nodes as source nodes for the hash slots.
Type ‘done’ once you entered all the source nodes IDs.
如果指定为all,则待迁移的槽在剩余节点中平均分配,在这里,127.0.0.1:6379和127.0.0.1:6381各迁移100个槽出来。
也可从指定节点中迁出,这个时候,必须指定源节点的节点ID,最后以done结束
redis-trib.rb rebalance 平衡slot
平衡集群节点slot数量
redis-trib.rb del-node 删除节点
redis-trib.rb del-node host:port node_id
在删除节点之前,其对应的槽必须为空,所以,在进行节点删除动作之前,必须使用redis-trib.rb reshard将其迁移出去。
需要注意的是,如果某个节点的槽被完全迁移出去,其对应的slave也会随着更新,指向迁移的目标节点。
redis-trib add-node 添加新节点
redis-trib add-node new_host:new_port existing_host:existing_port --slave --master-id <arg>
new_host:new_port:待添加的节点,必须确保其为空或不在其它集群中。
existing_host:existing_port:集群中任意一个节点的地址。
如果添加的是主节点,只需指定源节点和目标节点的地址即可。
redis-trib.rb add-node 127.0.0.1:6379 127.0.0.1:6384
如果添加的是从节点,其语法如下,
redis-trib.rb add-node –slave –master-id f413fb7e6460308b17cdb71442798e1341b56cbc 127.0.0.1:6379 127.0.0.1:6384
所以,线上建议使用redis-trib.rb添加新节点,因为其会对新节点的状态进行检查。如果手动使用cluster meet命令加入已经存在于其它集群的节点,会造成被加入节点的集群合并到现有集群的情况,从而造成数据丢失和错乱,后果非常严重,线上谨慎操作。
redis-trib.rb call 在集群所有节点上执行命令
redis-trib.rb call host:port command arg arg .. arg
使用redis-trib.rb call在所有节点上执行keys命令
./redis-trib.rb call 127.0.0.1:6379 keys \*
结果
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
master/slave 上的key数组是相同的。
cluster nodes 查看集群节点状态
查看节点状态,输出是空格分割的CSV字符串,每行代表集群中的一个节点。
例如
07c37dfeb235213a872192d90877d0cd55635b91 127.0.0.1:30004 slave e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 0 1426238317239 4 connected
67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1 127.0.0.1:30002 master - 0 1426238316232 2 connected 5461-10922
292f8b365bb7edb5e285caf0b7e6ddc7265d2f4f 127.0.0.1:30003 master - 0 1426238318243 3 connected 10923-16383
6ec23923021cf3ffec47632106199cb7f496ce01 127.0.0.1:30005 slave 67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1 0 1426238316232 5 connected
824fe116063bc5fcf9f4ffd895bc17aee7731ac3 127.0.0.1:30006 slave 292f8b365bb7edb5e285caf0b7e6ddc7265d2f4f 0 1426238317741 6 connected
e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 127.0.0.1:30001 myself,master - 0 0 1 connected 0-5460
<id> <ip:port> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>
节点ID, ip:port, master/slave标志,master_id(只slave有), 最后发送PING的时间, 最后接收PONG的时间, epoch,连接状态,节点负责处理的槽(只master有)。
id: 节点ID,是一个40字节的随机字符串,这个值在节点启动的时候创建,并且永远不会改变(除非使用CLUSTER RESET HARD命令)。
ip:port: 客户端与节点通信使用的地址.
flags: 逗号分割的标记位,可能的值有: myself, master, slave, fail?, fail, handshake, noaddr, noflags. 下一部分将详细介绍这些标记.
master: 如果节点是slave,并且已知master节点,则这里列出master节点ID,否则的话这里列出”-“。
ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过.
pong-recv: 最近一次收到pong的时间,使用unix时间戳表示.
config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。
link-state: node-to-node集群总线使用的链接的状态,我们使用这个链接与集群中其他节点进行通信.值可以是 connected 和 disconnected.
slot: 哈希槽值或者一个哈希槽范围. 从第9个参数开始,后面最多可能有16384个 数(limit never reached)。代表当前节点可以提供服务的所有哈希槽值。如果只是一个值,那就是只有一个槽会被使用。如果是一个范围,这个值表示为起始槽-结束槽,节点将处理包括起始槽和结束槽在内的所有哈希槽。
reids 集群客户端
redis-cli 对集群的支持是非常基本的, 所以它总是依靠 Redis 集群节点来将它转向(redirect)至正确的节点。
一个真正的(serious)集群客户端应该做得比这更好: 它应该用缓存记录起哈希槽与节点地址之间的映射(map), 从而直接将命令发送到正确的节点上面。
这种映射只会在集群的配置出现某些修改时变化, 比如说, 在一次故障转移(failover)之后, 或者系统管理员通过添加节点或移除节点来修改了集群的布局(layout)之后, 诸如此类。
集群教程
http://redisdoc.com/topic/cluster-tutorial.html
redis3.0之前的集群方案:客户端sharding
Redis 3正式推出了官方集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。多Redis实例服务,比单Redis实例要复杂的多,这涉及到定位、协同、容错、扩容等技术难题。
redis3.0之前一般使用客户端分片(Sharding)来实现集群。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。
庆幸的是,java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
1、采用 一致性哈希算法(consistent hashing) ,将key和节点name同时hashing,然后进行映射匹配,采用的哈希算法是 MURMUR_HASH。采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
2、为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟化出160个 虚拟节点 进行散列。根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
3、ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
客户端sharding扩容方案-presharding
Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。
当然,Redis Sharding这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,毕竟还是会有key匹配不到而丢失,这时需要键值迁移。
作为轻量级客户端sharding,处理Redis键值迁移是不现实的,这就要求应用层面允许Redis中数据丢失或从后端数据库重新加载数据。但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。有没有其它手段改善这种情况?
Redis作者给出了一个比较讨巧的办法–presharding,即预先根据系统规模尽量部署好多个Redis实例,这些实例占用系统资源很小,一台物理机可部署多个,让他们都参与sharding,当需要扩容时,选中一个实例作为主节点,新加入的Redis节点作为从节点进行数据复制。数据同步后,修改sharding配置,让指向原实例的Shard指向新机器上扩容后的Redis节点,同时调整新Redis节点为主节点,原实例可不再使用。
presharding是预先分配好足够的分片,扩容时只是将属于某一分片的原Redis实例替换成新的容量更大的Redis实例。参与sharding的分片没有改变,所以也就不存在key值从一个区转移到另一个分片区的现象,只是将属于同分片区的键值从原Redis实例同步到新Redis实例。
Redis集群方案应该怎么做?
https://www.zhihu.com/question/21419897
redis集群(Sharding)和在线扩容(Pre-Sharding)
https://blog.csdn.net/rosanu_blog/article/details/68066756
redis代理中间件twemproxy
twitter / twemproxy
https://github.com/twitter/twemproxy
Redis代理中间件twemproxy就是这样一种利用中间件做sharding的技术。
twemproxy处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
存储
redis持久化
Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为“全持久化模式”)。
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁 盘上,当redis重启后,可以从磁盘中恢复数据。
redis提供两种方式进行持久化:
一种是RDB持久化(原理是将Reids在内存中的数据库记录定时 dump 到磁盘上的RDB持久化),
另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)。
redis还可以同时使用AOF持久化和RDB持久化,在这种情况下,当redis重启时,它会有限使用AOF文件来还原数据集,因为AOF文件保存的数据集通常比RDB文件所保存的数据集更加完
RDB持久化(磁盘快照)
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
RDB持久化配置
注意:save的两个条件都要满足才dump快照
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
dbfilename "dump.rdb" #持久化文件名称
dir "/data/dbs/redis/6381" #持久化数据文件存放的路径
配置文件修改需要重启redis服务,我们还可以在命令行里进行配置,即时生效,服务器重启后需重新配置
save(阻塞)和bgsave(异步非阻塞)
而RDB持久化也分两种:SAVE和BGSAVESAVE 是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。BGSAVE 属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
bgsave命令
background save
在后台异步(Asynchronously)保存当前数据库的数据到磁盘。
BGSAVE 命令执行之后立即返回 OK ,然后 Redis fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出。
客户端可以通过 LASTSAVE 命令查看相关信息,判断 BGSAVE 命令是否执行成功。
AOF持久化
AOF(Append Only File) 持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
AOF相关配置项:
dir "/data/dbs/redis/6381" #AOF文件存放目录
appendonly yes #开启AOF持久化,默认关闭
appendfilename "appendonly.aof" #AOF文件名称(默认)
appendfsync no #AOF持久化策略,有三个选项:always、everysec和no
auto-aof-rewrite-percentage 100 #触发AOF文件重写的条件(默认)
auto-aof-rewrite-min-size 64mb #触发AOF文件重写的条件(默认)
要弄明白上面几个配置就得从AOF的实现去理解,AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。
当reids开启AOF后,服务端每执行一次写操作(如set、sadd、rpush)就会把该条命令追加到一个单独的AOF缓冲区的末尾,这就是命令追加;然后把AOF缓冲区的内容写入AOF文件里。
看上去第二步就已经完成AOF持久化了那第三步是干什么的呢?这就需要从系统的文件写入机制说起:一般我们现在所使用的操作系统,为了提高文件的写入效率,都会有一个写入策略,即当你往硬盘写入数据时,操作系统不是实时的将数据写入硬盘,而是先把数据暂时的保存在一个内存缓冲区里,等到这个内存缓冲区的空间被填满或者是超过了设定的时限后才会真正的把缓冲区内的数据写入硬盘中。也就是说当redis进行到第二步文件写入的时候,从用户的角度看是已经把AOF缓冲区里的数据写入到AOF文件了,但对系统而言只不过是把AOF缓冲区的内容放到了另一个内存缓冲区里而已,之后redis还需要进行文件同步把该内存缓冲区里的数据真正写入硬盘上才算是完成了一次持久化。而何时进行文件同步则是根据配置的appendfsync来进行。
何时进行AOF持久化(always,everysec,no)
appendfsync有三个选项:always、everysec和no:
always(每个写操作)
1、选择always的时候服务器会在每执行一个事件就把AOF缓冲区的内容强制性的写入硬盘上的AOF文件里,可以看成你每执行一个redis写入命令就往AOF文件里记录这条命令,这保证了数据持久化的完整性,但效率是最慢的,却也是最安全的;
everysec(每秒)
2、配置成everysec的话服务端每执行一次写操作(如set、sadd、rpush)也会把该条命令追加到一个单独的AOF缓冲区的末尾,并将AOF缓冲区写入AOF文件,然后每隔一秒才会进行一次文件同步把内存缓冲区里的AOF缓存数据真正写入AOF文件里,这个模式兼顾了效率的同时也保证了数据的完整性,即使在服务器宕机也只会丢失一秒内对redis数据库做的修改;
no(由系统决定)
3、配置成no则意味redis数据库里的数据就算丢失你也可以接受,它也会把每条写命令追加到AOF缓冲区的末尾,然后写入文件,但什么时候进行文件同步真正把数据写入AOF文件里则由系统自身决定,即当内存缓冲区的空间被填满或者是超过了设定的时限后系统自动同步。这种模式下效率是最快的,但对数据来说也是最不安全的,如果redis里的数据都是从后台数据库如mysql中取出来的,属于随时可以找回或者不重要的数据,那么可以考虑设置成这种模式。
AOF重写(bgrewriteaof)
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。
举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。
然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。
执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。
Redis 2.2 需要自己手动执行 BGREWRITEAOF 命令; Redis 2.4 则可以自动触发 AOF 重写, 具体信息请查看 2.4 的示例配置文件。
RDB与AOF对比及合理选择持久化策略
RDB 和 AOF ,我应该用哪一个?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。)
redis——持久化篇
https://www.cnblogs.com/dengtr/p/5085287.html
redis持久化的几种方式
https://www.cnblogs.com/AndyAo/p/8135980.html
redis两种持久化方式的优缺点
https://www.cnblogs.com/ssssdy/p/7132856.html
MISCONF Redis is configured to save RDB snapshots…
jedis 报错如下
redis.clients.jedis.exceptions.JedisDataException: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
Redis被配置为保存数据库快照,但它目前不能持久化到硬盘。用来修改集合数据的命令不能用。请查看Redis日志的详细错误信息。
解决
将 stop-writes-on-bgsave-error 设置为 no
#进入redis
redis-cli -h 127.0.0.1 -p 6379
#设置
config set stop-writes-on-bgsave-error no
redis过期策略
redis过期时间设置(expire)与查看(ttl)
expire key second 为key设置过期时间
返回1表明设置成功,返回0表明key不存在或者不能成功设置过期时间。
此外还有如下几个命令可设置过期时间:
EXPIRE key seconds //将key的生存时间设置为ttl秒
PEXPIRE key milliseconds //将key的生成时间设置为ttl毫秒
EXPIREAT key timestamp //将key的过期时间设置为timestamp所代表的的秒数的时间戳
PEXPIREAT key milliseconds-timestamp //将key的过期时间设置为timestamp所代表的的毫秒数的时间戳
TTL key
以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
redis有3种过期策略:
每个key定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
没人用
惰性删除(访问key时再删除)
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
对于惰性删除而言,并不是只有获取key的时候才会检查key是否过期,在某些设置key的方法上也会检查(eg.setnx key2 value2:该方法类似于memcached的add方法,如果设置的key2已经存在,那么该方法返回false,什么都不做;如果设置的key2不存在,那么该方法设置缓存key2-value2。假设调用此方法的时候,发现redis中已经存在了key2,但是该key2已经过期了,如果此时不执行删除操作的话,setnx方法将会直接返回false,也就是说此时并没有重新设置key2-value2成功,所以对于一定要在setnx执行之前,对key2进行过期检查)
周期性删除
含义:每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用–处理”定时删除”的缺点
定期删除过期key–处理”惰性删除”的缺点
缺点
在内存友好方面,不如”定时删除”
在CPU时间友好方面,不如”惰性删除”
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
定时删除和定期删除为主动删除:Redis会定期主动淘汰一批已过去的key
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
惰性删除为redis服务器内置策略
定期删除可以通过:
第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
Redis学习笔记–Redis数据过期策略详解
http://www.cnblogs.com/xuliangxing/p/7151812.html
关于Redis数据过期策略
https://www.cnblogs.com/chenpingzhao/p/5022467.html
redis内存淘汰策略
maxmemory开启内存淘汰策略
maxmemory bytes 配置限制使用的最大内存,也就是说配置 maxmemory 后会开启内存淘汰功能
maxmemory 为 0 的时候表示我们对 Redis 的内存使用没有限制。
当我们程序达到最大值时, Redis使用了多种策略进行置换.Redis建议最大内存设置为物理内存的一半。
maxmemory-policy内存淘汰策略
maxmemory-policy noeviction 配置内存淘汰策略:
Redis提供了下面几种淘汰策略供用户选择,其中默认的策略为 noeviction 策略:
noeviction:不淘汰,当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
allkeys-lru:在主键空间中,优先移除最近未使用的key。
volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
allkeys-random:在主键空间中,随机移除某个key。
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
下面看看几种策略的适用场景:
allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction。
另外,volatile-lru 策略和 volatile-random 策略适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个Redis实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存。
Redis中的LRU实现(近似LRU)
LRU(Least Recently Used),即最近最少使用
Redis使用的是近似LRU算法,它跟常规的LRU算法还不太一样。近似LRU算法通过随机采样法淘汰数据,每次随机出5(默认)个key,从里面淘汰掉最近最少使用的key。
可以通过 maxmemory-samples 参数修改采样数量:
例:maxmemory-samples 10
maxmenory-samples 配置的越大,淘汰的结果越接近于严格的LRU算法
Redis为了实现近似LRU算法,给每个key增加了一个额外增加了一个24bit的字段,用来存储该key最后一次被访问的时间。
Redis3.0对近似LRU的优化
Redis3.0 对近似LRU算法进行了一些优化。
新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。
当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久没被访问)的 key 淘汰掉就行。
Redis4.0新增LFU算法
LFU算法是Redis4.0里面新加的一种淘汰策略。它的全称是 Least Frequently Used,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。
LFU一共有两种策略:
volatile-lfu:在设置了过期时间的key中使用LFU算法淘汰key
allkeys-lfu:在所有的key中使用LFU算法淘汰数据
设置使用这两种淘汰策略跟前面讲的一样,不过要注意的一点是这两周策略只能在Redis4.0及以上设置,如果在Redis4.0以下设置会报错
如何选择合适的内存淘汰策略?
开发者还需要根据自身系统特征,正确选择淘汰策略:
在Redis中,数据有一部分访问频率较高,其余部分访问频率较低,或者无法预测数据的使用频率时,设置 allkeys-lru 是比较合适的。
如果所有数据访问概率大致相等时,可以选择 allkeys-random
如果研发者需要通过设置不同的 ttl 来判断数据过期的先后顺序,此时可以选择 volatile-ttl 策略。
如果希望一些数据能长期被保存,而一些数据可以被淘汰掉时,选择 volatile-lru 或 volatile-random 都是比较不错的。
由于设置 expire 会消耗额外的内存,如果计划避免 Redis 内存在此项上的浪费,可以选用 allkeys-lru 策略,这样就可以不再设置过期时间,高效利用内存了。
主键空间和过期键空间
主键空间和设置了过期时间的键空间,举个例子,假设我们有一批键存储在Redis中,则有那么一个哈希表用于存储这批键及其值,如果这批键中有一部分设置了过期时间,那么这批键还会被存储到另外一个哈希表中,这个哈希表中的值对应的是键被设置的过期时间。
设置了过期时间的键空间为主键空间的子集。
Redis 内存淘汰机制
https://www.cnblogs.com/changbosha/p/5849982.html
其他特性
redis事务
redis的事务中,一次执行多条命令,本质是一组命令的集合,一个事务中所有的命令将被序列化,即按顺序执行而不会被其他命令插入
在redis中,事务的作用就是在一个队列中一次性、顺序性、排他性的执行一系列的命令。
常用的关于事务的命令有:
- MULTI:使用该命令,标记一个事务块的开始,通常在执行之后会回复OK,(但不一定真的OK),这个时候用户可以输入多个操作来代替逐条操作,redis会将这些操作放入队列中。
- EXEC:执行这个事务内的所有命令
- DISCARD:放弃事务,即该事务内的所有命令都将取消
- WATCH:监控一个或者多个key,如果这些key在提交事务(EXEC)之前被其他用户修改过,那么事务将执行失败,需要重新获取最新数据重头操作(类似于乐观锁)。
- UNWATCH:取消WATCH命令对多有key的监控,所有监控锁将会被取消。
redis事务不支持回滚
如下,事务中某条命令执行时错误:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET key 1
QUEUED
127.0.0.1:6379> SADD key 2 //用集合命令sadd操作string类型key出现错误
QUEUED
127.0.0.1:6379> SET key 3 //错误之后的命令依然会继续执。
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
127.0.0.1:6379> GET key //键值被错误命令之后的命令修改
"3"
但是提交事务的时候会发现,这条错误命令确实没有执行,但是其他正确的命令却执行,这是为什么的?
原因是在redis中,对于一个存在问题的命令,如果在入队的时候就已经出错,整个事务内的命令将都不会被执行(其后续的命令依然可以入队),如果这个错误命令在入队的时候并没有报错,而是在执行的时候出错了,那么redis默认跳过这个命令执行后续命令。
也就是说,redis只实现了部分事务。不支持回滚。
为什么redis事务不支持回滚?
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
为什么 Redis 不支持回滚(roll back)
http://doc.redisfans.com/topic/transaction.html#redis-roll-back
用watch命令实现乐观锁
redis的锁CAS(check and set)类似于乐观锁,redis的实现原理是使用watch进行监视一个(或多个)数据,如果在事务提交之前数据发生了变化(估计使用了类似于乐观锁的标记),那么整个事务将提交失败。
我们可以举一个例子,我们开启两个终端,模拟两个人的操作,设置一条数据为count,初始时100,现在A对其进行监控,并且为count增加20。在没有提交之前,B也获取了这个count,为其减少50,那么这个时候A如果提交事务,会出现失败提示。可以看到,在A对数据的修改过程中,B对数据进行了修改,那么这条数据的“标记”就发生了变化,已经不是当初A取出数据的时候的标记了,这样,A的事务也就提交失败了。
Redis入门之浅谈redis事务
https://blog.csdn.net/candy_rainbow/article/details/52810440
Redis的事务功能详解
https://www.cnblogs.com/kyrin/p/5967620.html
Redis发布订阅
SUBSCRIBE, UNSUBSCRIBE 和 PUBLISH 三个命令实现了发布与订阅信息泛型(Publish/Subscribe messaging paradigm), 在这个实现中, 发送者(发送信息的客户端)不是将信息直接发送给特定的接收者(接收信息的客户端), 而是将信息发送给频道(channel), 然后由频道将信息转发给所有对这个频道感兴趣的订阅者。
发送者无须知道任何关于订阅者的信息, 而订阅者也无须知道是那个客户端给它发送信息, 它只要关注自己感兴趣的频道即可。
比如说, 要订阅频道 foo 和 bar , 客户端可以使用频道名字作为参数来调用 SUBSCRIBE 命令:
redis> SUBSCRIBE foo bar
当有客户端发送信息到这些频道时, Redis 会将传入的信息推送到所有订阅这些频道的客户端里面。
正在订阅频道的客户端不应该发送除 SUBSCRIBE 和 UNSUBSCRIBE 之外的其他命令。 其中, SUBSCRIBE 可以用于订阅更多频道, 而 UNSUBSCRIBE 则可以用于退订已订阅的一个或多个频道。
SUBSCRIBE 和 UNSUBSCRIBE 的执行结果会以信息的形式返回, 客户端可以通过分析所接收信息的第一个元素, 从而判断所收到的内容是一条真正的信息, 还是 SUBSCRIBE 或 UNSUBSCRIBE 命令的操作结果。
publish channel message
PUBLISH channel message 将信息 message 发送到指定的频道 channel
时间复杂度:O(N+M),其中 N 是频道 channel 的订阅者数量,而 M 则是使用模式订阅(subscribed patterns)的客户端的数量。
返回值:接收到信息 message 的订阅者数量。
# 对没有订阅者的频道发送信息
redis> publish bad_channel "can any body hear me?"
(integer) 0
# 向有一个订阅者的频道发送信息
redis> publish msg "good morning"
(integer) 1
# 向有多个订阅者的频道发送信息
redis> publish chat_room "hello~ everyone"
(integer) 3
subscribe channel
SUBSCRIBE channel [channel ...] 订阅给定的一个或多个频道的信息。
时间复杂度:O(N),其中 N 是订阅的频道的数量。
unsubscribe channel
UNSUBSCRIBE [channel [channel ...]] 指示客户端退订给定的频道。
如果没有频道被指定,也即是,一个无参数的 UNSUBSCRIBE 调用被执行,那么客户端使用 SUBSCRIBE 命令订阅的所有频道都会被退订。在这种情况下,命令会返回一个信息,告知客户端所有被退订的频道。
时间复杂度:O(N) , N 是客户端已订阅的频道的数量。
发布订阅演示实例
1、打开 redis 连接1,直接向一个全新的 channel 名字发送一个消息就创建了这个 channel
> publish new_channel 'new_channel'
0
返回 0 表示当前有 0 个消费者监听
2、另开一个 redis 连接2,订阅这个 channel
> subscribe new_channel
subscribe
new_channel
1
返回订阅的 频道 名字和订阅的频道数量
3、在 redis 连接1 中,向 new_channel 发送消息
> publish new_channel '能听到吗'
1
则 redis 连接2 中立即会收到此消息:
message
new_channel
能听到吗
发布与订阅(pub/sub)
http://doc.redisfans.com/topic/pubsub.html
Redis配置
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf
可以通过 config 命令查看或设置配置项。
config get读取配置
使用 config get 命令读取配置,语法:config get CONFIG_SETTING_NAME
其中 CONFIG_SETTING_NAME 为配置项名称,可包含通配符
例如 config get * 获取所有配置项,config get *log* 获取所有包含log的配置项
config set修改配置
可以通过修改 redis.conf 文件或使用 config set 命令修改配置,语法:config set CONFIG_SETTING_NAME NEW_CONFIG_VALUE
redis集群中各节点配置是独立的
常用配置项
daemonize
daemonize no
Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
pidfile
pidfile /var/run/redis.pid
当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
port
port 6379
指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
bind
bind 127.0.0.1
绑定的主机地址
timeout
timeout 300
当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
logfile
logfile stdout
指定日志文件名,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
databases
databases 16
设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
dir
dir ./
指定本地数据库存放目录
dbfilename
dbfilename dump.rdb
指定本地数据库文件名,默认值为dump.rdb
slaveof
slaveof <masterip> <masterport>
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
stop-writes-on-bgsave-error
默认情况下,当 RDB 快照打开且最近一次 bgsave 失败时,redis会停止接受写操作并报错。
这是一种数据安全考虑,因为此时无法写入抛出的异常会使用户意识到数据无法正确的持久化到磁盘上,假如没有这种机制,用户持续写入而无法持久化当redis重启时会有数据丢失。
当 bgsave 进程可正常进行持久化操作后,redis也会自动允许写入。
如果你不在乎持久化数据丢失,想要 redis 在无法进行数据持久化的情况下依然可以正常工作,可以将此选项设置为 no
redis慢查询
slowlog-log-slower-than 慢查询阈值
slowlog-log-slower-than 慢查询阈值,单位微秒,默认值 10000 微秒,即 10 毫秒
127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "10000"
slowlog-max-len 慢查询历史条数
slowlog-max-len 慢查询日志最多存储多少条,超过后最早的被删除
127.0.0.1:6379> config get slowlog-max-len
1) "slowlog-max-len"
2) "128"
修改慢查询阈值(默认10毫秒)
重设慢查询告警阈值为1秒 config set slowlog-log-slower-than 1000000
127.0.0.1:6379> config set slowlog-log-slower-than 1000000
OK
127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "1000000"
slowlog len 查看慢查询个数
slowlog len 查询当前慢查询队列长度,即慢查询条数
https://redis.io/commands/slowlog-len
127.0.0.1:6379> slowlog len
(integer) 80
slowlog get n 查看redis慢查询日志列表
slowlog get n 查询慢查询日志,默认查10条
https://redis.io/commands/slowlog-get
每个log的6个字段分别是:
- 唯一性(unique)的日志标识符
- 被记录命令的执行时间点,以 UNIX 时间戳格式表示
- 查询执行时间,以微秒为单位
- 执行的命令,命令和多个参数以数组的形式排列
- 客户端ip和端口
- 客户端名字(通过 CLIENT SETNAME 设置了才有)
127.0.0.1:6379> slowlog get 3
1) 1) (integer) 79
2) (integer) 1640078160
3) (integer) 45025
4) 1) "KEYS"
2) "prefix*"
5) "10.233.75.0:59070"
6) ""
2) 1) (integer) 78
2) (integer) 1640071500
3) (integer) 44705
4) 1) "KEYS"
2) "prefix*"
5) "10.233.72.0:53178"
6) ""
3) 1) (integer) 77
2) (integer) 1640071350
3) (integer) 48283
4) 1) "KEYS"
2) "prefix*"
5) "10.233.111.0:52446"
6) ""
slowlog reset 清理慢查询日志
清理慢查询日志队列
https://redis.io/commands/slowlog-reset
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0
redis集群各节点需单独清理
redis 集群中多个节点需要分别处理,集群节点的配置是各自独立的
安装Redis
Mac 安装 RedisDesktopManager
新版 Redis Desktop Manager(RDM) 要自己编译才可以(除非你在官网上进行付费),通过 brew 安装的也只能安装 0.8 的版本,所有最新的版本需要我们自己编译。
Mac OS X下编译Redis Desktop Manager(RDM)
https://onew.me/2018/03/29/mac-compile-RDM/index.html
如果不想自己编译,这里有编译好的mac dmg版本
RedisDesktopManager-Mac
https://github.com/onewe/RedisDesktopManager-Mac
Redis Desktop Manager
https://redisdesktop.com/download
Intel/M1 Mac Brew 安装 Redis
brew install redis
安装目录:
- Intel Mac 安装目录 /usr/local/Cellar/redis/6.2.4
- M1 Mac 安装目录 /opt/homebrew/Cellar/redis/6.2.6
使用 brew services 启动 redis 服务并添加开机启动:brew services start redis
前台启动:
Intel Mac 上 redis-server /usr/local/etc/redis.conf
M1 Mac 上 /opt/homebrew/opt/redis/bin/redis-server /opt/homebrew/etc/redis.conf
推荐使用 brew services 启动,可自动添加开机启动,避免每次重启后还要再启动redis
redis-server 命令
redis-server 是 redis 服务端的启动程序,也就是 reids 服务端的命令行。
--port 配置端口--slaveof 将当前服务器转变为指定服务器的从属服务器--loglevel 配置日志级别--sentinel 以哨兵模式运行-v 显示版本号
实例:
./redis-server [/path/to/redis.conf] [options]
./redis-server - (read config from stdin)
./redis-server -v or --version
./redis-server -h or --help
./redis-server --test-memory <megabytes>
实例:
1、用默认配置文件启动 redis
./redis-server
2、指定配置文件启动 redis
注意:为了能顺利读取配置文件,Redis 启动时要将配置文件路径作为第一个参数
./redis-server /etc/myredis.conf
3、指定端口启动 redis
./redis-server --port 7777
4、作为 slave 服务启动 redis
./redis-server --port 7777 --slaveof 127.0.0.1 8888
5、启动 redis 并配置日志类级别:
./redis-server /etc/myredis.conf --loglevel verbose
6、以哨兵模式运行 redis
./redis-server /etc/sentinel.conf --sentinel
redis-cli 命令
-h <hostname> 指定host,默认是 127.0.0.1-p <port> 指定端口,默认6379-a <password> 指定连接密码,可以使用 REDISCLI_AUTH 环境变量更安全的传递密码-n <db> 指定数据库编号,相当于select db
redis-cli 连接localhost:6379
redis-cli,redis-cli 命令不加任何参数,默认用 6379 端口连接本地redis服务
redis-cli -h host -p port -a passwd 连接指定地址
redis-cli -h host -p port -a password,连接远程redis服务器
redis-cli 后 auth passwd 认证登录
可以先 redis-cli -h host -p port 无密码登录,然后 auth passwd 输入密码认证,和登录时用 -a passwd 指定密码相同。
redis-cli -h host -p port command 连接并执行命令
redis-cli -h host -p port command,直接得到命令的返回结果
redis-cli -h host -n 1 command 连接并在指定db上执行命令
redis-cli -h host -n 1 command 连接并在指定db上执行命令
redis-cli -c 连接redis集群
-c 开启集群模式。
开启集群模式后,client 会根据 server 返回的 -ASK 和 -MOVED 命令进行重定向(redirection)。
不加 -c 也可以直接连接 redis 集群中的某个节点,但可能报 (error) MOVED 1127 127.0.0.2:8110 这种错误。
redis-cli -c -h localhost -p 8479 以集群模式连接到集群中的一个 redis 结点上。
$ redis-cli -c -h localhost -p 8479
localhost:8479> set redis-cluster-test 121
OK
localhost:8479> get redis-cluster-test
"121"
localhost:8479> set redis-cluster-test2 121111
-> Redirected to slot [9200] located at localhost:8579
OK
localhost:8579> set redis-cluster-test3 1lele
-> Redirected to slot [13265] located at localhost:8679
OK
redis-cli 对集群的支持是非常基本的, 所以它总是依靠 Redis 集群节点来将它转向(redirect)至正确的节点。
一个真正的(serious)集群客户端应该做得比这更好: 它应该用缓存记录起哈希槽与节点地址之间的映射(map), 从而直接将命令发送到正确的节点上面。
这种映射只会在集群的配置出现某些修改时变化, 比如说, 在一次故障转移(failover)之后, 或者系统管理员通过添加节点或移除节点来修改了集群的布局(layout)之后, 诸如此类。
redis-cli –cluster call 集群全部节点上执行命令
redis-cli --cluster call host:port command arg arg .. arg 在集群的所有节点执行相关命令
例如 redis-cli --cluster call localhost:6379 keys "user-*" 在集群全部节点执行 keys 命令
在全部节点删除模糊匹配keys
1、先连接任意节点,查询 keys
redis-cli --cluster call localhost:6379 keys "user-*"
>>> Calling keys user-*
127.0.0.1:6379: user-336
user-9
127.0.0.2:6379: user-75
user-10
2、xargs 连接 del 命令删除
redis-cli –cluster call localhost:6379 keys “LOCATION*”| xargs -n1 redis-cli –cluster call localhost:6379 del
-n1将参数拆成每个一行,给后续命令
redis命令行查看中文不乱码
Redis 在使用命令行操作时,如果查看内容中包含中文,会显示 16 进制的字符串”\xe4\xb8\xad\xe5\x9b\xbd”
127.0.0.1:6379> set k1 '中国'
OK
127.0.0.1:6379> get k1
"\xe4\xb8\xad\xe5\x9b\xbd"
如果想要看到的中文不乱码,解决方案有两种:
一、使用echo
$ echo -e `redis-cli get k1`
中国
二、redis-cli 后面加上 –raw
$ redis-cli -h redis-host --raw
127.0.0.1:6379> get k1
中国
概述
Redis是一个完全开源免费(遵守BSD协议)的高性能key-value内存数据库,可以用作数据库、缓存和消息中间件。
redis是一个高性能的key-value非关系数据库,它可以存键(key)与5种不同类型的值(value)之间的映射(mapping),支持存储的value类型包括: String(字符串)、list(链表)、set(集合)、zset(有序集合)和hash(哈希)
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
这么说吧,redis配置文件中的每条命令,redis的每条操作指令,都可以衍生出一系列问题:
1、这个配置项/指令是干什么的?
2、内部实现机制是什么?
3、有哪些可选的参数?
4、分别是什么意思?
5、不同配置参数的优劣?在什么情况下使用?
随笔分类 - redis
http://www.cnblogs.com/xiaoxi/category/961351.html
redis面试总结
https://www.cnblogs.com/jiahaoJAVA/p/6244278.html
Redis为什么快?
官方提供的数据可以达到100000+的QPS(每秒内的查询次数)
Redis 快的主要原因是:
1、纯内存 I/O,相较于其他基于磁盘的 DB,Redis 的纯内存操作有着天然的性能优势。
2、数据结构简单,多数是 KV 操作,对数据操作也简单
3、I/O 多路复用,基于 epoll/select/kqueue 等 I/O 多路复用技术,实现高吞吐的网络 I/O。
4、单线程模型,单线程无法利用多核,但是从另一个层面来说则避免了不必要的上下文切换和竞争条件,不存在多线程导致的CPU切换,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。
单进程单线程
Redis 采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由 C 语言编写。官方提供的数据是可以达到 100000+ 的 qps. 这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差。
多路复用io模型epoll
多路 I/O 复用模型是利用select、poll、epoll可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
和Memcached不同,Redis并没有直接使用Libevent,而是自己完成了一个非常轻量级的对select、epoll、evport、kqueue这些通用的接口的实现。在不同的系统调用选用适合的接口,linux下默认是epoll。因为Libevent比较重更通用代码量也就很庞大,拥有很多Redis用不上的功能,Redis为了追求“轻巧”并且去除依赖,就选择自己去封装了一套。
Redis为什么是单线程的?
因为CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存或者网络带宽,既然单线程容易实现,而且CPU不会成为瓶颈,那就顺便成章的采用单线程的方案
如果万一CPU成为你的Redis瓶颈了,或者,你就是不想让服务器其他核闲置,那怎么办?
那也很简单,你多起几个Redis进程就好了。Redis是keyvalue数据库,又不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。redis-cluster可以帮你做的更好
redis进程里只有一个线程吗?
redis 的单线程指的是 核心网络模型是单线程的,并不是说整个 redis 进程中只有一个线程。
在 Redis 的 v6.0 版本正式引入多线程之前,其网络模型一直是单线程模式的;
Redis 在 v4.0 版本的时候就已经引入了的多线程来做一些异步操作,此举主要针对的是那些非常耗时的命令,通过将这些命令的执行进行异步化,避免阻塞单线程的事件循环。
Redis 6.0引入多线程网络模型
Redis 多线程网络模型全面揭秘
https://segmentfault.com/a/1190000039223696
问题
somaxconn is set to the lower value of 128
redis 日志中有 warning:
The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
原因:
redis 并发请求过高,超过默认 TCP 监听队列长度。
net.core.somaxconn 是 Linux 中的一个 kernel 参数,表示 socket 监听队列 backlog 的长度,即服务的最大并发 TCP 连接数。
什么是backlog呢?backlog就是socket的监听队列,当一个请求(request)尚未被处理或建立时,他会进入backlog。而socket server可以一次性处理backlog中的所有请求,处理后的请求不再位于监听队列中。当server处理请求较慢,以至于监听队列被填满后,新来的请求会被拒绝。
对于一个经常处理新连接的高负载 web 服务环境来说,默认的 128 太小了,大多数环境这个值建议增加到 1024 或者更多。
每一个处于监听(Listen)状态的端口,都有自己的监听队列,监听队列的长度与如下两方面有关:
1、somaxconn 参数.
2、使用该端口的程序中的listen()函数.
解决:
将 net.core.somaxconn 设置为 1024
1、临时生效,重启系统后失效
echo 1024 > /proc/sys/net/core/somaxconn
或
sysctl -w net.core.somaxconn=1024
2、永久生效
vim /etc/sysctl.conf
net.core.somaxconn=1024
sysctl -p
下一篇 jQuery
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: